
En este documento realizaré un step by step que describa cómo montar Azure Data Lake Storage Gen2 en Azure Databricks de cara a componer una arquitectura Lakehouse, empecemos.
Partimos de un ADLS previamente creado, para ello recordar que, es básico seleccionar la opción de jerarquía. Por lo que, una vez desplegado el recurso, lo siguiente es ir al Active Directory de Azure y registrar nuestra app. Para ello pulsamos sobre ‘app registration’
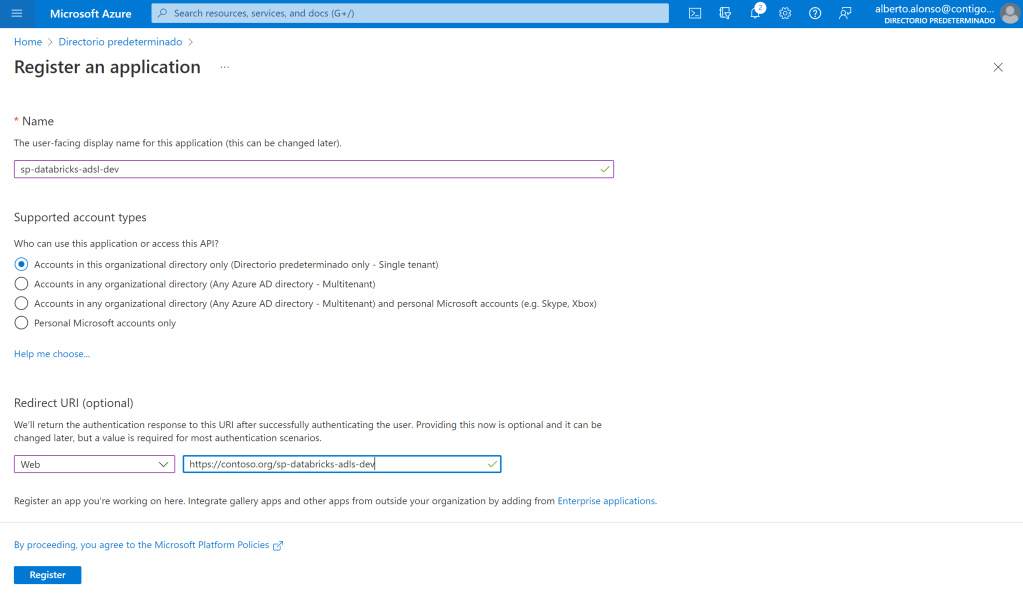
A continuación pulsamos sobre el ‘+’ y comenzamos con el registro de la aplicación. Es tan sencillo como indicar el nombre y opcionalmente incluir un valor en el apartado de Redirect URI. En mi caso opté por nuestro siempre fiel Contoso 😉
