
La ingeniería de datos está viviendo una transformación profunda. Con la irrupción de la IA generativa, los modelos multimodales y la explosión de datos no estructurados, las empresas necesitan plataformas que permitan ingestar, mover y transformar datos con la misma elasticidad con la que escalan sus casos de IA. En este contexto, Snowflake dió un paro decisivo al integrar Openflow de forma nativa.
¿De dónde viene Openflow?
Para entender Openflow hay que remontarse a una de las tecnologías más influyentes del dataflow moderno: Apache NiFi.
NiFi nació inicialmente dentro de la NSA para manejar flujos masivos de datos sensibles y posteriormente fue liberado como proyecto Open Source. Su arquitectura se basa en flows visuales, procesadores reutilizables y backpressure lo convirtió en un estándar para pipelines complejos.
Los fundadores de Datavolo (Joe Witt y Luke Roquet) estuvieron directamente involucrados en la génesis de NiFi, y más tarde crearon Datavolo como evolución natural del concepto, orientada a los retos de la IA moderna y la ingesta multimodal (texto, imágenes, audio, logs).
Openflow hereda este ADN de Apache NiFi, combinando su robustez y expresividad con la experiencia de Snowflake en gobernanza, seguridad y escalabilidad cloud.
La adquisición de Datavolo: por qué SNowflake dio este paso
En noviembre de 2024, Snowflake anunció la adquisición de Datavolo para reforzar drásticamente su capa de integración de datos. ¿La motivación principal? Dar respuesta a uno de los grandes puntos débiles en la arquitectura moderna: la complejidad de mover datos desde cientos de sistemas hacia un entorno unificado para IA y análisis.
Datavolo aportaba exactamente lo que Snowflake necesitaba:
- Gestión nativa de datos multimodales.
- Motor de flujos basado en Apache NiFi, maduro y probado.
- Procesadores flexibles y extensibles para pipelines complejos.
- Capacidades de replicación agent-based para entornos híbridos
- Preparación de datos AIready, incluyendo casos de RAG.
Con esta integración, Snowflake dejó atrás el antiguo esquema de «conectores aislados» y adoptó una plataforma de integración unificada, orquestada y escalable, completamente gestionada desde el Data Cloud.
¿Qué es exactamente Openflow?
Openflow es la evolución final del motor de Datavolo, pero totalmente integrado en Snowflake. Sus características clave son:
- Arquitectura control plane (gestionado por Snowflake) + data plane (permite SPCS o BYOC).
- Conectividad universal: SaaS, On-prem, Streaming, Cloud Storage, SharePoint, etc.
- Soporte completo para datos estructurados, semi-estructurados y no estructurados.
- Piepelines AI-ready, diseñados para alimentar a Cortex, modelos LLM, RAG, y workloads de ML.
En esencia, Openflow se convierte en la columna vertebral de movimiento de datos para todo lo que sucede después: análisis, ML, Ai Generativa, aplicaciones, etc.
Snowpark: la pieza clave para el runtime y el despliegue
la parte más innovadora del rediseño de Openflow es cómo Snowflake ha integrado Snowpark y Snowpark Container Services (SPCS)
Snowflake ha elegido SPCS como entorno principal para desplegar los data planes de Openflow. Esto ofrece ventajas fundamentales:
- Aislamiento seguro dentro del perímetro de Snowflake.
- Autoscaling nativo sin gestionar infraestructura.
- Integración directa con metadatos, credenciales y políticas de acceso.
- Observabilidad unificada de logs, métricas y fallos.
Openflow puede ejecutarse, tanto dentro de Snowflake a través de SPCS como en BYOC (Bring Your Own Cloud) que es perfecto para empresas con requerimientos específicos de cumplimiento regulatorio.
Snowpark no solo soporta el runtime, sino que permite:
- Versionado de pipelines vía Git y CI/CD.
- Empaquetado reproducible de procesadores y flujos.
- Despliegue automático en distintos entornos (dev, test, prod).
- Automatización DataOps de extermeo a extremo.
Con Snowpark, Openflow encaja perfectamente en el paradigma «Data as Code», donde todo pipelines es auditable, reproducible y gobernado.
¿Qué significa Openflow para las organizaciones?
La visión es clara: Openflow es la base de conectividad universal de Snowflake.
- Pone fin al caos de herramientas ETL / ELT heterogéneas.
- Habilita análisis y AI multimodal sin fricción.
- Reduce drásticamente el coste operacional.
- Acelera el time-to-value de iniciativas de IA.
- Unifica Data Engineering + ML Engineering + AI Engineering.
No es solo un nuevo producto… Es la capa definitiva de integración del Snowflake AI Data Cloud.
Guía paso a paso para crear tu primer pipeline de datos con Openflow sobre Snowpark Container Services (SPCS)
Lo primero es acceder a la cuenta de Snowflake y pulsar sobre el icono de Ingestion en el lateral izquierdo de la interfaz. A continuación, pulsar sobre el botón «Launch Openflow».
El siguiente paso corresponde a completar un deployment eligiendo cual de las dos fórmulas es la indicada para este caso.
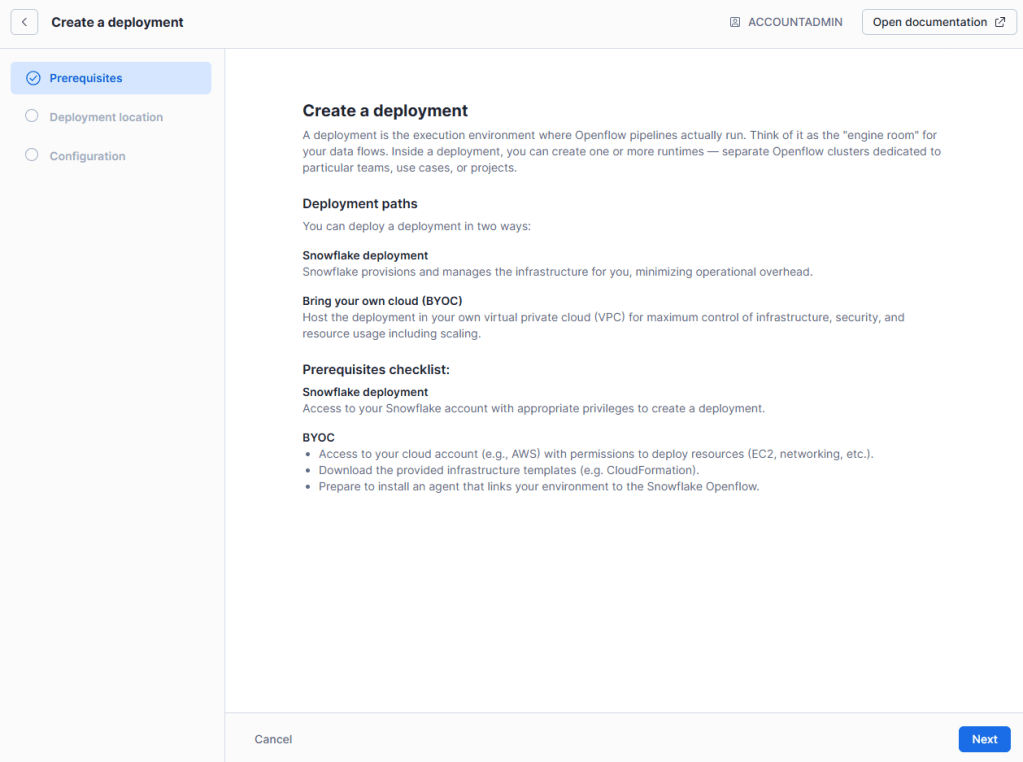
En nuestro caso, se elige realizarlo sobre Snowflake.
