
Hace tiempo que tenía ganas de hacer un artículo acerca de Unity Catalog profundizando en elementos como Metastore, Catalog, Schema,… Databricks a día de hoy es una de las piezas clave en el desarrollo de soluciones de Analítica Avanzada y justo por eso es por lo que este artículo cobra especial valor. Desde que hace unos días publiqué que en breve iba a escribir acerca de Unity Catalog, han sido muchos los compañeros que me han preguntado acerca del contenido y de la fecha de publicación. Eso demuestra que existe un claro interés por darle una vuelta y por otro lado, espero estar a la altura de las expectativas 😉
Comencemos pues!
Unity Catalog, como puedes leer por casi cualquier lado, se trata de un elemento de gobernanza de datos para el Lakehouse construido sobre Azure Databricks y Azure Data Lake Gen2. Hasta aquí sencillo. ¡Vamos a seguir profundizando!
Unity Catalog permite gestionar de manera centralizada los datos entre distintos Workspace sobre la misma cuenta de Databricks. Es decir, desde Unity Catalog puedes manejar los permisos de acceso a los datos de los distintos usuarios de las diferentes áreas de trabajo. Algo que en ocasiones originaba algún que otro problema, sobre todo cuando distintos equipos trabajaban sobre información que terminaba siendo redundante, lo que origina multitud de inconvenientes, además de costes de almacenamiento y movimiento de datos. Pongamos el claro ejemplo de un equipo de trabajo de Ingeniero de Datos, otro de Ciencia de Datos y uno de Analistas de Datos. La posibilidad de tener segregados los equipos en diferentes Workspace, donde para cada uno apliquen sus propias políticas y se gestionen mediante RBAC ayuda a mantener todo «ordenado». ¡Sigamos!
Una de las características que más me gusta de Unity Catalog es su modelo de objetos. Aquí aplica una jerarquía que ayuda a seguir manteniendo el orden dentro del Lakehouse. Las distintas capas en las que se ordenan son:
- Metastore: viene a ser el nivel superior de los metadatos y hace de contenedor principal. Aquí, cada Metastore se compone de tres niveles de espacios de nombre (catalog.schema.table) que ayudan a ordenar los datos.
- Catálogo: en este caso, nos enfrentamos al primer nivel dentro de la propia jerarquía. Nos permite organizar el resto de objetos de una manera óptima, sobre todo si lo comparamos con sistemas tradicionales de bases de datos SQL donde se limita a schema.table
- Esquema: esta capa viene a comportarse como si de la base de datos se tratara, y dentro de él se pueden almacenar tanto tablas, como vistas e incluso funciones.
- Tabla: es el nivel inferior de toda la jerarquía y nos permite almacenar tanto vistas, como funciones y tablas. Estas últimas pueden ser tanto internas, llamadas tablas administradas como externas. La diferencia suena clara, las primeras son las que están dentro del Data Lake configurado para nuestra cuenta de Azure Databricks, mientras que las externas son aquellas que se encuentran ubicadas en soluciones de almacenamiento distintas a nuestro Data Lake principal. Aquí podemos tener incluso elementos localizados en distintas nubes, como por ejemplo un S3 en AWS.
Hasta aquí la teoría, vamos a remangarnos y empezar a crear recursos en nuestra cuenta de Databricks.
Lo primero, es acceder a nuestra Manage Account desde el Databricks Workspace. Justo la primera ocasión que accedemos veremos algo como ésto.
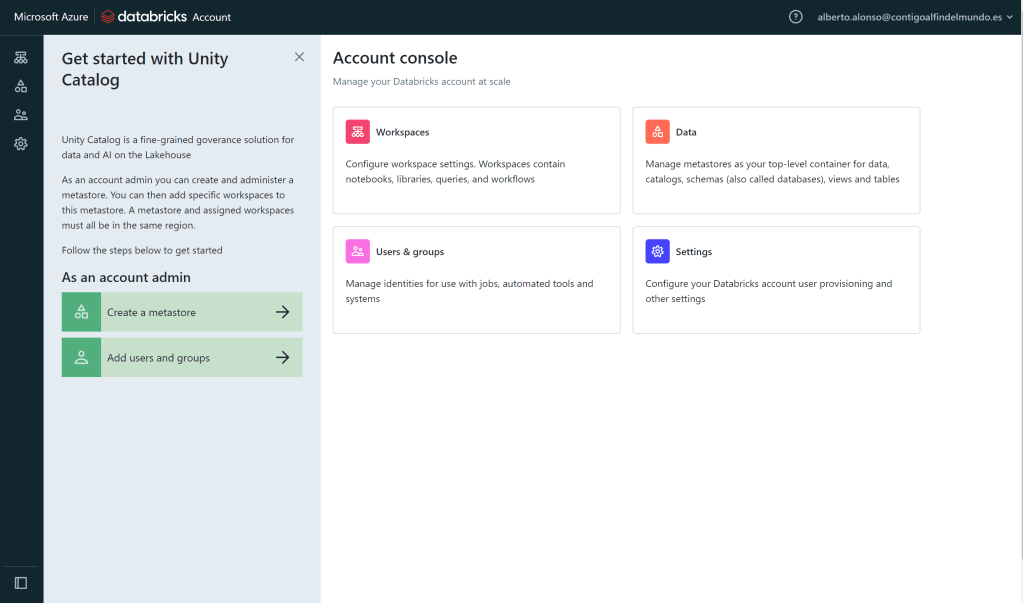
IMPORTANTE:
Si no eres Administrador Global en Azure, no podrás acceder aquí directamente, sino que deberás solicitar que te incluyan dentro del Azure Databricks Workspace como Administrador de cuenta. Para ello, el Administrador Global deberá acceder a la gestión de usuarios y habilitarte como tal. Puedes comprobar si eres o no Administrador Global en Azure Active Directory simplemente yendo hasta aquí.