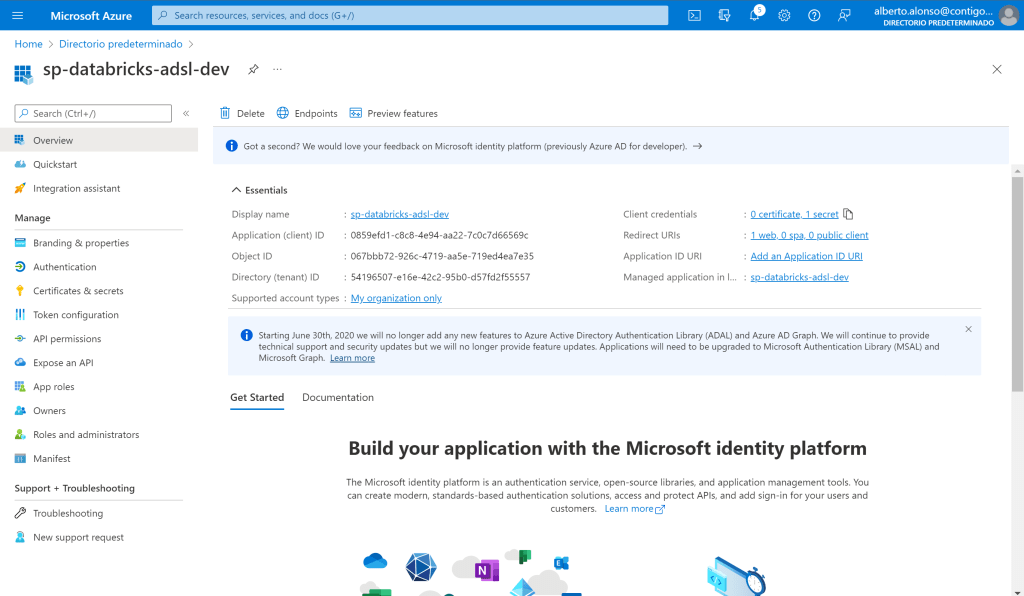
Una vez completado el proceso de registro debemos saber que, hay tres valores que debemos recordar, pues nos servirán para vincular nuestro Azure Databricks Workspace con nuestro Azure Data Lake Storage Gen2. Estos son:
- Client ID
- Client Secret, ojo recordar que no es el Secret ID, sino el Value ID
- Tenant Id
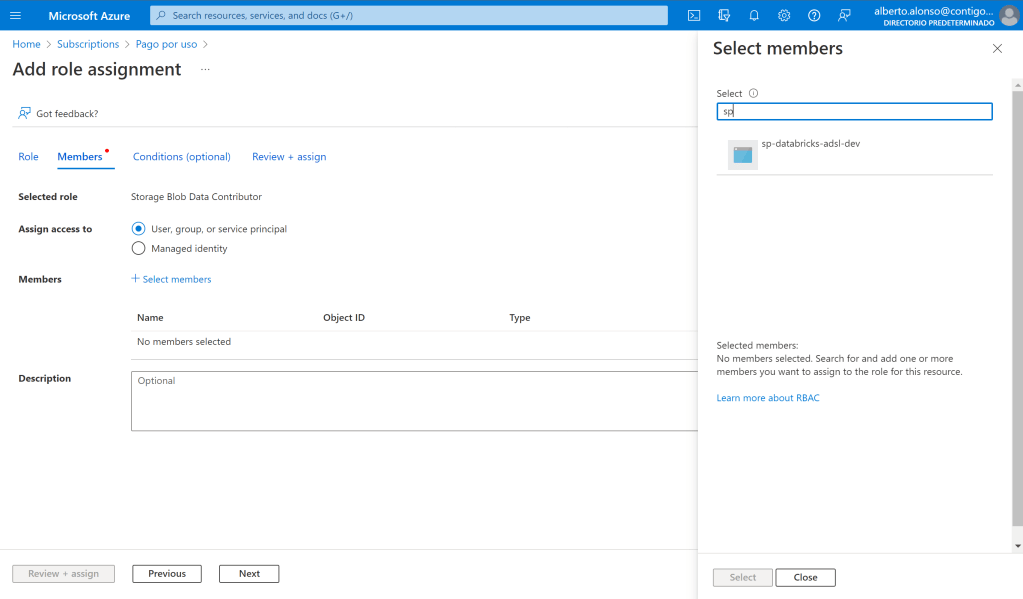
Ahora debemos asignar un rol de Storage Blob Data Contributor a la aplicación, para ello únicamente debemos localizar el nombre de nuestra recién creada aplicación en el buscador y añadirlo.
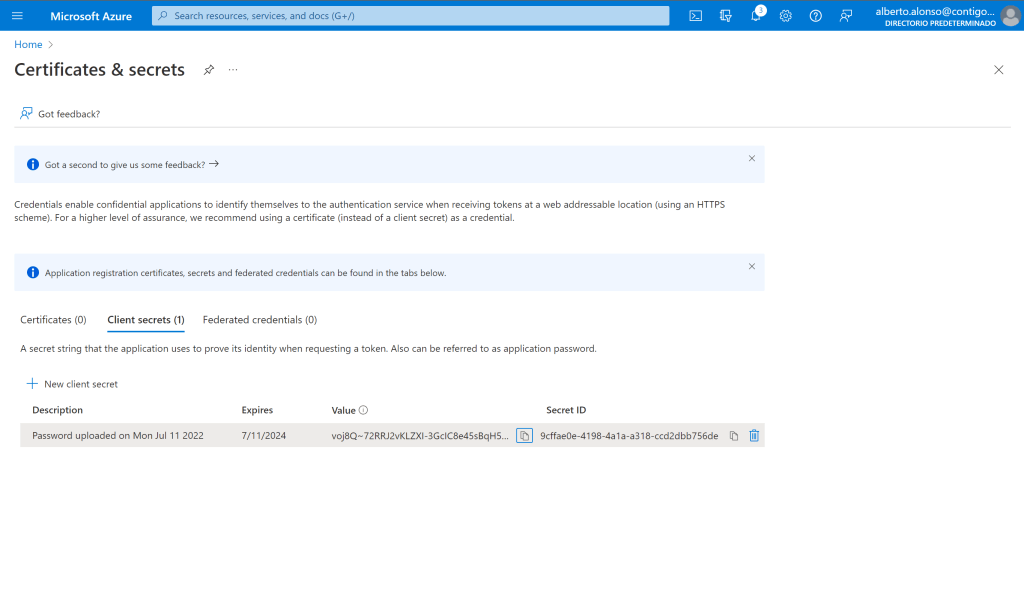
Aquí vemos los valores de Client ID y Tenant ID, para el Secret ID debemos crearlo pulsando sobre Client credentials y seguir los pasos.
