
En Analítica Avanzada, la posibilidad de cubrir el análisis de datos en real time es más demandada. En el caso de la nube de Microsoft, tenemos varias herramientas que nos permiten trabajar en esa dirección. Hoy vamos a hacer un breve resumen al respecto, y comentaré algunas capacidades adicionales que normalmente no son tratadas como la importancia de definir el tipo de Windowing, la posibilidad de construirte tus propias UDF (User Define Functions), así como el uso de las funciones por defecto que existen para manejar la detección de anomalías.
En Azure, las actuales opciones para trabajar con datos en real time son:
- HDInsight with Spark Streaming
- HDInsight with Storm
- Apache Spark in Azure Databricks
- WebJobs
- Azure Functions
- Azure Stream Analytics
Centrándonos en Stream Analytics, vemos que dentro de este paraguas podemos trabajar con distintos componentes, tanto como fuentes de datos, como partes de almacenamiento o visualización, además de la conexión con Azure ML en caso de querer progresar en el uso de modelos predictivos. Comentar que como Reference Data existen dos posibilidades, conectar con Blob Storage o Azure SQL Database.
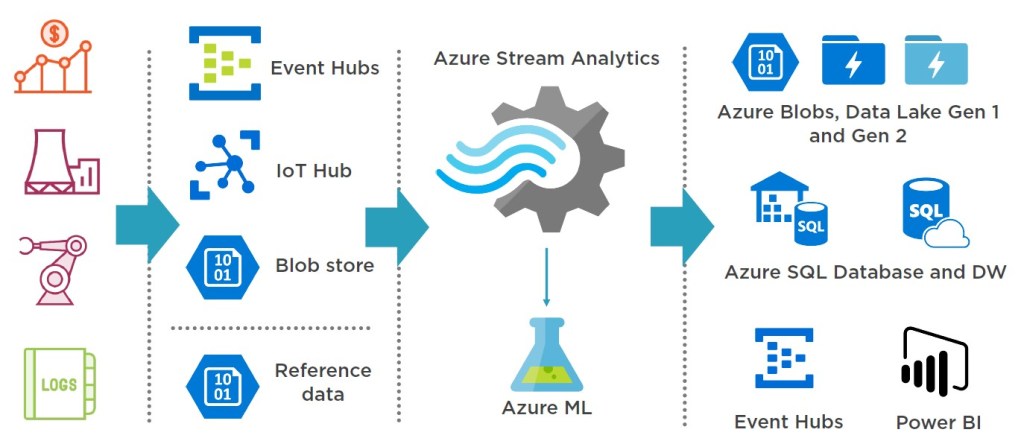
Pero avancemos, como previamente he comentado, en este artículo hablaremos del Windowing y en sucesivas entradas profundizaremos en UDF y detección de anomalías. Estas opciones nos permiten cubrir aspecto que no suelen comentarse en las presentaciones de Azure Stream Analytics.
¿Qué es Windowing? Es la posibilidad que brinda Azure para cubrir el requerimiento de crear subconjuntos de datos dentro del Stream en función del timestamp, con el propósito de realizar operaciones tipo COUNT, AVG, etc.
Como tipos de Windowing tenemos cuatro diferentes posibilidades:
- Tumbling Window
- Hopping Window
- Sliding Window
- Session Window
- Snapshot Window
Veamos las cada uno de los casos para comprender mejor el mejor caso de uso para cada uno.
