
Azure Data Factory es un muy buen orquestador como ya venimos viendo desde hace tiempo. Son muchas las entradas donde a lo largo de estos años he hablado acerca de él, por lo que hoy vamos a sumar un nuevo artículo al conjunto.
En esta ocasión quiero describir cómo configurar la actividad de copia, siendo la fuente una Delta Table sobre Databricks. Para ello, crearemos un primer pipeline de ADF e incluiremos ese tipo de actividad.
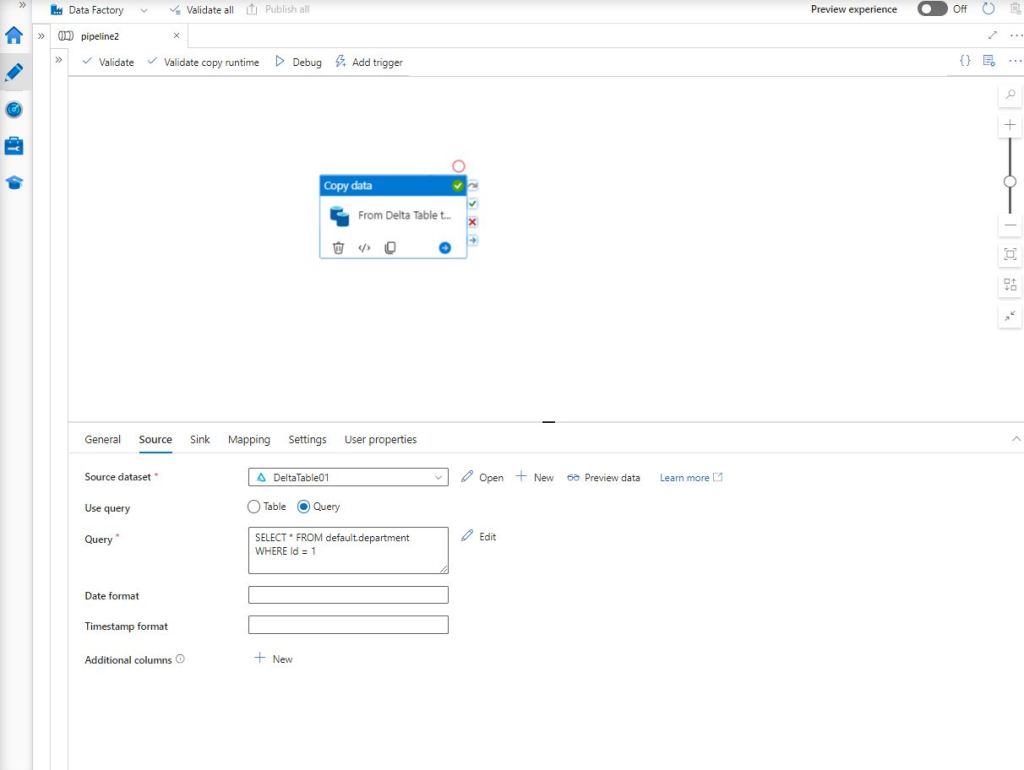
Como puedes ver en la imagen de arriba, se ha customizado la extracción mediante la incorporación de una Query. En este caso, nos filtra por el Id y recoge tan sólo aquel registro con valor igual a 1.
Delta Table Linked Service
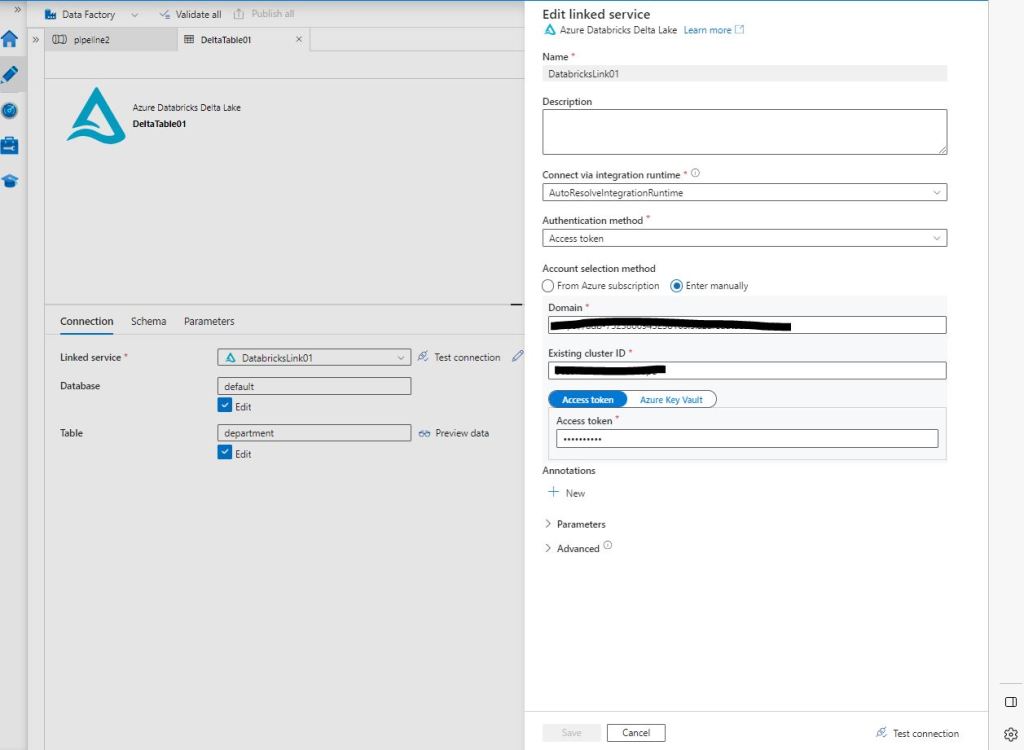
Para configurar correctamente el Linked Service se hace uso de un Token que podrás obtener desde la zona de User Settings, como puedes observar abajo.

