
Hace un par de semanas tuve la oportunidad de participar en una reunión con un grupo de profesionales del dato de esos que llevamos unos pocos años en la «lucha» y me resultó especialmente gratificante escuchar su convencimiento acerca de la necesidad de aplicar las buenas prácticas de desarrollo en los proyectos de datos. En concreto, estuvimos discutiendo sobre la mejor de las aproximaciones para el despliegue de su solución de datos basada en Snowflake de cara a cubrir los entornos de desarrollo, test y producción.
La edad media de la mesa estaba entre los 40 y 50 años, es decir, todos habían recorrido buena parte del camino que transita entre el Business Intelligence tradicional hasta aproximaciones más actuales como Modern Data Warehouse, Lakehouse o incluso se habían atrevido con el abstracto paradigma socio-técnico Data Mesh. Pero lo relevante no es eso, lo realmente potente es que se hablaban de conceptos como el particionado, el sistema de capas (y sí, también sirve staging,… no todos somos olímpicos para quedarnos solo en la arquitectura de medallas), el modelado e incluso se mencionó la creación de Data Marts, tanto con aproximaciones departamentales como de caso de uso. Del mismo modo, se comentó la tendencia actual hacia productos de datos, dominios de gobierno e incluso nos atrevimos a «teorizar» sobre los Data Contracts.
Con respecto al despliegue de Snowflake en entornos empresariales, existen tres enfoques clave:
Cuenta Única: donde todas las bases de datos se gestionan dentro de una sola cuenta de Snowflake.
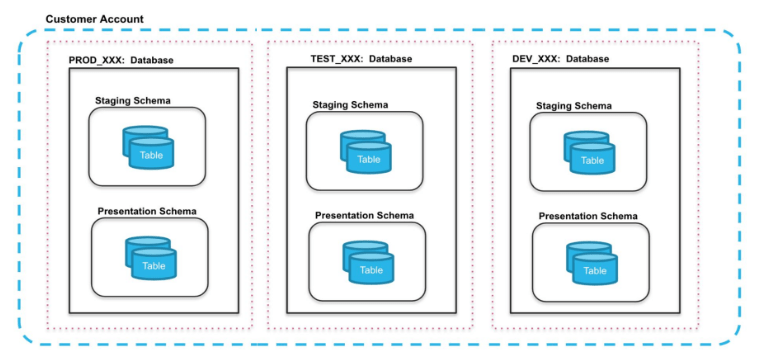
Como ventajas comentar que:
- Permiten una gestión ágil de datos gracias a la funcionalidad de clonación
- La administración es centralizada, tanto para los usuarios como para los objetos.
Como desventajas comentar que:
- No permite diferentes ediciones de Snowflake por entorno
- Puede no cumplir requisitos de auditoría, ya que los datos de producción y no producción se mezclan.
- Existe riesgo portencial de privacidad por la facilidad de mover datos entre entornos.
Cuentas separadas por entorno, por lo que para cada entorno (desarrollo, test y producción) se despliega una cuenta independiente de Snowflake.
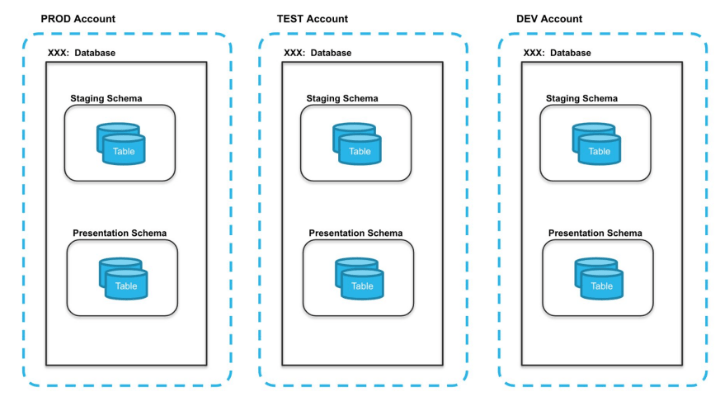
Las principales ventajas son:
- Máximo aislamiento y seguridad, ideal cuando estás manejando datos sensible o sectores regulados.
- Permite usar diferentes ediciones de Snowflake para cada entorno.
Con respecto a las desventajas comentar que:
- Presentan una menor agilidad, ya que no se puede clonar datos entre cuentas,
- Supone una mayor carga administrativa para mantener la sincronización entre entornos.
Y finalmente, la opción donde se cuenta con una cuenta de producción aislada. Es decir, producción está asociado a una cuenta, mientras que desarrollo y test comparten cuenta.

Las principales ventajas son:
- Existe un buen equilibrio entre agilidad y seguridad
- Los datos de producción están aislados, por lo que se pueden proteger de manera más eficiente los datos sensibles.
- Los entorno no productivos pueden gestionarse de forma ágil y permite además, ediciones distintas entre productivo y no productivo.
Como desventajas mencionar:
- No es posible clonar información entre producción y no producción
- Se requiere un esfuerzo de adminitración para mantener la sincronización entre cuentas.
Es por esto que, la elección del modelo de despliegue depende mucho de los requisitos de seguridad, el compliance, la agilidad y la admnistración de cada empresa. Por supuesto, también de los equipos, casos de uso, etc. Comprender estas opciones en detalle te permite diseñar una arquitectura sobre Snowflake alineada con las mejores prácticas y las necesidades propias de tu organización.
De nuevo, volviendo a la conversación con este equipo, también se puso en valor la necesidad de mejorar el metadatado, no sólo de los actuales activos de datos, mirando principalmente al origen, sino a las propias capas que se construyen dentro de la propia solución de datos. Esa va a ser la baza fundamental para pasar de una Data Intelligence Platform a una Decision Intelligence Platform. Según Gartner, el futuro de las soluciones de datos pasa por enriquecer el contexto mediante diccionarios, glosarios, catálogos, documentación, etc de cara a dotar de mayor calidad y profundidad a los metadatos de la plataforma. De este modo, los agentes expertos en el dominio serán realmente de ayuda a los equipos NO técnicos que quieran «escudriñar» los datos de su área de conocimiento en su totalidad.
El ecosistema de los datos está evolucionando a una velocidad de vértigo empujado por las propias necesidades que la Inteligencia Artificial está demandando. Así que, o te subes a la ola o muy posiblemente no convertirás en ventaja estratégica las Insights obtenidas mediante la explotación de tus activos de datos.
Foto de portada gracias a Pixabay: https://www.pexels.com/es-es/foto/lanzamiento-de-cohetes-espaciales-73871/