Para añadir a un usuario el rol de Account Admin, sólo tienes que indicar al Administrador Global de acceda aquí, en el panel de gestión de usuarios, que seleccione o añada al nuevo usuario y que finalmente habilite a dicho usuario como Account Admin. ¡Sencillo!

Desde ese momento, el usuario podrá acceder a la página principal de gestión de Unity Catalog.
Metastore
Para crear un nuevo metastore, simplemente tenemos que pulsar sobre el icono de data en el panel izquierdo de nuestra página principal y acto seguido, pulsar sobre «create metastore«.
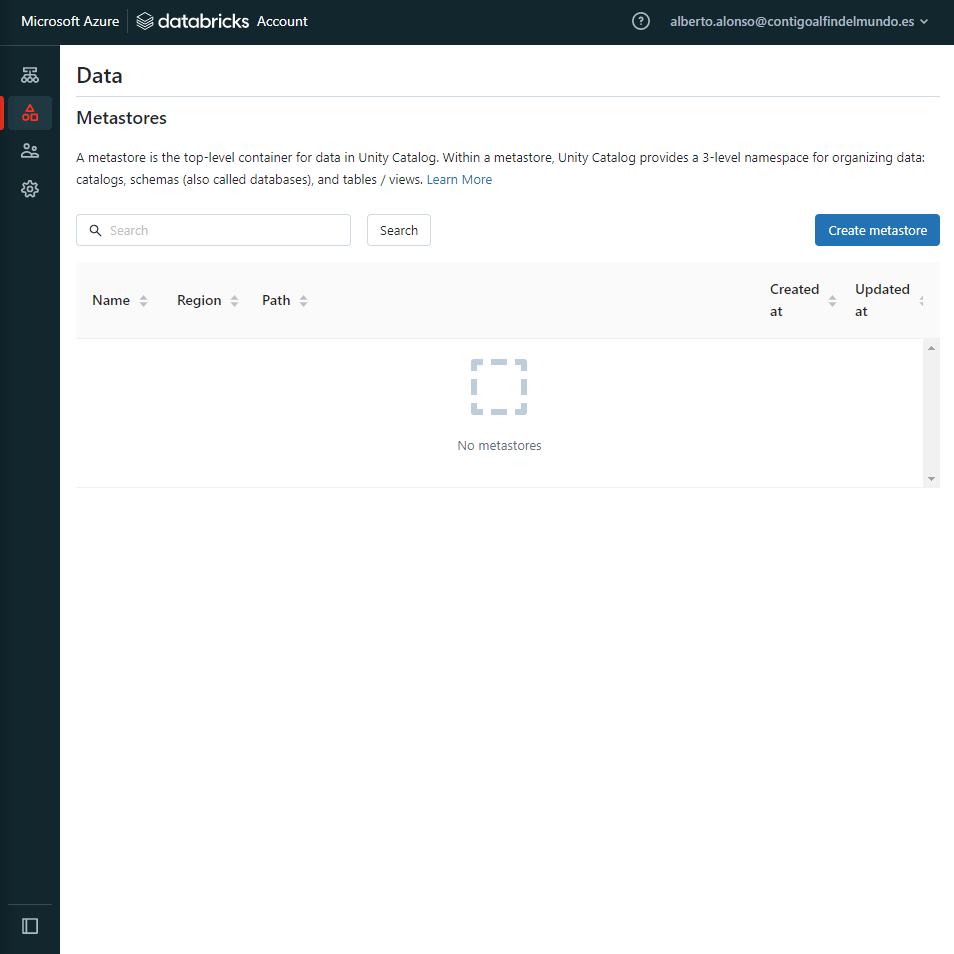
Una vez pulsado, debemos completar el formulario.