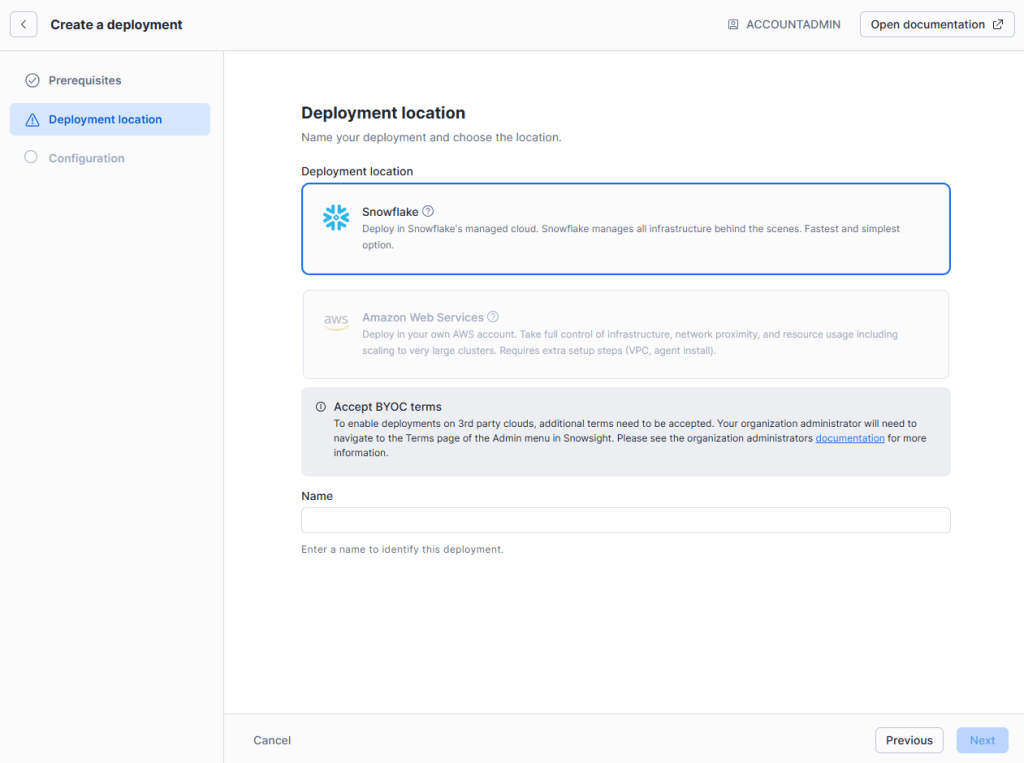
Por lo que tan solo quedaría completar el formulario de configuración.
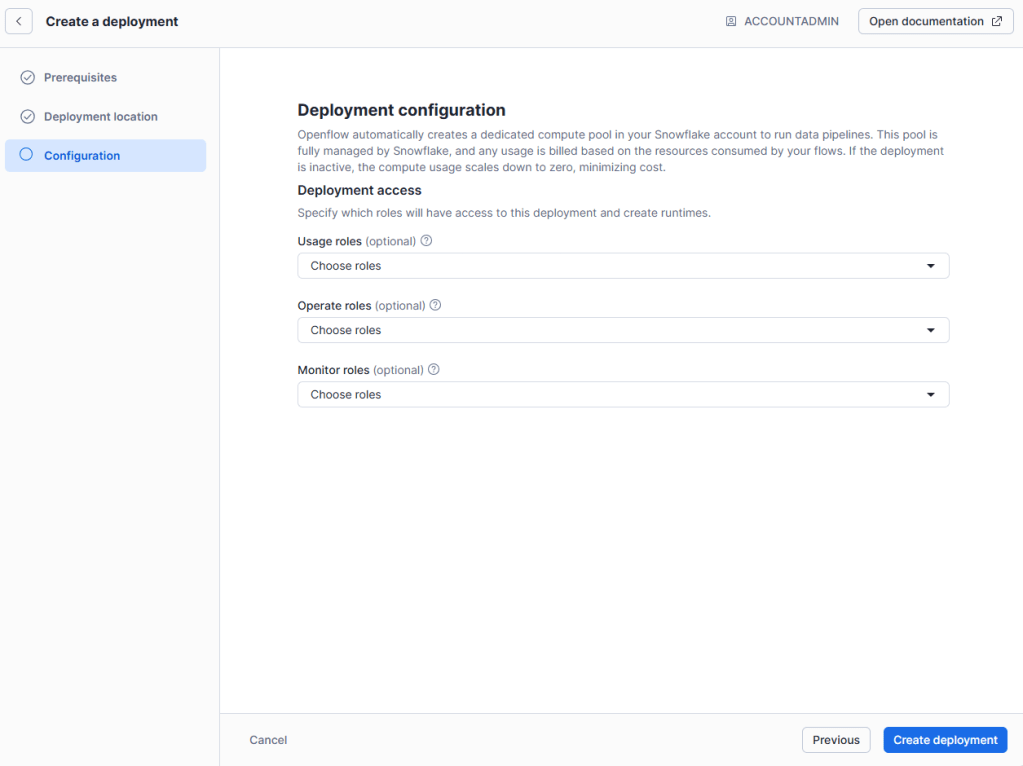
Una vez completamos el formulario, se comienza el deployment propiamente dicho que como se ve en la captura de pantalla, puede llegar a emplear algo más de 15 minutos.
