
Durante años, muchas plataformas de datos han prometido ser abiertas. Sin embargo, en la práctica, la apertura solía quedarse en la capacidad de importar o exportar datos, no en compartirlos de forma nativa, gobernada y segura entre distintos motores y soluciones. La madurez de Apache Iceberg como formato abierto y su adopción por plataformas comoSigue leyendo «Interoperabilidad real con Apache Iceberg en Snowflake: arquitectura abierta, gobierno del dato y colaboración con Microsoft Fabric (parte 1)»
Archivo de etiqueta: #Data
Microsoft Fabric IQ: el punto de inflexión en la experiencia de negocio con los datos
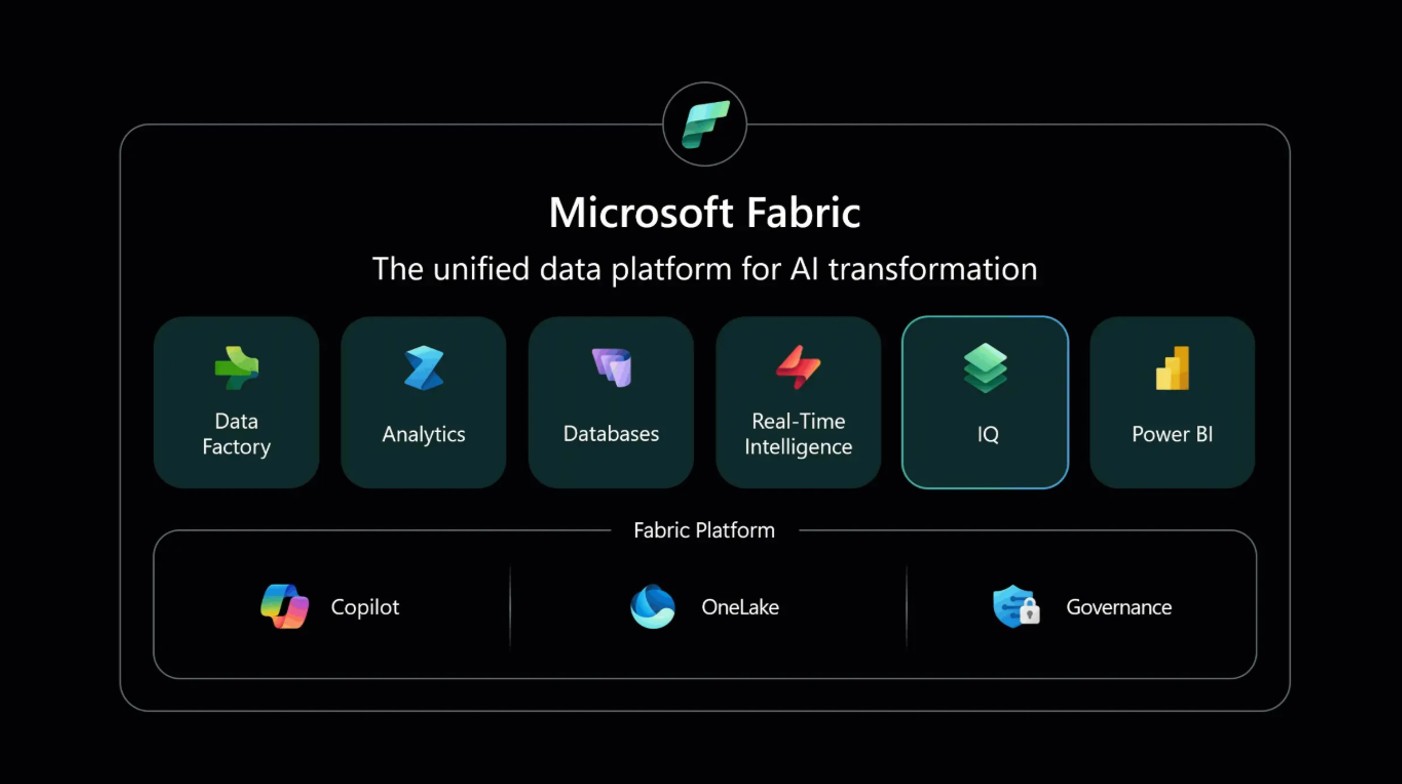
Cada evento es una oportunidad única para reconectar con la comunidad, compartir aprendizajes y entender hacia dónde evoluciona el ecosistema de datos y analítica de Microsoft. Este año, el mensaje es claro: estamos entrando en una nueva etapa en la que los datos dejan de ser únicamente un activo técnico para convertirse en el lenguajeSigue leyendo «Microsoft Fabric IQ: el punto de inflexión en la experiencia de negocio con los datos»
Mi primer pipeline de ingesta de datos con Openflow en SPCS de Snowflake