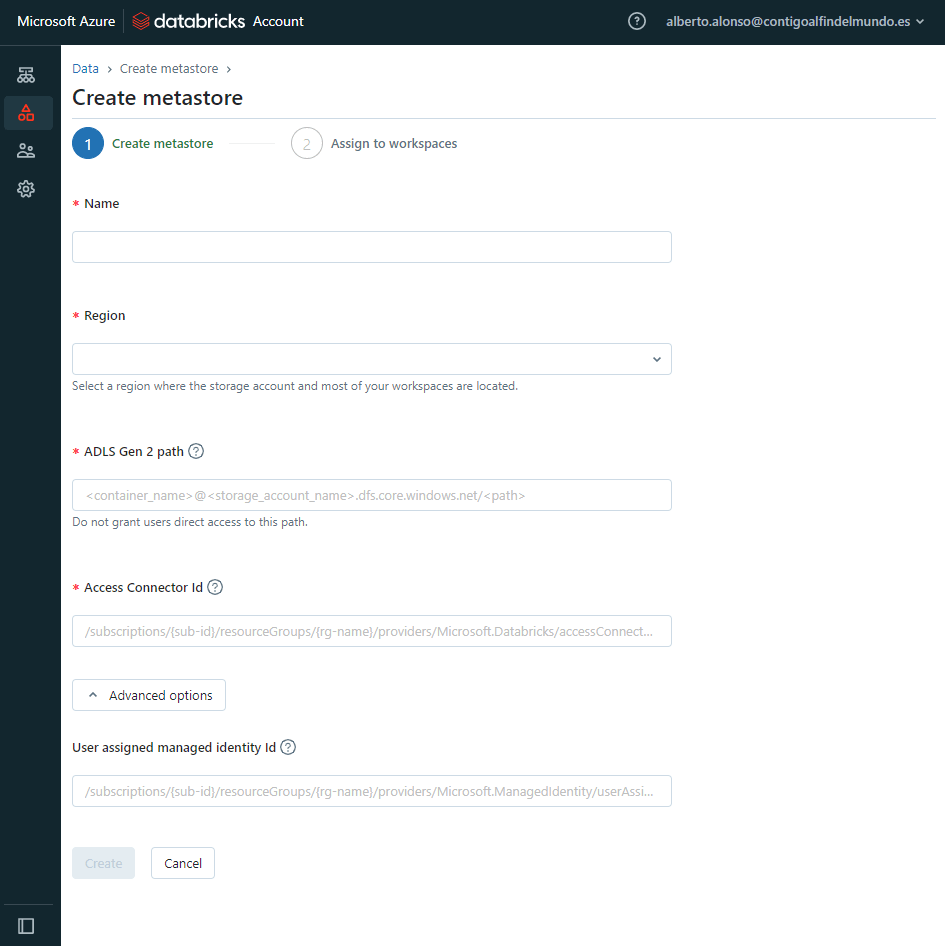
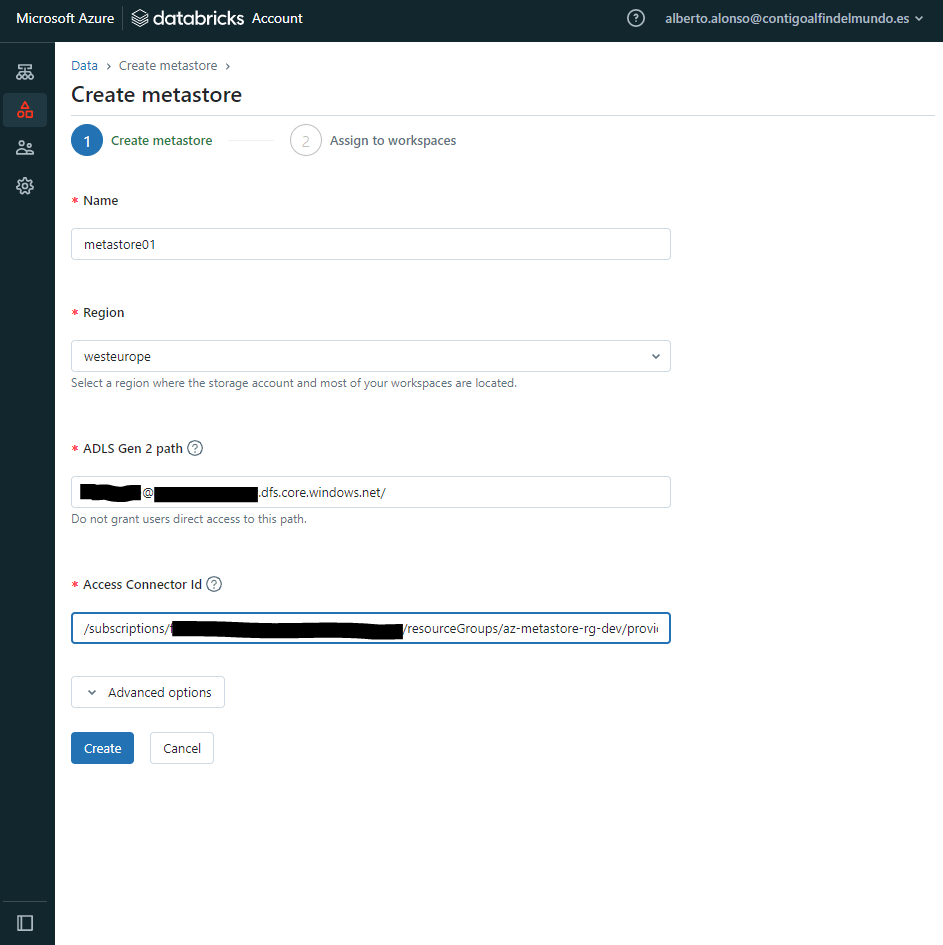
En nuestro caso el metastore tendrá los siguientes valores:
- Nombre: en este caso será metastore01,… original 😉
- Region: westeurope, ya que es condición obligatoria que tanto el metastore como el Databricks Workspace se encuentren dentro de la misma Región de Azure.