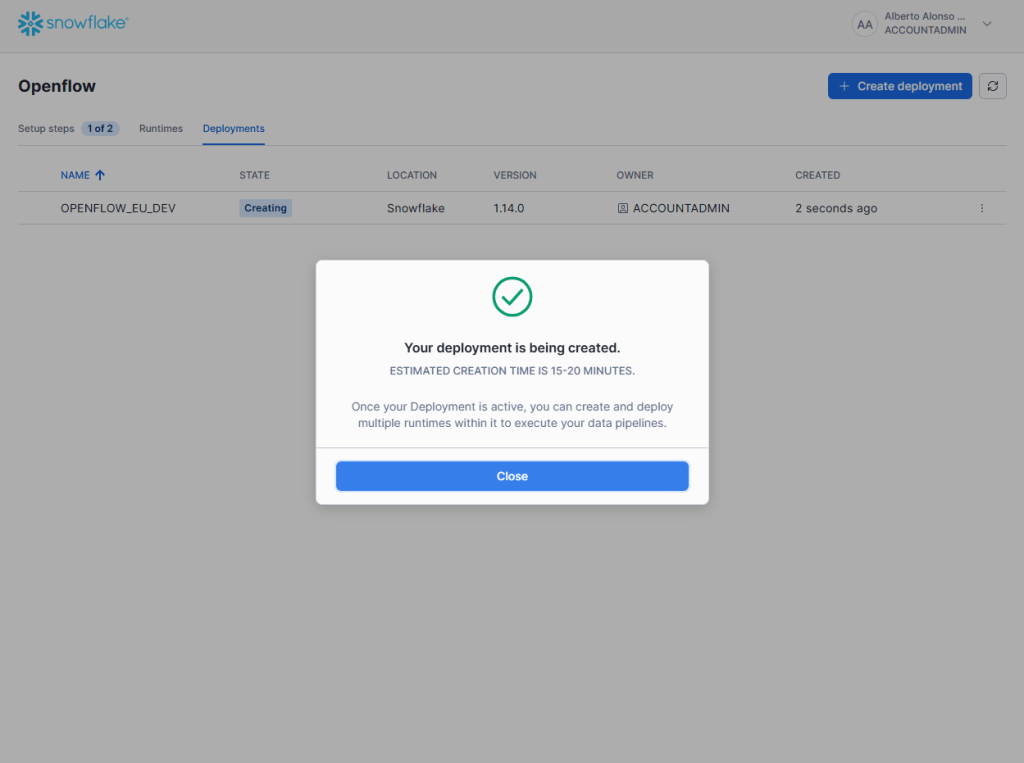
Una vez termina, comprobamos que tenemos nuestro recién creado deployment.
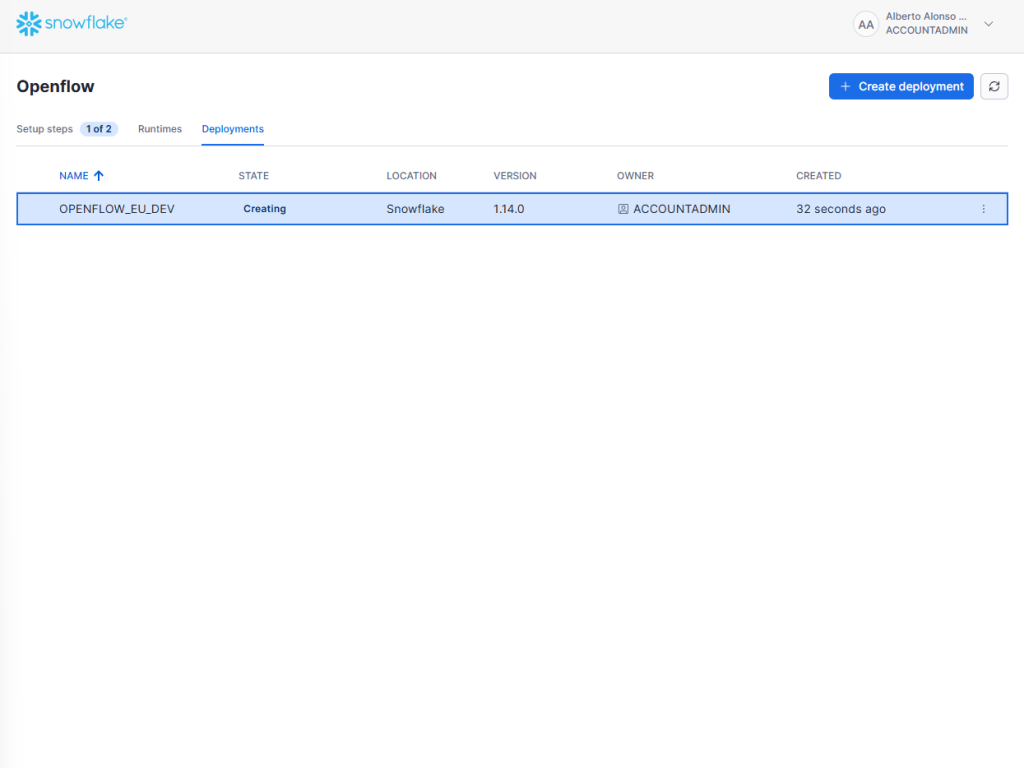
Y finalmente, pasa al estado de «Active».
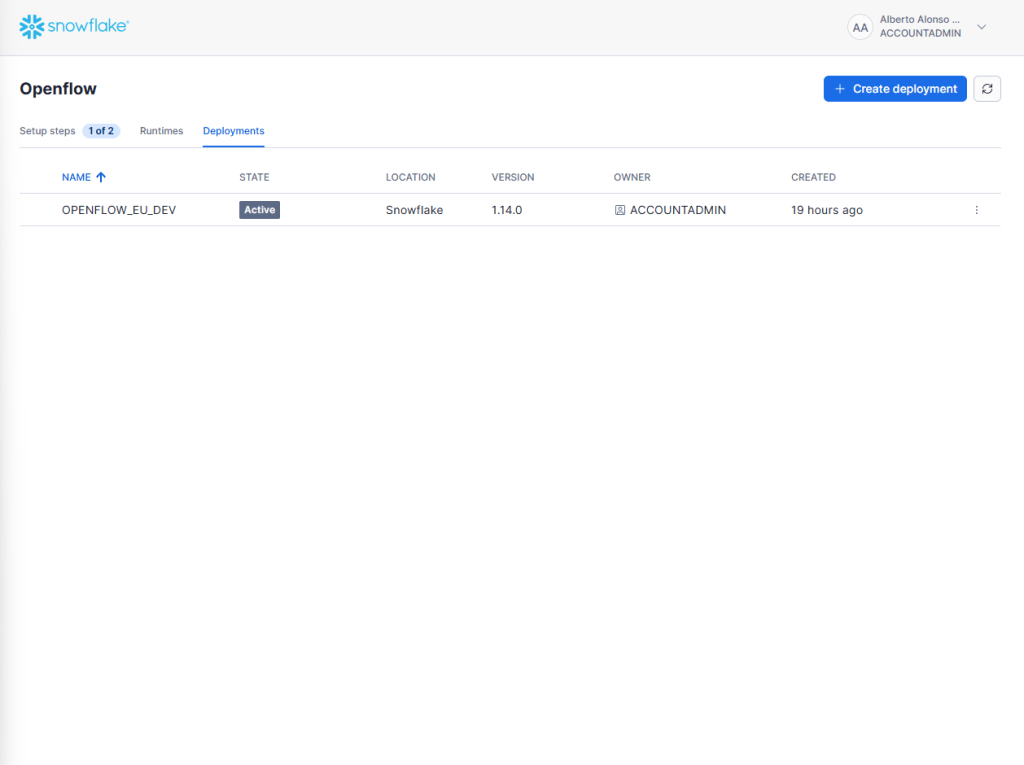
Acto seguido, se procede con la creación del runtime que nos permitirá construir los pipelines de Openflow. Se inicia pulsando sobre el botón «Create Runtime».
Se configura el tamaño, el mínimo y máximo de nodos, el rol con el que trabajará, etc.