Una vez solicitado, recuerda gestionarlo correctamente en herramientas del tipo Keeper o Keepass e incorpora el mismo durante el proceso de configuración para completar el proceso de conexión.
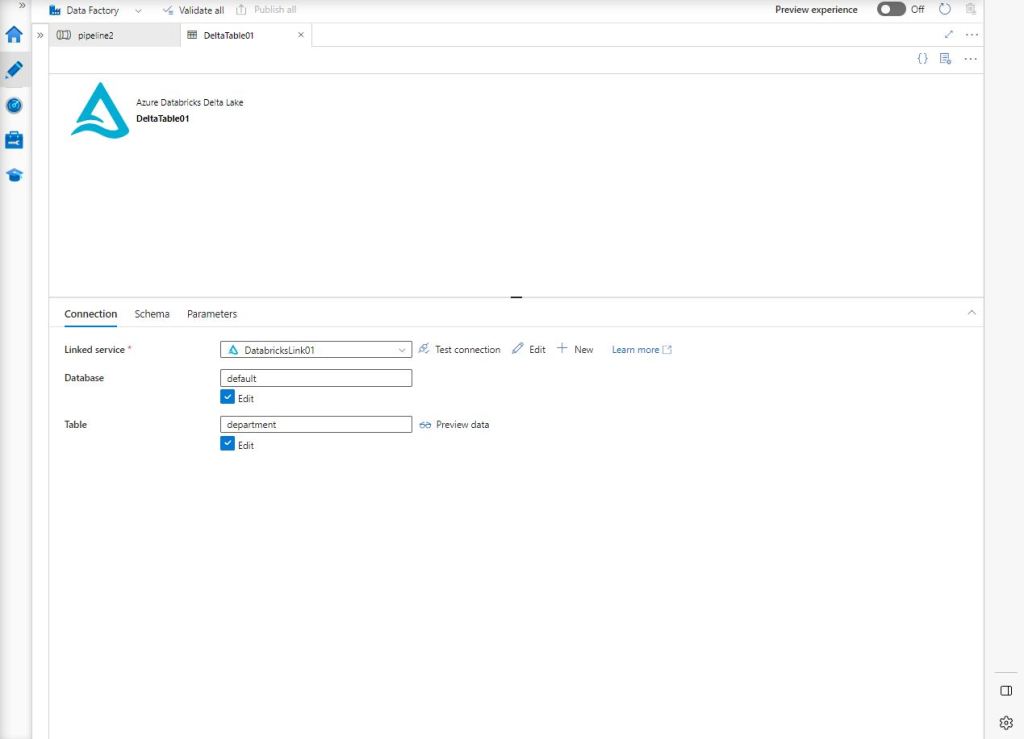
Al terminar de configurar el Linked Service, ahora continuamos con la propia del Dataset, que no es más que seleccionar la Database y la Tabla como podemos ver abajo.
Staging Area
En este ejemplo, no voy a configurar el destino, puesto que se trata de una simple conexión a Azure SQL Database, ni tampoco la pestaña de Mapping que simplemente nos sirve para realizar el match entre fuente y destino y en más de una ocasión lo hemos detallado. Así que salto directamente a la pestaña Settings, que es donde hay que habilitar la zona de staging. Esta zona es imprescindible para realizar el movimiento de datos entre Delta Table y la Azure SQL Database.
Esto significa que hay que habilitar un nuevo Linked Service, esta ocasión para el Blob Storage donde se almacenarán los recursos necesarios para el buen funcionamiento del proceso de ADF.