- ADLS Gen 2 path: aquí utilizamos la ruta del recién creado recurso en Azure, que es algo como: contenedor@storageaccountname.dfs.core.windows.net
- Access Connector Id: este es un recurso adicional que hay que desplegar en Azure. Lo describo un poco más abajo y sólo tenemos que pegar aquí el Resource ID
Una vez tenemos todo, sólo hay que pulsar sobre «create»
El siguiente paso es asignar el metastore al Databrick Workspace que desees
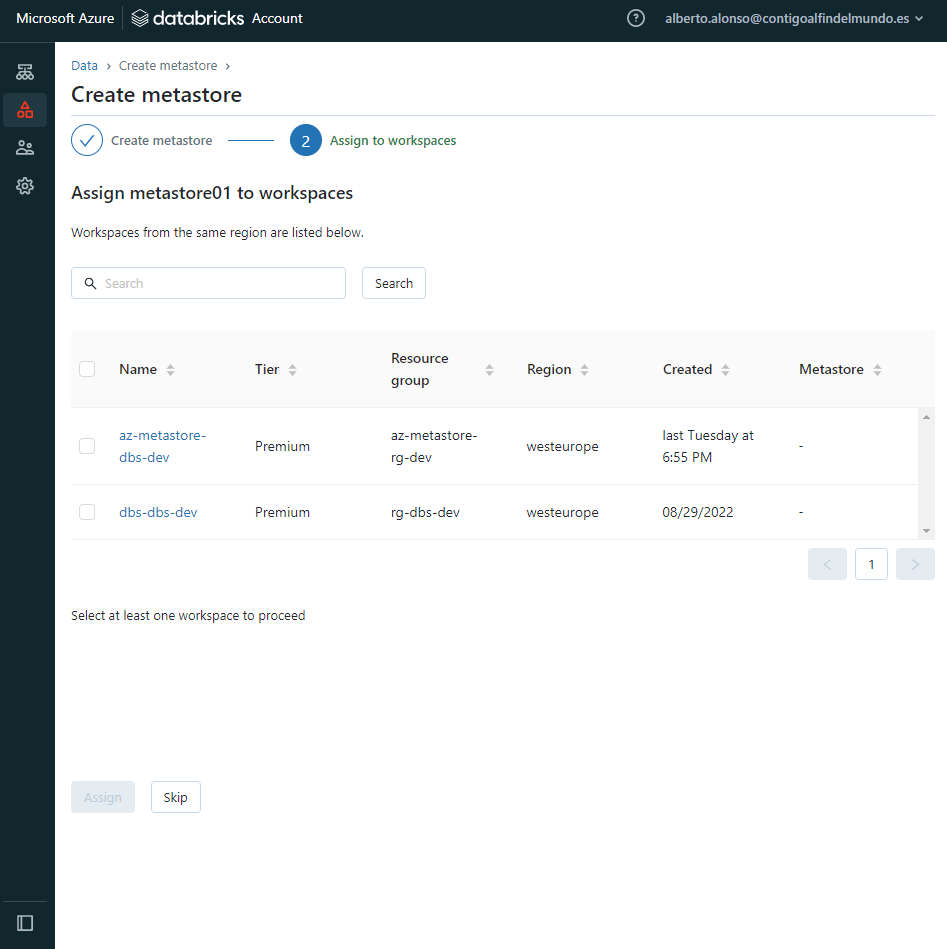
Y ya tendríamos el recién metastore creado disponible para comenzar a trabajar con nuestra área de trabajo. Como podemos leer en la imagen de abajo, esto nos permite hacer uso de múltiples ventajas.