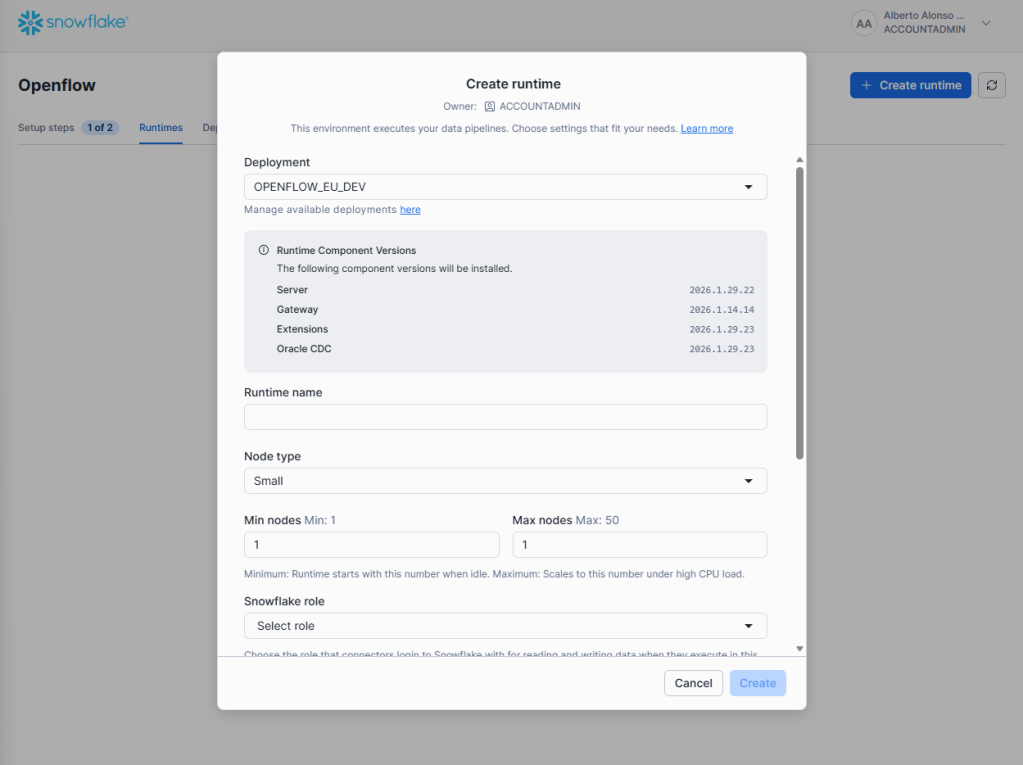
Lo primero es darle un nombre, en nuestro caso: OPENFLOW_RT_EU_DEV
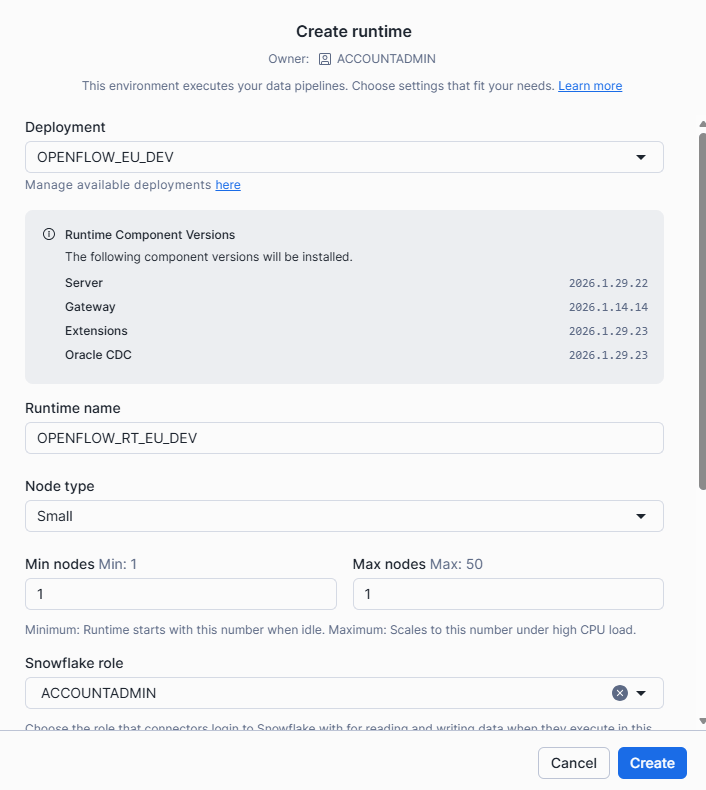
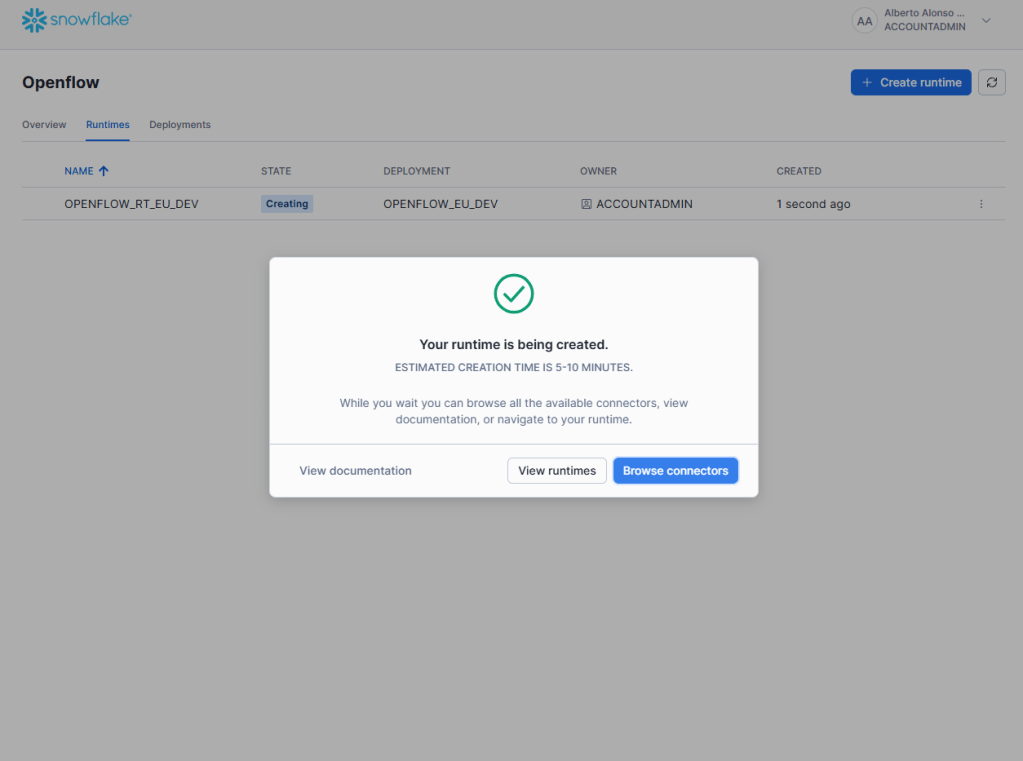
Al completar todo el formulario con los parámetros deseados, se pulsa en «Create».