También es necesario aplicar una configuración avanzada sobre clúster de Databricks que empleemos en la ejecución de la actividad de copia en Data Factory. Como vemos en la imagen de abajo hay que incluir varias líneas de código para habilitar autoCompact, optimizeWrite y además incluir la Storage Account Key.
spark.databricks.delta.autoCompact.enabled true
spark.databricks.delta.optimizeWrite.enabled true
spark.hadoop.fs.azure.account.key.<>.blob.core.windows.net <account-key> o {{secrets/<scope-name>/<secret-name>}}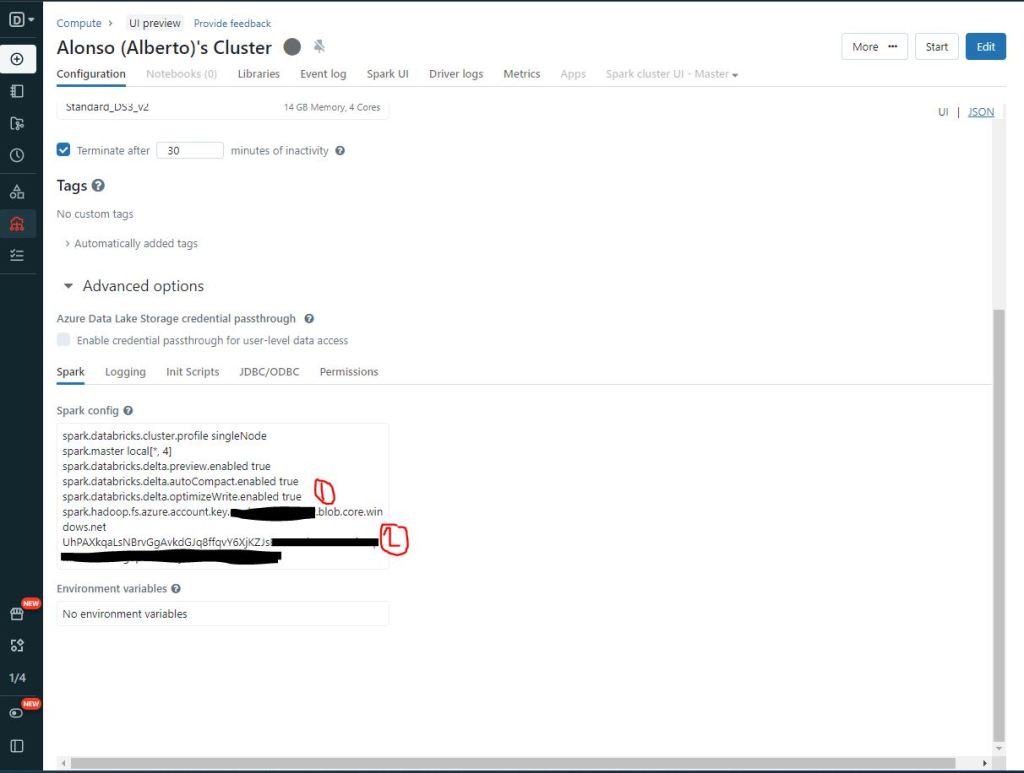
Aquí dejo una imagen para que recordéis dónde localizar la Key de la Storage Account.
NOTA: es una buena práctica incluir dicha Key en un secreto y referenciar dicho secreto con el correspondiente Secret Scope del Workspace. No lo habilito por defecto por ser un sencillo ejemplo que no cubre este punto.
Una vez hemos configurado toda la actividad de Data Factory ya sólo queda insertar los registros en la Delta Table mediante un simple Databricks Notebook SQL

Y tras la correcta finalización del pipeline, comprobamos que al realizar una sentencia SELECT obtendremos el registro de valor Id = 1

CONCLUSIÓN
Este ejemplo de hoy te ayuda a saber configurar movimientos de datos entre las capas del Lakehouse: Bronze, Silver, Golden de Databricks a otros posibles componentes del ecosistema empresarial de datos como podría ser una Azure SQL Database donde explotar ciertos set de datos. Esto cada vez es más habitual, sobre todo si tenemos en cuenta posibles característica nativas como Dynamic Data Masking, Always Encrypted,… y así cumplir con las buenas prácticas de seguridad de datos de tu organización.
Gracias por ayudarnos a seguir difundiendo y creando comunidad alrededor del dato 😉
Más en nuestro Canal de Youtube: https://www.youtube.com/channel/UCiBVg6eUS7erxKaopWNlK6A
y el Grupo de Meetup: https://www.meetup.com/es-ES/encuentros-en-la-tercera-fase/
Foto de portada gracias a Taryn Elliott: https://www.pexels.com/es-es/foto/hombre-arboles-hierba-parque-4652250/