Una vez completado el paso, si entramos en el apartado de Data de nuestro Databricks Workspace podremos ver nuestro metastore01 y podremos comenzar a crear el primer nivel de la jerarquía, el Catalog.
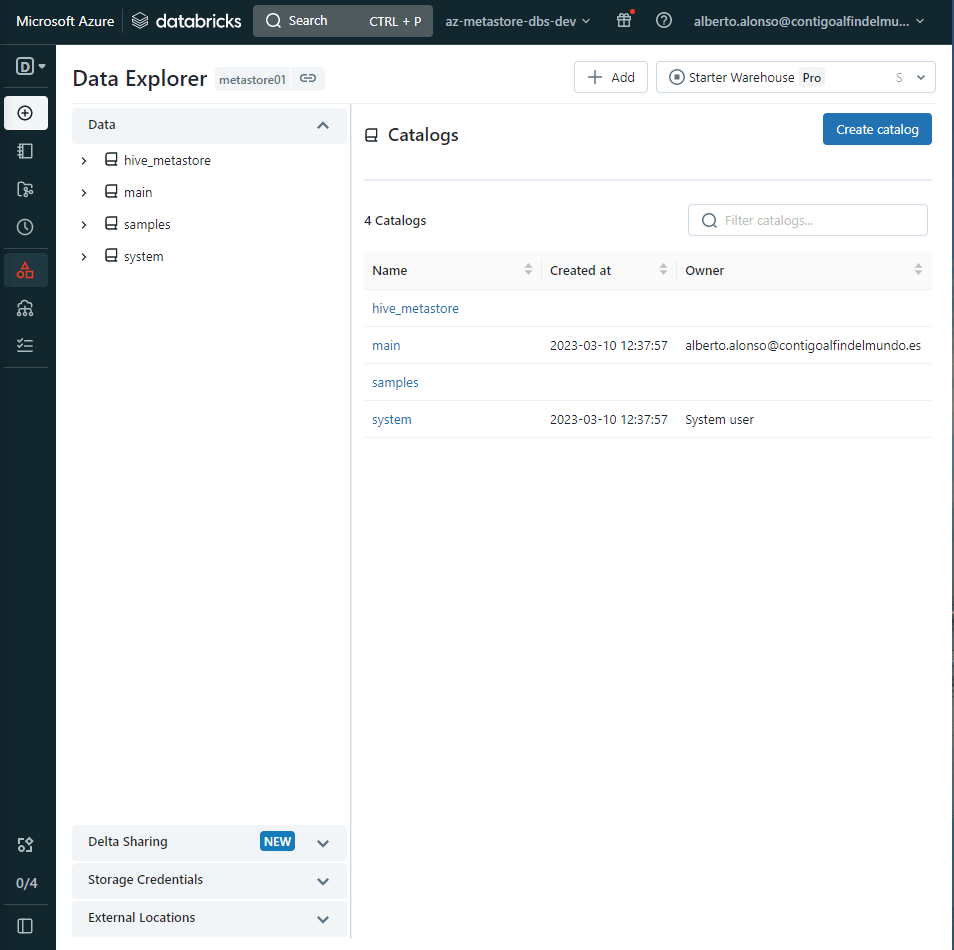
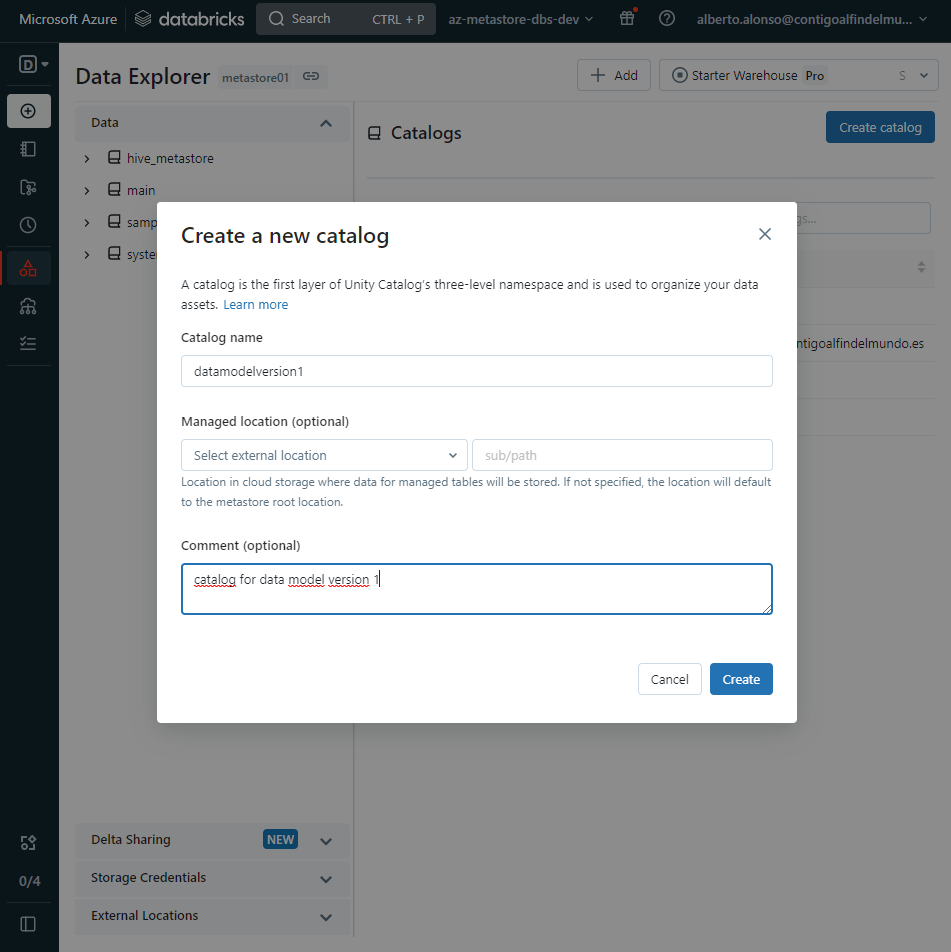
Tan sólo pulsando sobre «create catalog» accedemos al formulario de creación y tras rellenar los principales campos, pulsamos «create» y ya lo veríamos disponible en nuestro apartado de Data del área de trabajo de Databricks
Tras la creación del Catalog, podemos continuar con el Schema. Que vendría a ser el segundo nivel de la jerarquía.
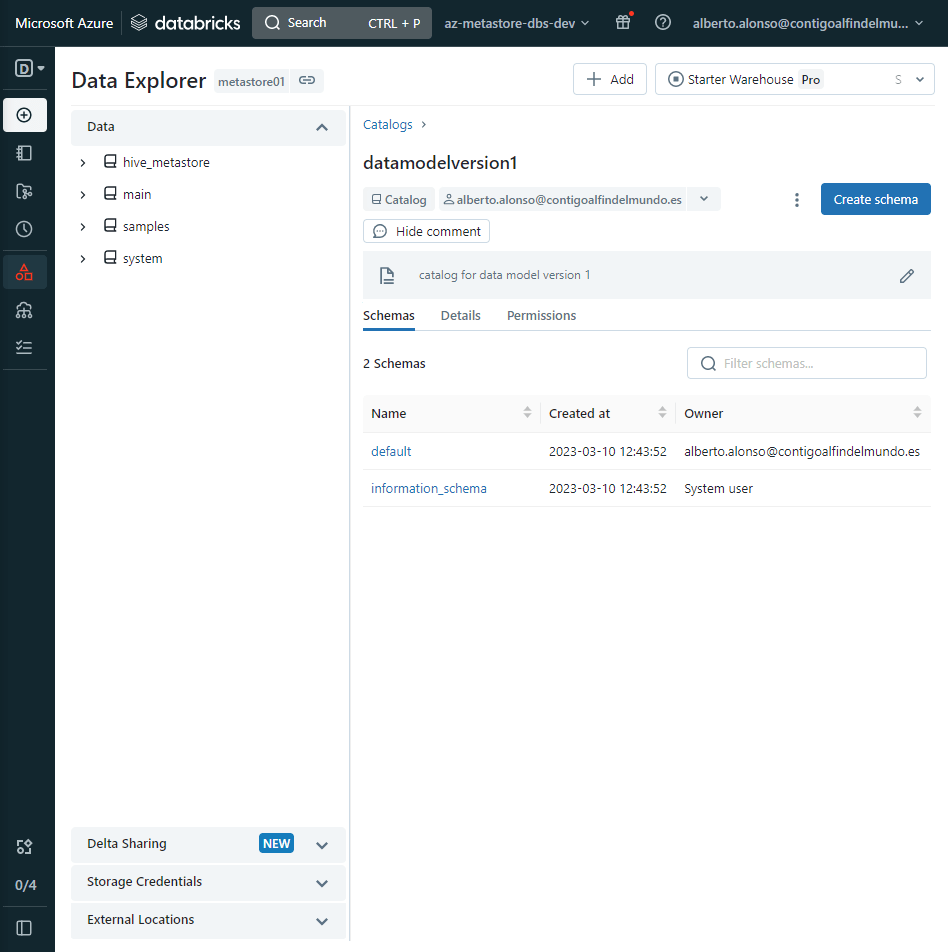
Como antes, simplemente con pulsar sobre el botón, en este caso el de «create schema», nos abre el formulario de creación y completamos.