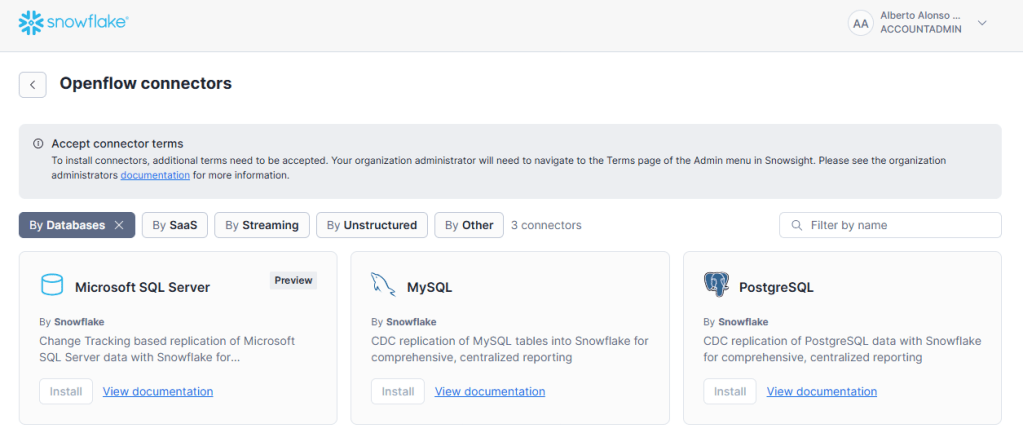
Se revisa la documentación referente a los principales conectores de Openflow.
TIP: Es importante saber que para usar OPENFLOW no debes tener como DEFAULT ROLE uno administrativo, por eso es recomendable hacer una serie de ajustes como los siguientes:
USE ROLE ACCOUNTADMIN;CREATE ROLE IF NOT EXISTS OPENFLOW_RUNTIME_ROLE_OPENFLOW_RT_EU_DEV;GRANT ROLE OPENFLOW_RUNTIME_ROLE_OPENFLOW_RT_EU_DEV TO USER ALBERTOALONSO;ALTER USER ALBERTOALONSO SET DEFAULT_ROLE = OPENFLOW_RUNTIME_ROLE_OPENFLOW_RT_EU_DEV;ALTER USER ALBERTOALONSO SET DEFAULT_SECONDARY_ROLES = ('ALL');GRANT USAGE, OPERATE ON WAREHOUSE DEV_DEMO_ADMIN_WH_XL TO ROLE OPENFLOW_RUNTIME_ROLE_OPENFLOW_RT_EU_DEV;GRANT USAGE ON DATABASE DEV_DEMO_STG_DB TO ROLE OPENFLOW_RUNTIME_ROLE_OPENFLOW_RT_EU_DEV;GRANT USAGE ON SCHEMA SalesLT TO ROLE OPENFLOW_RUNTIME_ROLE_OPENFLOW_RT_EU_DEV;
En ese momento, desde el Runtime activo, puedes acceder al CANVAS donde comenzar a crear tu pipelines de datos.
Como puedes observar, si has trabajado previamente con Apache NiFi, la User Interfaz es exactamente la misma.
INGESTA
La idea es conectar con una Azure SQL Database con la BBDD de AdventureWorks y crear un pipeline que permita la ingestión de dos de sus tablas pertenecientes al schema SalesLT: Address y Customer.
TIP: es necesario que tanto la BBDD, como las tablas, tengan activado CHANGE_TRACKING.
ALTER DATABASE [sales-data-adb-dev-01]SET CHANGE_TRACKING = ON(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON);ALTER TABLE [SalesLT].[Address]ENABLE CHANGE_TRACKINGWITH (TRACK_COLUMNS_UPDATED = ON)ALTER TABLE [SalesLT].[Customer]ENABLE CHANGE_TRACKINGWITH (TRACK_COLUMNS_UPDATED = ON)
También es fundamental conocer el rando de IPs con las que actúa SPCS, ya que no es una máquina virtual que gestiones tú directamente. Para conocer dicha información solo necesitas ejecutar el siguiente código:
SELECT SYSTEM$GET_SNOWFLAKE_EGRESS_IP_RANGES();
El resultado es un JSON que incluye el detalle y que te permitirá actualizar el firewall de tu Azure SQL Database. Por otro lado, también es necesario crear una NETWORK RULE y un EXTERNAL ACCESS INTEGRATION para que se puede «comunicar» Openflow con nuestro recurso en Azure. Este es el código a emplear
CREATE or replace NETWORK RULE OPENFLOW_NETWORK_RULE_DEV_DEMO_STG_DB TYPE = HOST_PORT MODE = EGRESS VALUE_LIST = ('<tusqlserverazure>.database.windows.net:1433');CREATE or replace EXTERNAL ACCESS INTEGRATION OPENFLOW_OUT ALLOWED_NETWORK_RULES = (OPENFLOW_NETWORK_RULE_DEV_DEMO_STG_DB)ENABLED = TRUECOMMENT = 'External Access Integration for Openflow connectivity';
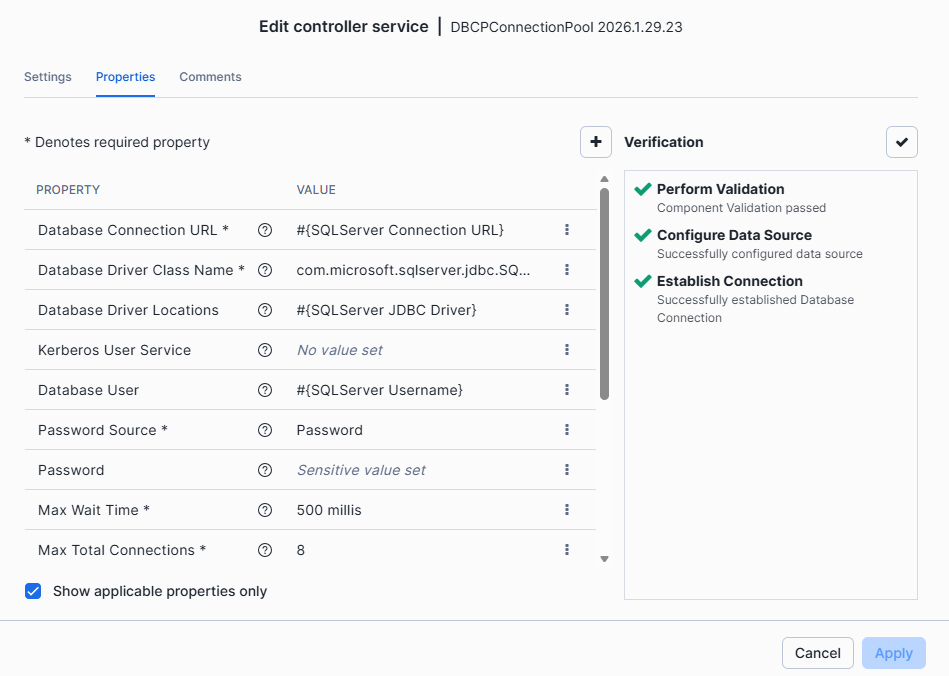
Tras habilitar las comunicaciones hay que ponerse a configurar los parámetros. Uno fundamental es incluir el fichero .jar del controlador JDBC de sql.