Tumbling Window
En este caso, se crea un subconjunto mediante la función TumblingWindow (‘time unit’, integer). Ejemplo:
SELECT COUNT (*) FROM Input GROUP BY TumblingWindow (second, 10)
En el diagrama vemos cómo quedaría el resultado de la query utilizando este primer tipo de Window. Crearíamos un subconjunto del Stream cada 10 segundos, contaríamos el número de eventos en los distintos subconjuntos devolviendo el resultado. Aquí no hay solapamiento, con lo que un evento sólo pertenece a una ventana. Sencillo: 3, 1, 2
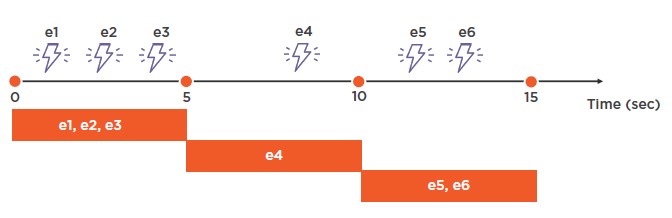
En este caso, un ejemplo sería obtener los promedios de temperatura para un conjunto de datos que cubriera cinco segundos.
Hopping Window
En el segundo caso, el subconjunto que se crea se fundamenta en los dos parámetros que se pasan a la función. Estos son el tamaño de la ventana y en segundo caso, el valor de inicio de cada subconjunto, con lo que un mismo evento puede encontrarse en varias ventanas.
SELECT COUNT (*) FROM Input GROUP BY HoppingWindow (second, 10, 5)
En el diagrama vemos cómo quedaría el resultado de la query. Sencillo: 3, 3, 2, 2, 2
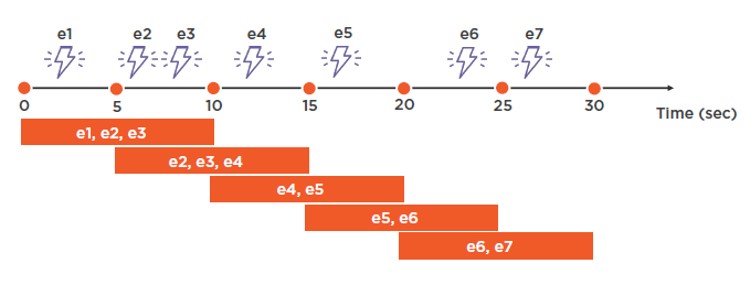
En este caso, un ejemplo sería obtener el número de eventos ocurridos en los últimos 10 segundos, cuando los nuevos recuentos deben aparecer cada 5 segundos. De ahí que se solapen las ventanas.
NOTA: ¿Qué sucedería si pasáramos (Second, 10, 10)? Pues que obtendríamos la misma ventana que utilizando la función previa de Tumbling Window.
Sliding Window
En el caso de Sliding Window, a la función le pasamos el valor del tamaño de la ventana y la unidad de tiempo, como a la primera opción. Sin embargo, la diferencia entre ellas es que el tamaño de la ventana se cubre a partir del evento ocurrido.
SELECT COUNT (*) FROM Input GROUP BY SlidingWindow (second, 10)
Es decir, va de atrás para adelante, por lo que al menos tiene un evento y dichos eventos pueden pertenecer a más de una ventana. Resultado: 2, 2, 2, 1
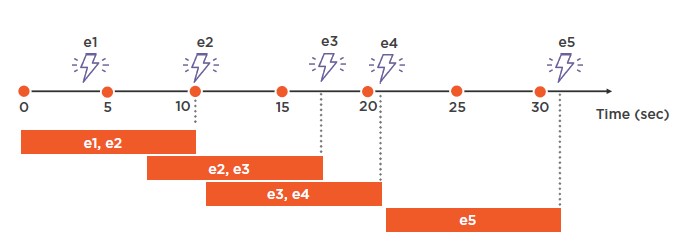
Este sería un claro ejemplo en caso de que quisiéramos obtener el resultado total de eventos ocurridos en los últimos 10 segundos.
Session Window
En este caso, los valores que se pasan a la función son los de la unidad de medida, así como el tiempo de espera y el valor del tamaño máximo de la ventana.