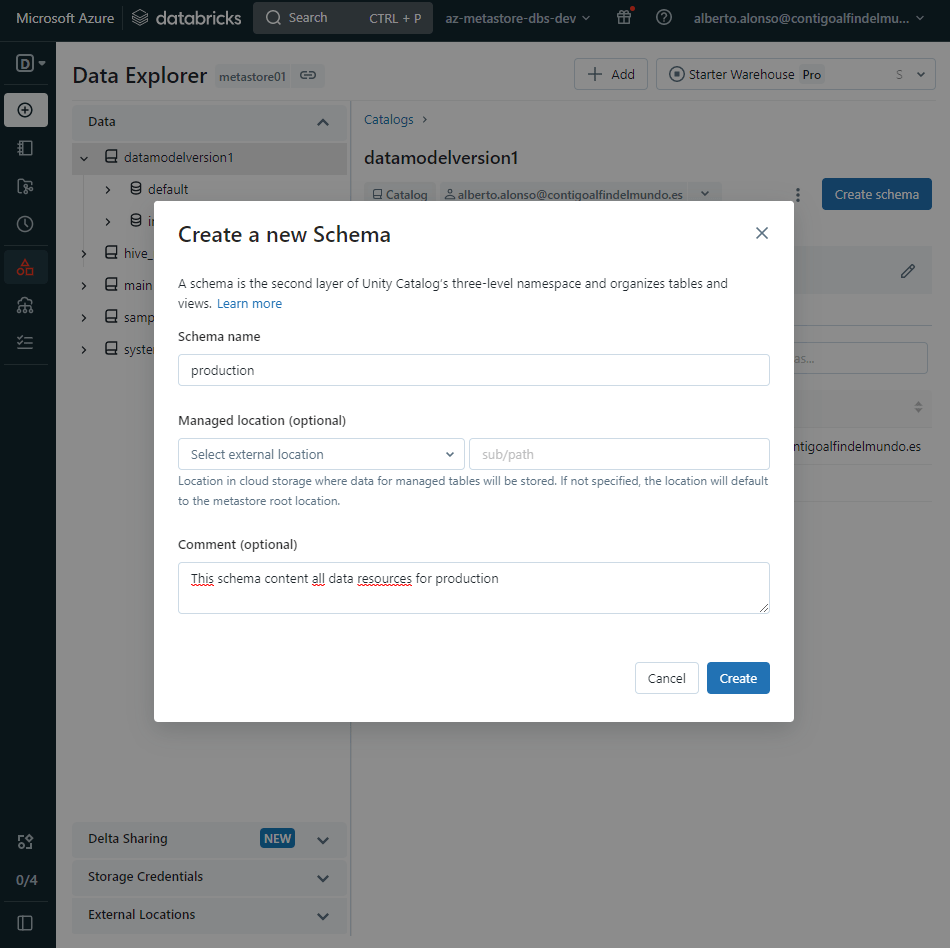
Ya una vez hemos configurado las dos principales capas de la jerarquía de nombres de nuestro metastore, podemos comenzar con la creación del resto de objetos del tercer nivel. Recordar que aquí tenemos tablas, vistas y funciones.
En esta primera entrada, hemos completado la creación de un metastore. Para ello, hemos tenido que desplegar y configurar un conjunto de recursos adicionales. Es por ello, que justo a continuación describo el proceso que he completado para ser capaz de configurar con éxito este ejercicio.