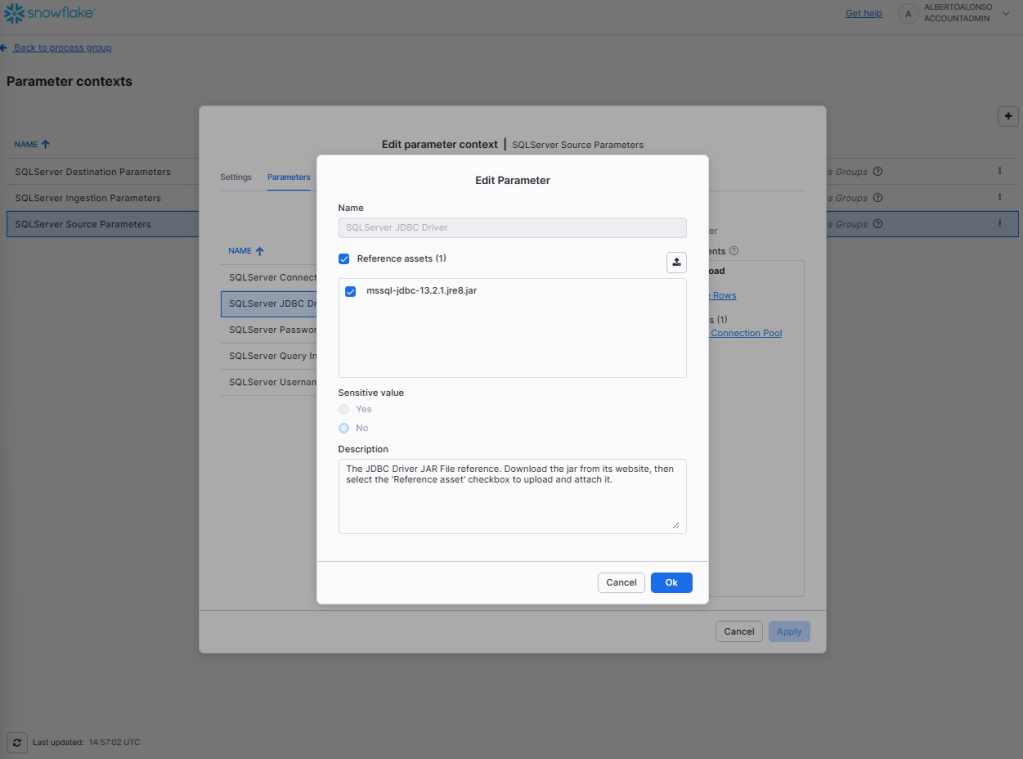
Tras completar la configuración, se recomienda revisar que todo se ha realizado correctamente en los distintos servicios. En este caso se trata de comprobar que los parámetros incluidos del SQL Sever Source Parameters son los adecuados.
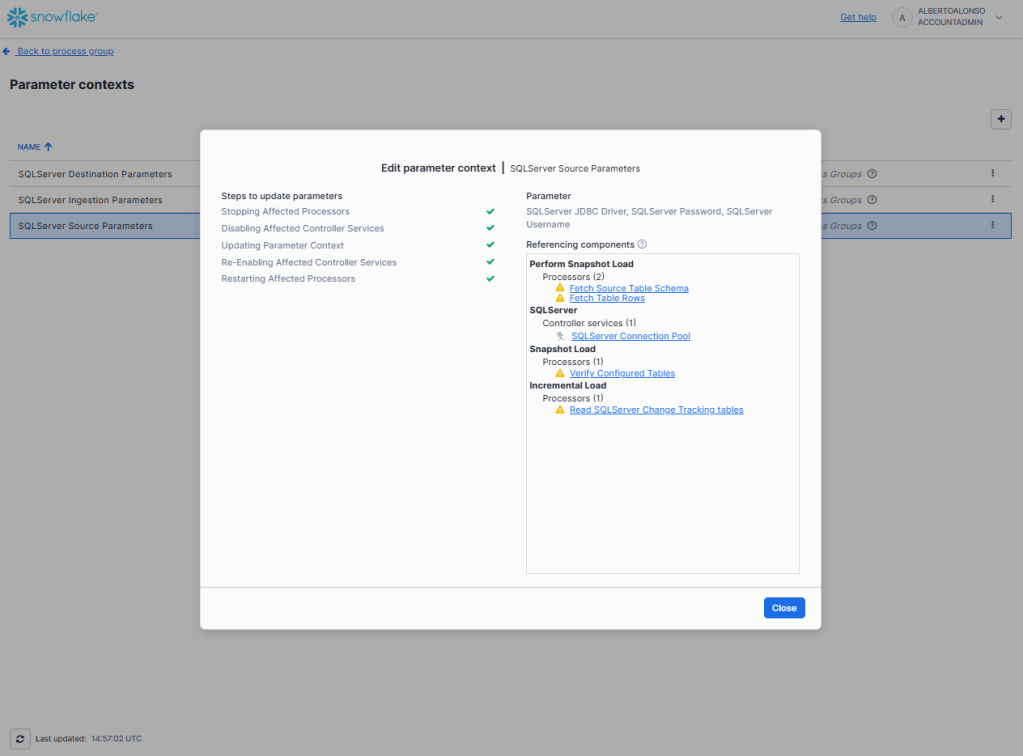
TIP: en caso de que no falte uno o más pasos de los comentados a la hora de configurar la conexión entre ambos servicios, aparecerá un mensaje como este cuando se verifique la servicio.
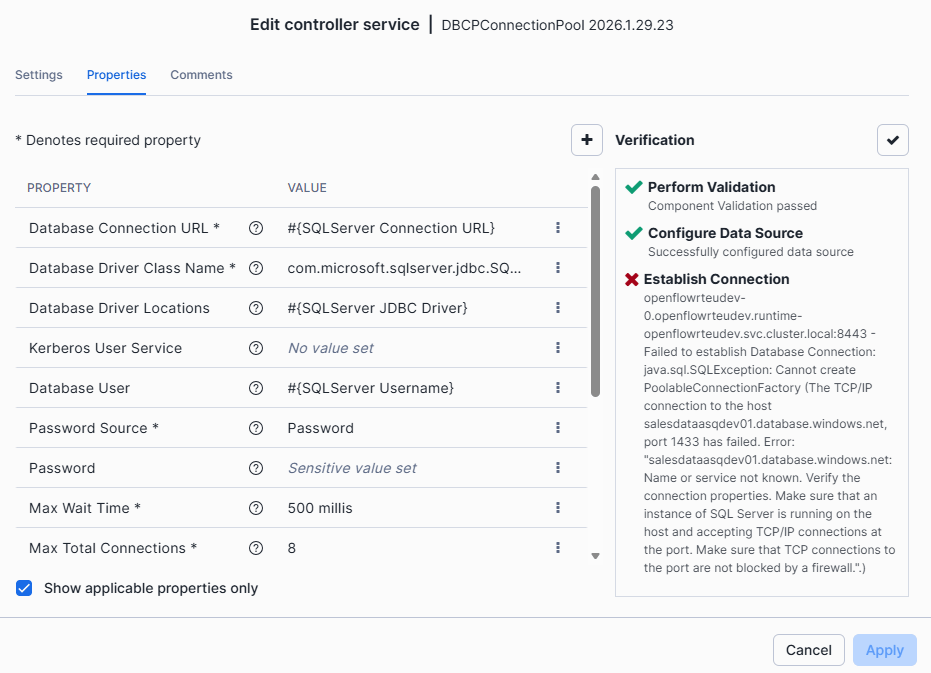
Recuerda que el runtime que emplees haga uso del External Acces Integration que hayas configurado mediante la ejecuión del código previo.
