A día de hoy, nos encontramos ante un entorno empresarial cambiante. Un gran número de compañías se plantean adaptar sus modelos de analítica, con el objetivo de aprovechar las actuales capacidades tecnológicas, que entre otras son:
- Fuerte incremento en la adopción del cloud.
- Actualizaciones constantes de las herramientas tecnológicas por parte de los proveedores de servicios en la nube.
- Disminución del coste de soluciones de almacenamiento.
- Incremento en la capacidad computacional a través del procesamiento distribuido.
- La carrera por la adopción de soluciones de Inteligencia Artificial.
- Obtener valor del análisis en tiempo real de los datos.
- La incorporación de fuentes externas a la propia organización. Principalmente se trata de fuentes de datos semi o no estructurados, como redes sociales, sensores, open data.
Todos estos factores, y algún otro son los que están continuamente “obligando” a adaptar el escenario de la Analítica en las organizaciones.

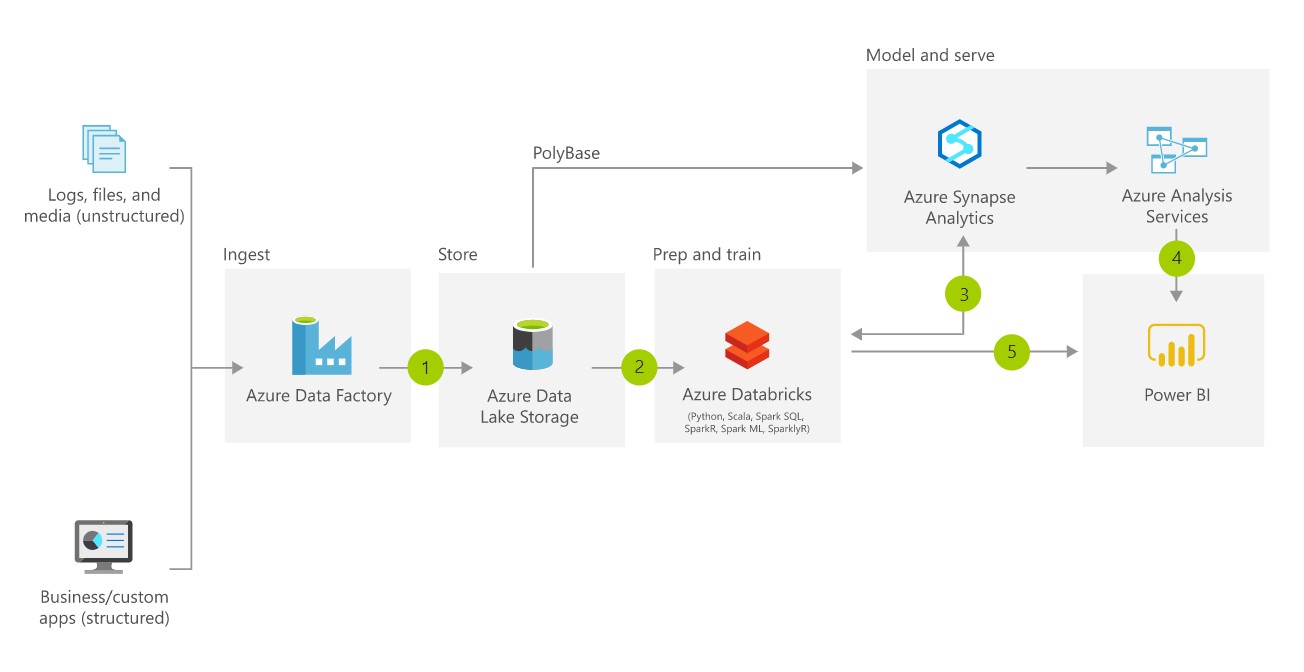
Fuente: Microsoft. “Almacenamiento de datos moderno”. Febrero, 2020. https://azure.microsoft.com/es-es/solutions/architecture/modern-data-warehouse/
Como podemos observar en la imagen superior, se trata de una arquitectura moderna, propuesta por Microsoft, para el almacenamiento de datos. Y junto con muchos otros ejemplos de compañías como Databricks, AWS, IBM, vemos que su enfoque con respecto al tradicional ETL cambia. Se pasa del Extraer, Transformar y Cargar al Extraer, Cargar y Transformar, lo que viene a ser ELT.

Si bien ya he avanzado uno de los puntos clave de esta evolución, no quiero dejar de ahondar en él. Como vemos, esta nueva aproximación al proceso de manejo del dato tiene su origen en la extracción de información estructura (como antiguamente), pero además no estructurada. Que junto con el crecimiento en volumen, pasamos de MB o GB a TB, generaría auténticos cuellos de botella en las herramientas ETL a la hora de su transformación para “dejar en bonito” los datos.
Si a ésto le añadimos la rebaja de la factura por almacenamiento de datos en la nube, como puede ser Azure Data Lake Gen2 y la capacidad computacional de Azure Databricks, mediante el procesamiento distribuido de Spark. El cambio de estrategia es clara, ELT sale vencedora en este caso.
No quiero dejar pasar la oportunidad de añadir una opinión personal hacia el almacenamiento masivo de datos, indicando que es una muy buena práctica. Se tenga capacidad analítica o no en ese mismo momento, me explico. En muchas ocasiones, cuando las empresas quieren realizar un acercamiento al Machine Learning, a través de una PoC, nos encontramos con que no disponen de suficientes datos históricos como para realizar una aproximación con ciertas “garantías”. Por eso, recomiendo el almacenamiento de la información. Siempre es mejor pecar de exceso que de defecto, al menos en este caso.
Así pues, regresando a lo que nos ocupa. Una vez tienes toda la información en tu cuenta de almacenamiento, los equipos de Analistas de Datos, Científicos de Datos, Inteligencia de Negocio, ya pensarán en las métricas, patrones, procesos, proyectos, conocimiento y beneficios que se podrán generar a partir de ahí. Ese será el momento de concretar las transformaciones de los datos, para construir las mejores soluciones de Analítica Avanzada para la compañía.
Es por todo esto, que el tradicional ETL está dejando paso al ELT.
CONCLUSIÓN
El ELT no ha venido a sustituir al ETL, ambas son opciones de trabajo que existen en el mundo de la analítica. La elección de una u otra dependerá del modelo o arquitectura de datos que tu compañía tenga implementada. Si bien, en los casos en los que la velocidad de ingesta sea determinante, la estructura de las fuentes sean diversas y sus volúmenes sean muy grandes, sin duda la elección de ELT es la adecuada.