Databricks Access Connector
Lo primero es crear el nuevo servicio dentro de mi grupo de recursos de Azure. Para ello, filtro por Databricks y pulso «crear«
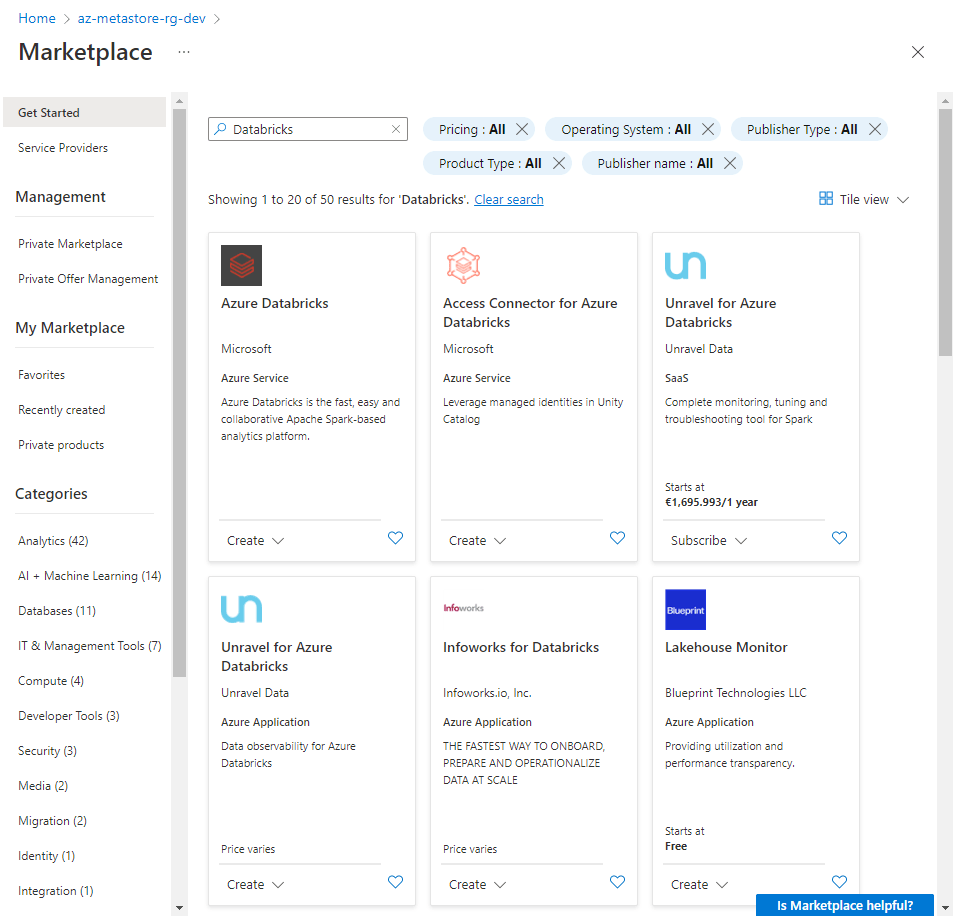
Incluyo los campos necesarios para configurarle, y sigo avanzando
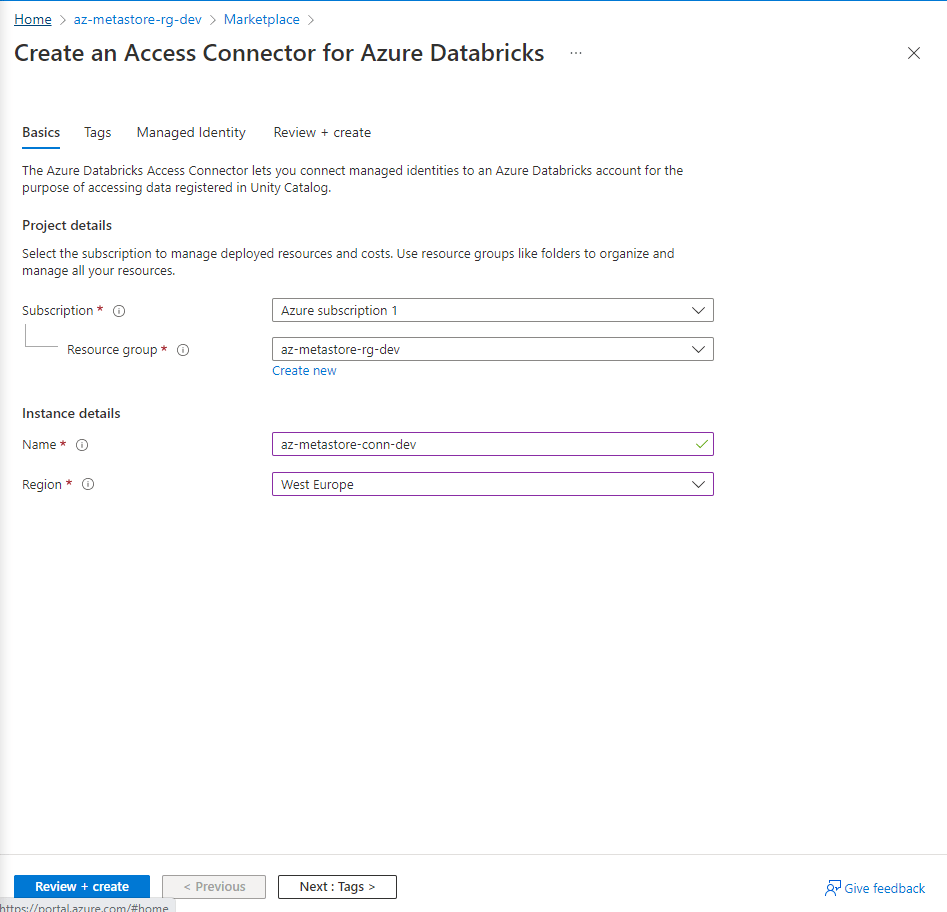
Mantengo habilitada la opción de Managed Identity para poder acceder a otros recursos de Azure y casi que ya lo tenemos

Una vez creado, nos interesa el valor del Resource ID, que deberemos incluir en nuestro formulario de creación del metastore.