La ingeniería de datos está viviendo una transformación profunda. Con la irrupción de la IA generativa, los modelos multimodales y la explosión de datos no estructurados, las empresas necesitan plataformas que permitan ingestar, mover y transformar datos con la misma elasticidad con la que escalan sus casos de IA. En este contexto, Snowflake dió unSigue leyendo «Mi primer pipeline de ingesta de datos con Openflow en SPCS de Snowflake»
Microsoft Fabric IQ o la importancia del contexto

Desde hace tiempo vengo siguiendo las publicaciones de Gartner donde destacan la importancia de la metadata en todos los proyectos en los que se plantee el desarrollo de Agentes de IA expertos en el Dominio de Datos. Pues justamente resulta que el equipo de producto de Microsoft Fabric ha debido estar mirando las mismas fuentes,Sigue leyendo «Microsoft Fabric IQ o la importancia del contexto»
¡Arranca la FabCon de Viena!

En septiembre comienza el curso, y lo hace por todo lo alto. Esta semana destaco dos eventos muy interesantes, el primero sin duda es el que se celebra en Viena, la FabCon y el segundo algo más cerquita, en Madrid, FarmaForum. Si el año pasado la FabCon se celebró en Estocolmo, en esta ocasión seSigue leyendo «¡Arranca la FabCon de Viena!»
De Promoted a Certified y tiro porque me toca

Uno de los aspectos que a mi modo de ver resultan interesante para avanzar en la calidad de los datos, es la gestión de los mismos a través del Endorsement. Pero, ¿qué significa esta palabra? Pues viene a traducirse como respaldo y se refiere a la manera en que los equipos pueden identificar contenido ySigue leyendo «De Promoted a Certified y tiro porque me toca»
Fabric In a Day con Microsoft y Snowflake, ‘Better Together’

Ayer martes 26 de Noviembre tuve la suerte de participar como ponente en el evento que Plain Concepts organizó en el salón de actos de la Torre Picasso. En la fotografía de abajo se ve a Alex Hidalgo abriendo el evento. En dicho evento hablé acerca de Microsoft Fabric, principalmente de sus puntos fuertes ySigue leyendo «Fabric In a Day con Microsoft y Snowflake, ‘Better Together’»
Uniendo capacidades para hacer un traje a medida con Apache XTable y UniForm

Desde hace mucho tiempo se percibe que, los sistemas de ficheros basados en formatos open source como Apache Iceberg, Apache Hudi y Delta Lake, se han convertido en el standard con el que construir tu Data Warehouse corporativo. Al menos asi lo indica el 74% de los CIO a nivel global en recientes encuestas. ConSigue leyendo «Uniendo capacidades para hacer un traje a medida con Apache XTable y UniForm»
La evolución del data sharing

Van pasando los años y las organizaciones, al igual que nos sucede a nosotros, maduran con el tiempo. Normalmente, con la madurez adquirimos mayor de mayor autoconocimiento, autocontrol, nos volvemos algo más reflexivos. En definitiva, nos acercamos a lo que los antiguos llaman la «sabiduría». Pues algo similar les ocurre a las organizaciones. Muchas deSigue leyendo «La evolución del data sharing»
Pon siempre un identificador en tus tablas y a ser posible que sea PK

Que el propietario del dominio tenga cada vez más peso en las nuevas aproximaciones de datos como Data Mesh está genial porque él mismo comienza a «sufrir», en primera persona, los errores de diseño de sus tablas transaccionales al moverse del operacional a la analítica. Suele suceder que, en la mayor parte de soluciones deSigue leyendo «Pon siempre un identificador en tus tablas y a ser posible que sea PK»
