
La rapidez con la que evoluciona la tecnología, posibilita distintas aproximaciones a un mismo caso. Si bien, éste puede presentar distintos matices que nos hagan decantarnos por una u otra. En el caso de las arquitecturas modernas de datos, sucede justamente eso, han evolucionado desde el tradicional BI hacia la Analítica Avanzada. Este recorrido está íntimamente ligado con la adopción del Cloud y especialmente, a la creciente necesidad de las organizaciones por acercarse al análisis de datos en Real Real Time.
Es aquí donde se encuentra la principal diferencia entre las arquitecturas Lambda y Kappa. La primera (Lambda) utiliza dos capas de procesamiento bien diferenciadas. Por supuesto, cada una cuenta con sus componentes específicos para el tratamiento de los datos. Así por ejemplo tenemos que, una de las capas utiliza el procesamiento de tipo batch, mientras que la otra se encarga del procesamiento en streaming. Es decir, por un lado estaríamos implementando lo que sería más similar al BI tradicional y por el otro tendríamos toda la parte de analítica en RRT.
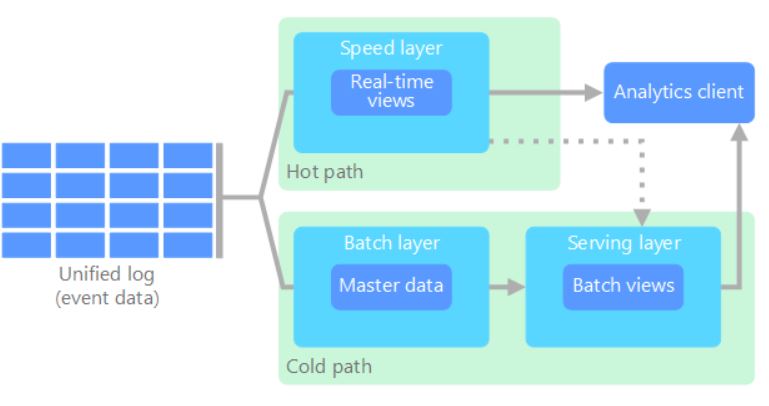
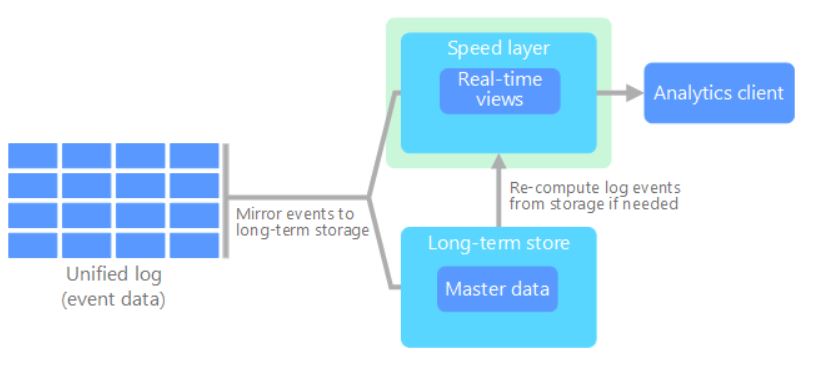
Mientras que en la segunda arquitectura (Kappa), se asume que el tipo batch no es más que un stream con la particularidad de que dispone de un inicio y final. Por lo que se elimina la capa batch, dejando exclusivamente la capa de procesamiento en streaming.
Además de estas dos arquitecturas principales, han surgido otras posibles opciones como la Arquitectura Delta que propone Databricks. Hablé acerca de ella en esta entrada, por si os apetece echarla un vistazo:
https://alb3rtoalonso.com/2020/04/18/example-post-3/
Por supuesto, cada una de ellas presenta una serie de ventajas e inconvenientes. Es por tanto interesante conocerlas, ya que ésto, nos permitirá poder decidir cual es la arquitectura de referencia por la que debemos apostar, para cubrir todos los requerimientos del caso de uso.
En el caso de Azure, existe un increíble portfolio de soluciones que, permite una customización para cubrir prácticamente cualquier caso de uso por mi complejo que sea. A mi, personalmente, me gusta mucho la recomendación de la Plataforma Moderna de Datos propuesta por Microsoft.