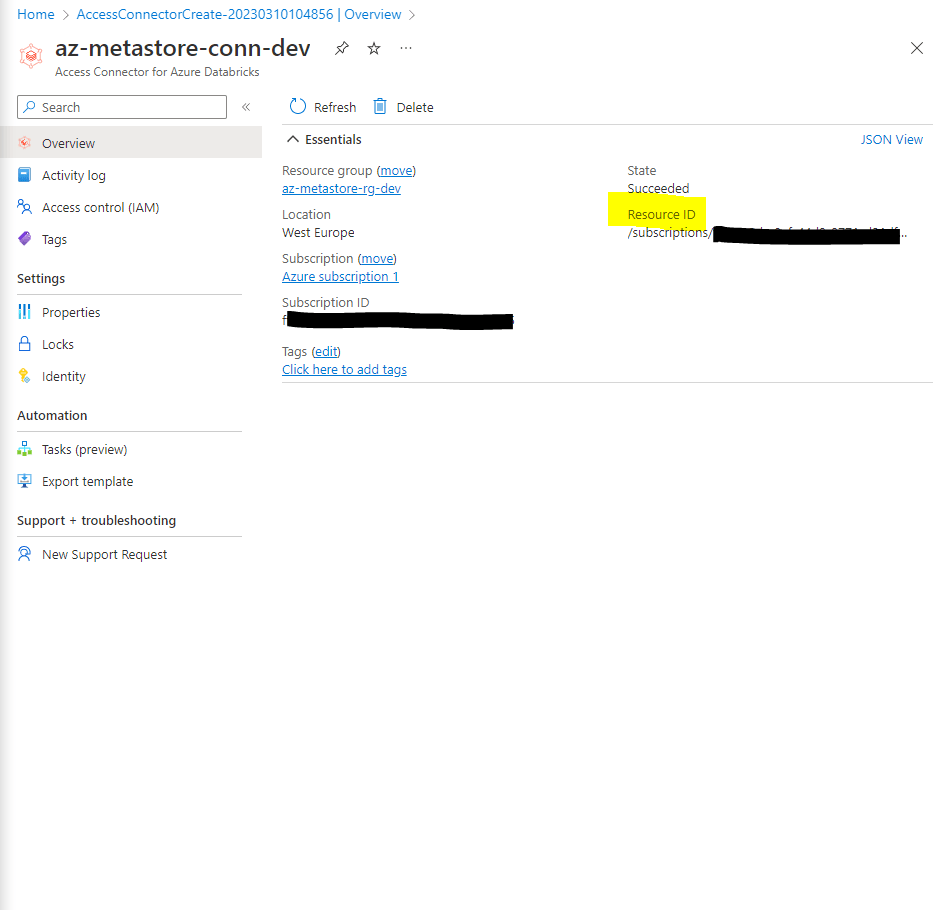
También es importante asignar al permisos de acceso al Azure Data Lake Gen2 a nuestro Databricks Connector. Recuerda que debe ser Storage Blob Data Contributor
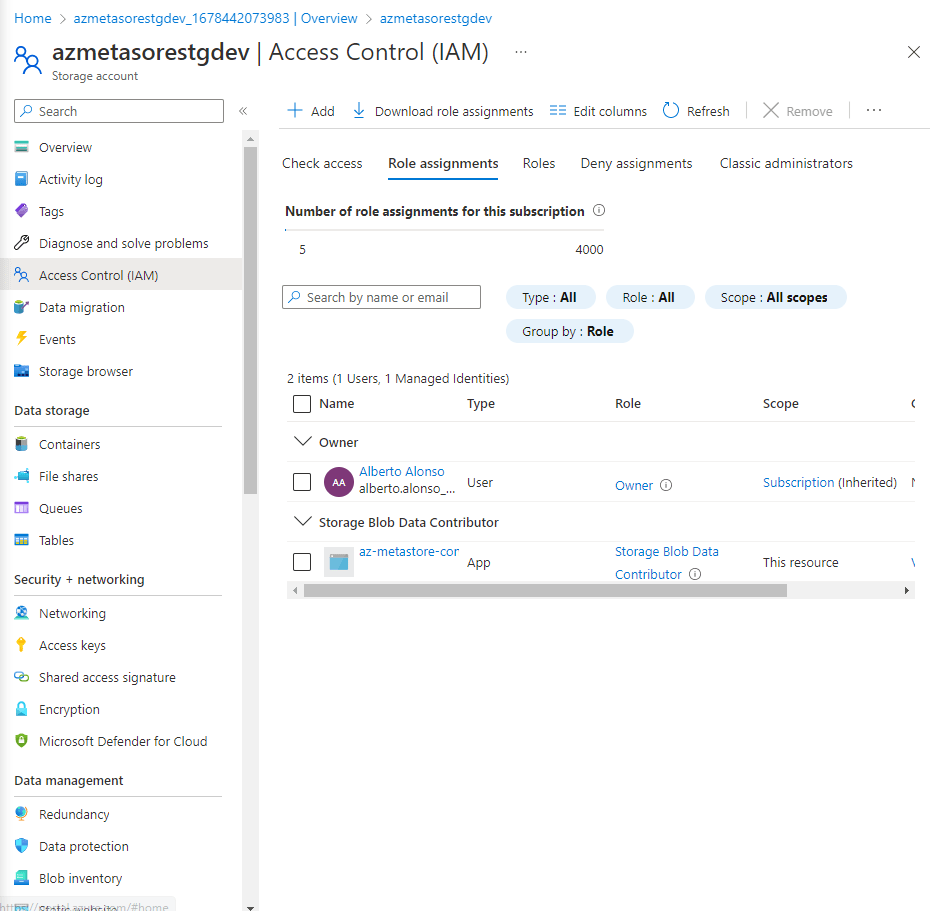
Foto de portada gracias a Andrea Piacquadio: https://www.pexels.com/es-es/foto/hombre-senior-positivo-en-anteojos-mostrando-los-pulgares-hacia-arriba-y-mirando-a-la-camara-3824771/