SELECT COUNT (*) FROM Input GROUP BY SessionWindow (second, 5, 10)
Es decir, en este caso al aparecer un evento comienza a contar los segundos de espera. Si antes de que venza llega un nuevo evento, la cuenta se inicia nuevamente. En el ejemplo vemos que tras el segundo evento, se superan los 5 segundos de espera con lo que se cierra la ventana. Como vemos este cierre se produce en el valor de 12, esto es porque las ventanas se calculan en función del valor máximo de tiempo fijado. Es decir, en el valor 10, 20, 30, etc. Es por ello que cuando se cierra la ventana del segundo conjunto, ésta lo hace al alcanzar el valor de 30. Resultado: 2, 5
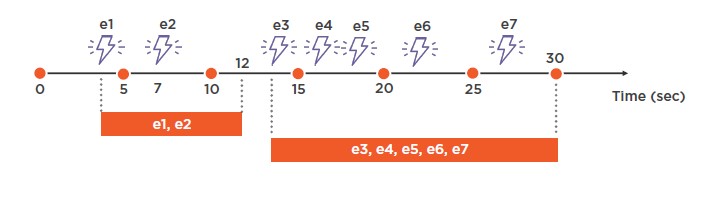
Este sería un claro ejemplo en caso de que quisiéramos obtener el resultado total de eventos ocurridos con una diferencia de 5 segundos entre ellos.
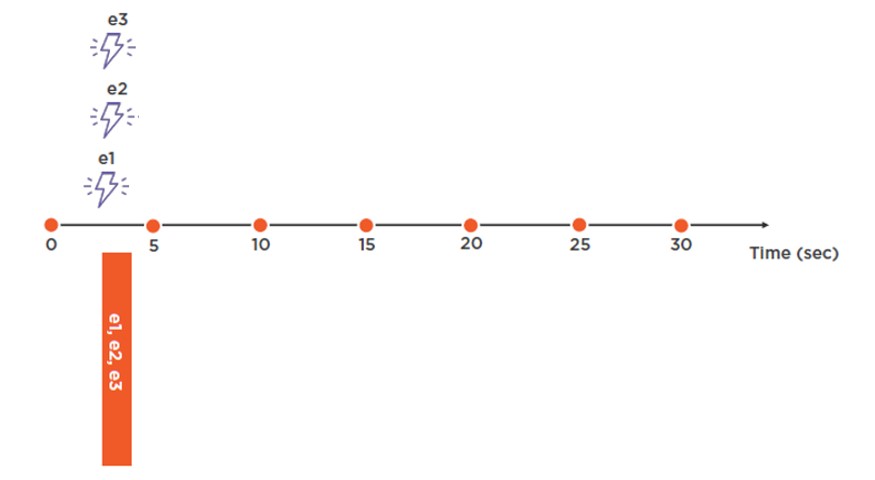
Snapshot Window
En este último caso, se obtiene el total de eventos que sucede en la misma marca de tiempo. Para ellos se utiliza la función System.Timestamp ()
SELECT COUNT (*) FROM Input GROUP BY System.Timestamp ()
Este caso es el más sencillo de entender, puesto que realiza una típica agrupación.
CONCLUSIÓN
La posibilidad de configurar exactamente los valores de tus ventanas, así como definir el comportamiento que deseas utilizar para obtener el resultado esperado, nos permite manejar de un mejor modo el potencial de Azure Stream Analytics. Nos permite conocer mejor las herramientas con las que trabajamos en Analítica Avanzada y proveer al usuario del correcto enfoque para sus desarrollos.
Más información en:
https://docs.microsoft.com/es-es/azure/stream-analytics/stream-analytics-window-functions
Fuentes:
Reza Salehi, “Building Streaming Data Pipelines in Microsoft Azure”. June 2020.

puedes comentar sobre las particiones e indices con azure synapse por favor
Me gustaMe gusta
Buenos días huellajuvenil,
Estoy preparando una entrada sobre Databricks acerca del particionado, clusterización y técnicas de optimización de queries sobre Delta Tables, que puede servirte de «aproximación» a Synapse. Con Azure Synapse, estoy esperando a hacer un review en detalle de Microsoft Fabric que espero no se demore demasiado y ahí seguro que hablo acerca de ello.
Un saludo,
Alberto
Me gustaMe gusta