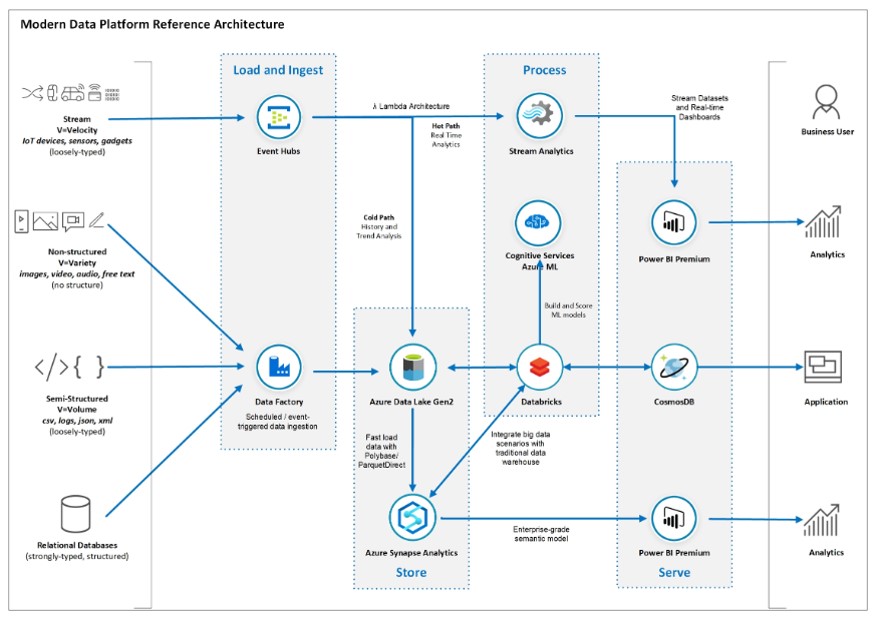
Para que esta arquitectura sea casi perfecta, quedan dos aspectos a incluir.
El primero la diferencia del resto, se trata de la sencilla integración con Azure DevOps y la posibilidad de desplegar y configurar, todos los elementos mediante ARM Templates, en tantos entornos como deseemos con un simple click. Además de brindarnos la posibilidad de implementar buenas prácticas tanto de DataOps como MLOps. Esto es posible gracias a que cada vez son más los elementos de Azure que, se integran con Git y permiten el versionado nativo. Por ejemplo Azure Data Factory que, mediante su integración directa con Git y su rama adf_publish, facilita enormemente los despliegues.
El segundo es la nueva pieza de Gobierno del Dato, Azure Purview. Permite que Azure se acerque a distribuciones como Cloudera Data Platform. Esto era algo que suponía un clara desventaja para Microsoft.
Con todo esto, sólo quiero destacar los esfuerzos que Microsoft está realizando de cara a posicionar su Cloud como el referente en la estrategia de datos de las organizaciones.
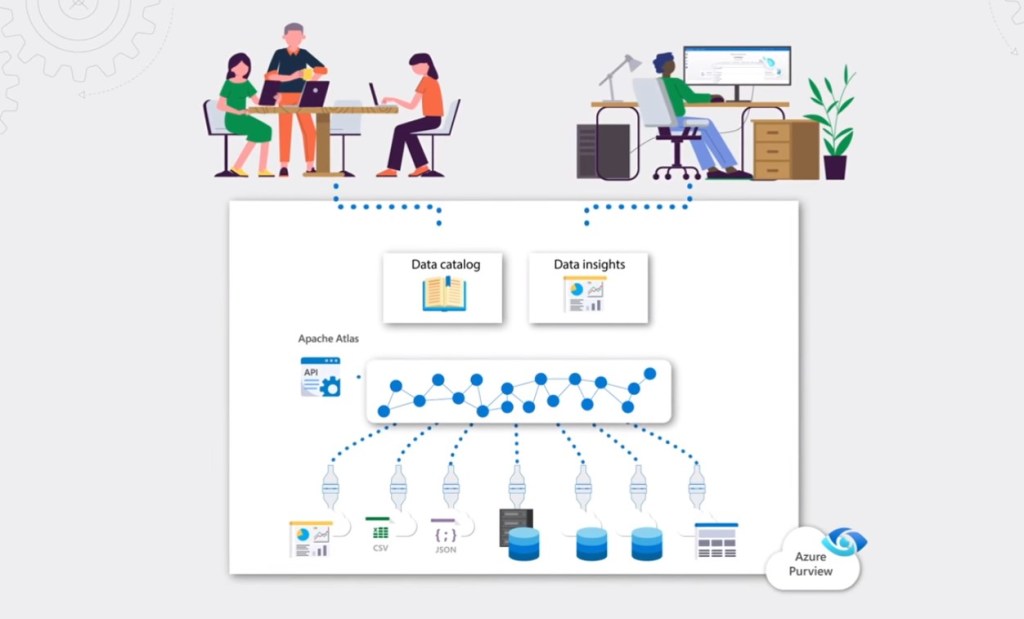
Puedes leer acerca de Azure Purview en el siguiente link:
https://alb3rtoalonso.com/2020/12/23/azure-purview-o-como-la-cloud-de-microsoft-crece-para-ser-lider-en-data/
Otras fuentes consultadas:
https://docs.microsoft.com/es-es/azure/architecture/data-guide/big-data/
Foto de portada Christina Morillo en Pexels

2 comentarios sobre “De Lambda a Kappa y tiro porque me toca”