Una vez completados, dispondremos de nuestro secreto para autenticar la aplicación recién registrada.
NOTA:
He creado el secreto con validez máxima de dos años, pero se puede customizar al gusto del usuario.
El siguiente paso es el de crear nuestro Azure Databricks Workspace y desde ahí ejecutar el código Python que nos permite vincular el Azure Data Lake Storage. Al final del proceso recibiremos la salida True, lo que significa que hemos completado el proceso satisfactoriamente.
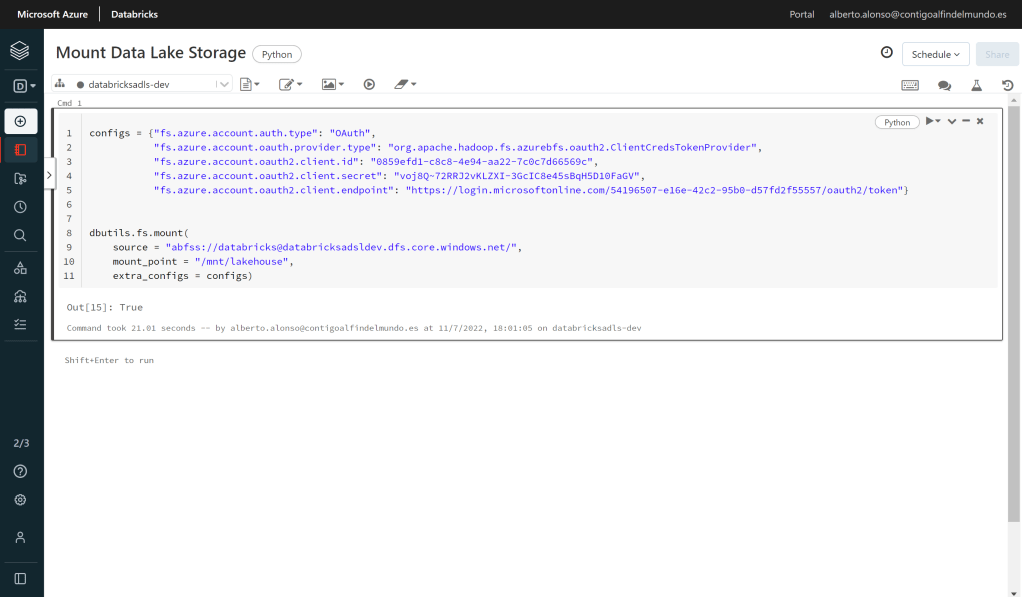
configs = {"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": <Client ID>,
"fs.azure.account.oauth2.client.secret": <Secret Value ID>,
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/<Tenant ID>/oauth2/token"}
dbutils.fs.mount(
source = "abfss://<Container Name>@<Account Name>.dfs.core.windows.net/",
mount_point = "/mnt/lakehouse",
extra_configs = configs)En próximas entregas comenzaremos a trabajar subiendo ficheros .parquet y algún .csv a la capa Raw y creando las capas Silver y Gold utilizando el formato .delta para comprobar las múltiples ventajas que presenta.
Foto de portada gracias a Antonio Borriello: https://www.pexels.com/es-es/foto/foto-de-macbook-air-en-una-mesa-junto-a-la-planta-de-la-casa-y-el-marco-de-imagen-1297611/
