
Es sabido por muchos de vosotros las numerosas ventajas de la adopción del cloud como solución empresarial. Si bien ésto no quiere decir que el on premise esté condenado a desaparecer, ni mucho menos. Soy de la opinión que esa opción está y seguirá estando presente en el mundo de las empresas. Ya que son muchas organizaciones que siguen montando sus propios «hierros» para soporte de sistemas como el ERP o muchas otras herramientas empresariales, específicas de la actividad, que no necesitan «salir» fuera del edificio. Pero el artículo va de DataOps con lo que, ¡retomemos el tema! 😉
Entre las muchas ventajas que ofrece la nube está dos que para mi son clave. Seguramente por mi formación como farmacéutico. Son la repetibilidad y la confiabilidad. Como digo, en la industria farmacéutica esos dos factores son sumamente importante. Un proceso productivo debe estar validado y tras esa validación, siempre, siempre debe ejecutarse del mismo modo. De ahí, la importancia de seguir al pie de la letra, las guías de correcta fabricación y los procedimientos normalizados de trabajo. En el mundo de la tecnología en la nube, eso vendría a ser, la capacidad de despliegue de todos aquellos componentes de una solución, tantas veces como sea necesario conociendo que siempre se ejecutará de la misma forma una vez que haya sido aprobado. Estamos hablando de DevOps y en el caso específico de datos, de DataOps.
Nos encontramos en un entorno en el que, hoy por hoy, las organizaciones cada vez más, demandan soluciones que les aporten un mayor valor añadido. Ya sea por aspectos innovadores, o como resultado de la mejora de los propios procedimientos de trabajo. En este aspecto creo que aún hay margen de mejora. Uno, como he comentado anteriormente, es adoptar las buenas prácticas DataOps, el segundo es tratar los proyectos en modo «End to End». Es decir, incluyendo actividades de QA dentro del propio desarrollo. Y el tercero, es integrar sistemas de seguridad, aunque sean de terceros, que mejoren dicho aspecto.
En el caso de Microsoft, la adopción de DataOps se fundamenta en la integración de herramientas como Azure DevOps, Git y Visual Studio. En este último, es muy interesante instalar el Azure SDK 😉
Empezaremos como siempre desde la base. Ahí nos encontramos con la infraestructura, aspecto básico de cara a poder realizar despliegues de un modo repetible y confiable. No sólo de forma iterativa sobre el propio desarrollo, cuando las nuevas mejoras son traducidas en versiones, sino además, en el caso de que queramos desplegar esos mismos componentes en otro entorno o incluso en otro proyecto. Para ello, es fundamental entender bien el uso de las variables. Nos evitarán mucho retrabajo y por tanto, seremos más eficientes. Merece la pena pensar antes de ponerse a escribir 😉
A lo largo de la próxima semana, construiré un ejemplo de cómo desplegar de un modo sencillos tanto un grupo de recursos mediante Azure PowerShell, como montar un proyecto de Visual Studio del tipo ARM Template conectado con el repositorio de Git y a su vez con Azure DevOps para el despliegue de un servidor Azure SQL Server y su base de datos.
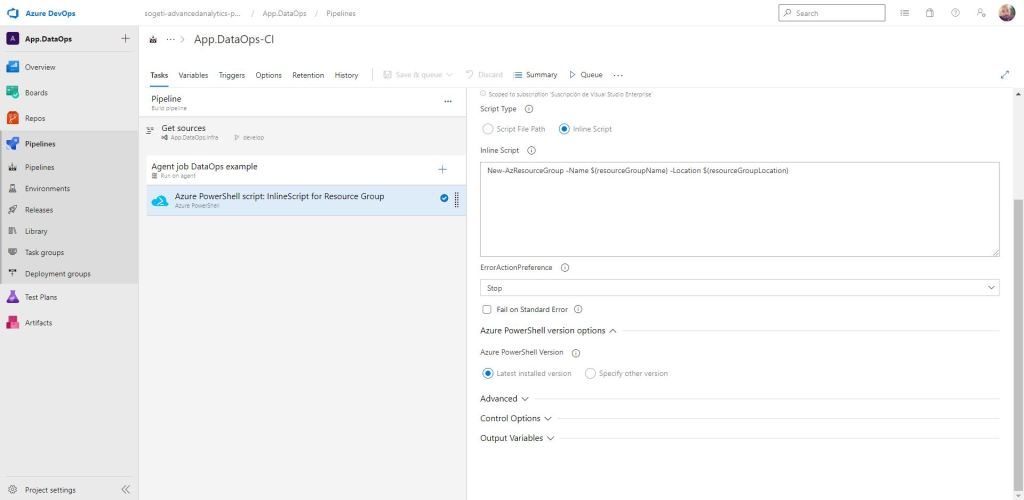
Foto de portada gracias a Philipp Birmes en Pexels