Y si todo está correctamente configurado, al verificar por segunda vez, el resultado será «Ready».
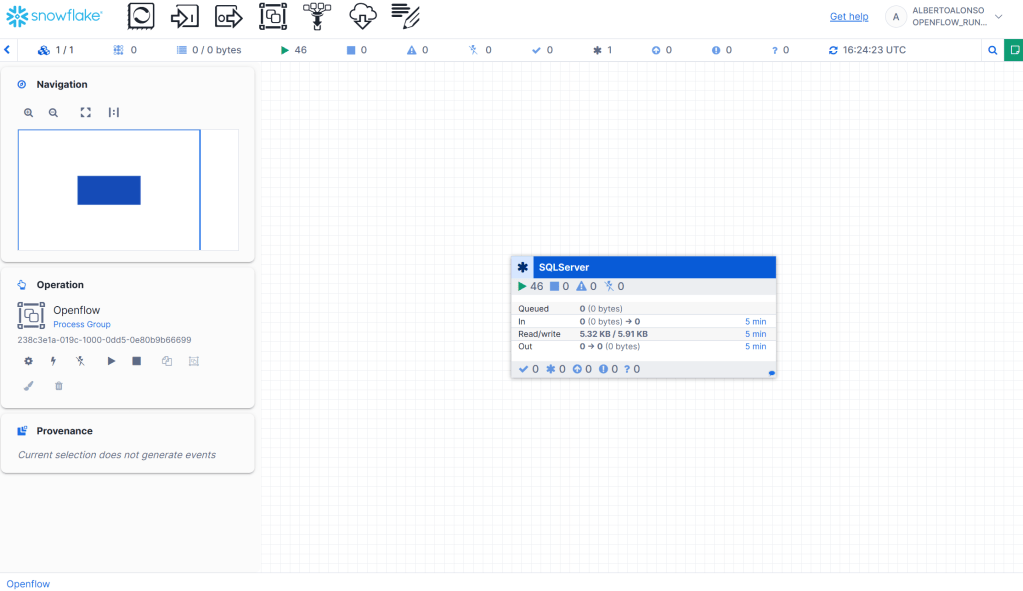
Para quien esté habituado a trabajar con Apache NiFi, esta interfaz le resultará tremendamente familiar.
Se crean todo los flujos (y sus pasos correspondiente), se configuran y validan.
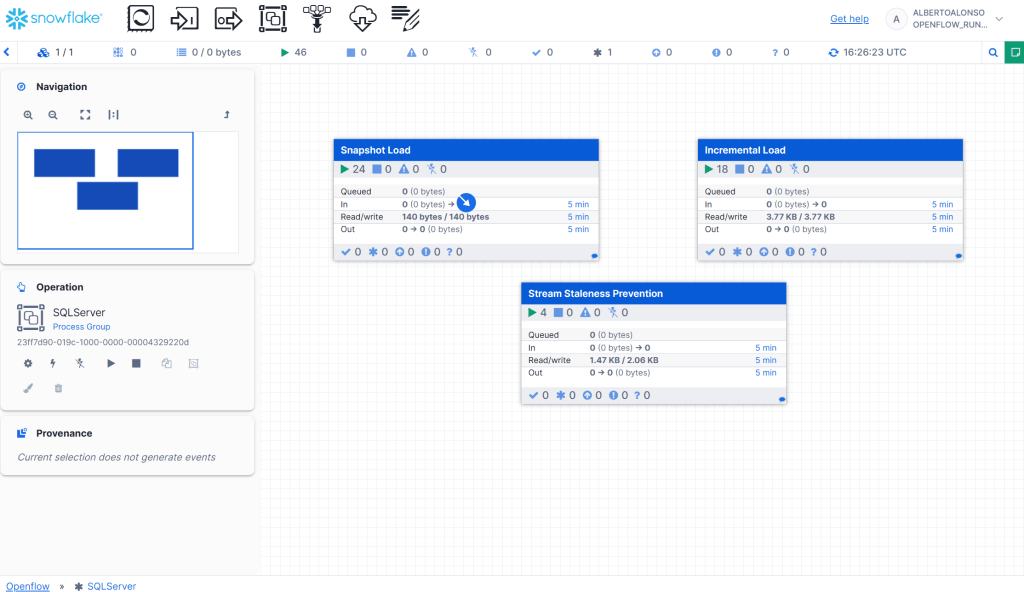
Vamos al detalle del caso de Snapshot Load
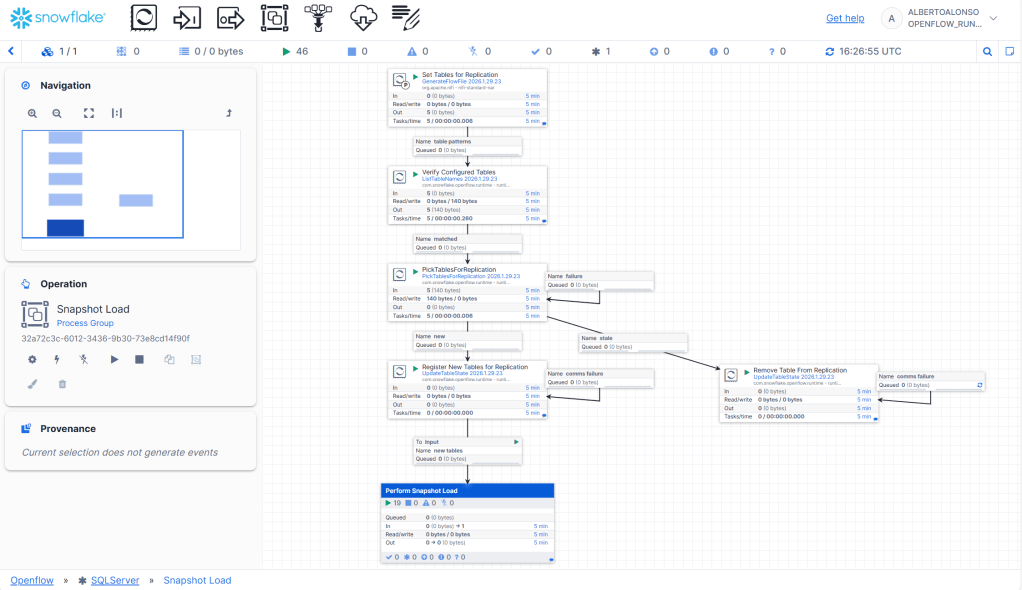
Donde «cajitas» como «Performance Snapshot Load» se pueden «complicar» ligeramente.
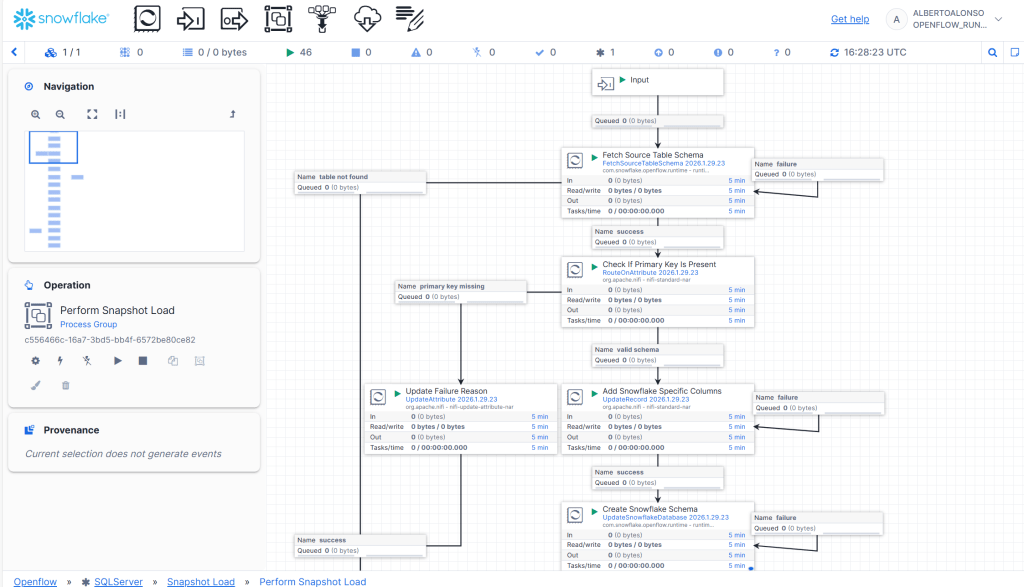
Ahora queda ejecutar el pipeline completo y validar que tenemos las dos tablas creadas bajo el schema SalesLT y que el contenido se muestra correctamente al pulsar sobre la pestaña de «Data Preview».
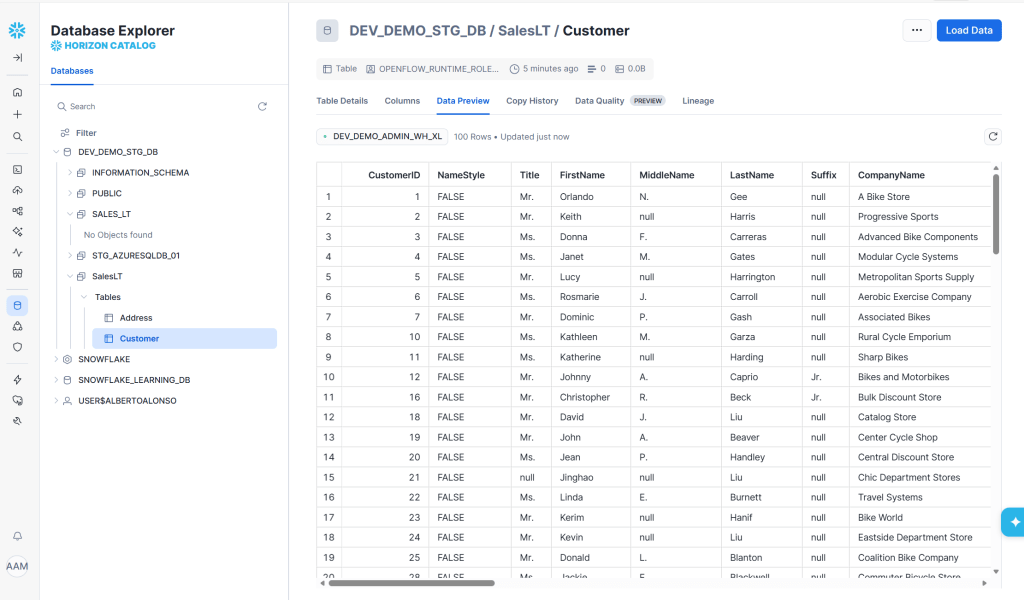
Tabla SalesLT.Customer
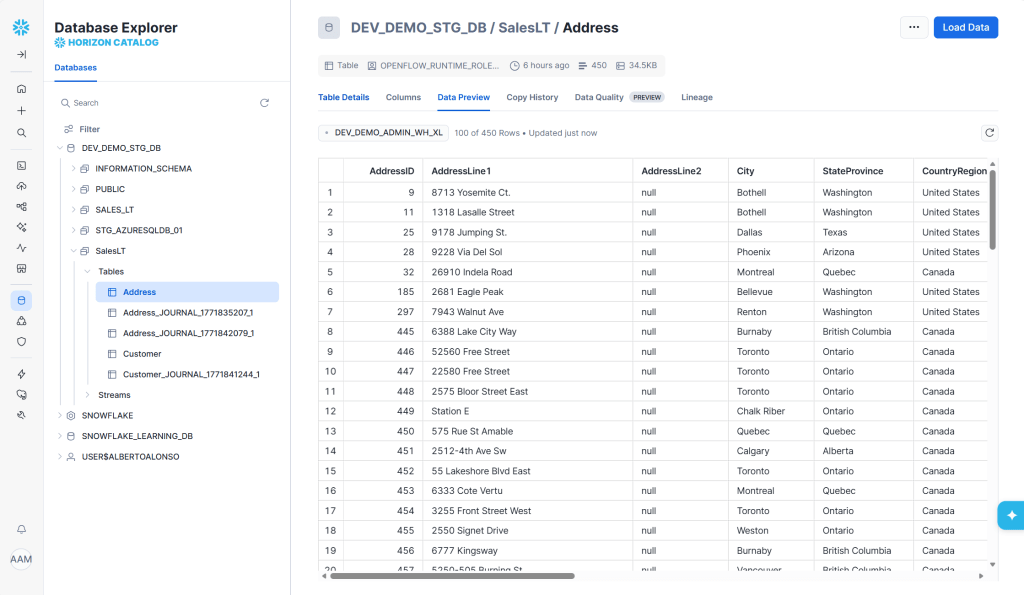
Tablas SalesLT.Address
Conclusión
Snowflake ha hecho una apuesta estratégica: convertir Openflow en el estándar unificado de pipelines para empresas que aspiran a operar con IA generativa a escala gracias a la combinación de:
- Apache NiFi
- la tecnología y visión de Datavolo
- Snowpark como runtime
- y la gobernanza del Data Cloud
crea un stack difícil de igualar en el mercado actual.
Openflow no es un conector más, es la nueva columna vertebral de la ingeniería de datos moderna.
Foto de portada gracias a Startup Stock Photos: https://www.pexels.com/es-es/foto/7369/
