
Como ya mencioné en la anterior entrada, donde hice un breve resumen del Lakehouse Day de Databricks en Madrid, la incorporación de Unity Catalog suma y mucho a la hora de tomar la decisión sobre cual es la mejor herramienta con la que construir la solución de datos corporativa. Del mismo modo mencioné que, para mi (y muchos otros) a día de hoy, Databricks es la pieza clave para ello. Ahora bien, la entrada de hoy no tiene por objeto seguir alabando a Databricks, sino que busca crear una simple demostración de como funciona el Data Linaje dentro de Unity Catalog.
Recordar que el mes pasado describí el proceso para crear un metastore y vincularlo con uno o más Databricks Workspace. Es obligatorio completar esa parte si quieres comenzar a usar las capacidades de Unity Catalog.
Aclarado este punto, comenzamos justo donde lo dejamos por entonces. En ese momento, tan sólo habíamos creado un par o tres de tablas en total para los schemas «production» y «manufacturing«. Bueno, pues además de crear algún que otro recurso adicional vamos a realizar el ejercicio de insertar registros en las tablas y finalmente crear una tabla resumen por cada uno de los schemas. Si bien, estas tablas se van a crear de dos modos distintos, para ver si Unity Catalog es capaz de tenerlo en cuenta y finalmente proveernos de la información de linaje del dato correctamente. ¡Veamos!
Lo primero, desde el notebook es seleccionar el Catalog sobre el que quieres trabajar. En este caso se trata de «datamodelversion1«.
USE CATALOG datamodelversion1Una vez completado, creamos nuestra primer tabla «production.department«
CREATE TABLE IF NOT EXISTS production.department
(
deptcode INT,
deptname STRING,
location STRING
);Insertamos un par de registros en la tabla
INSERT INTO production.department (deptcode, deptname, location) VALUES (1, 'solid', 'AA1'), (2, 'liquid', 'AA2')Creamos la tabla «production.employee«
CREATE TABLE IF NOT EXISTS production.employee
(
empcode INT,
firstname STRING,
lastname STRING
);Insertamos un par de registros
INSERT INTO production.employee (empcode, firstname, lastname) VALUES (1, 'Michael', 'Jordan'), (2, 'Magic', 'Johnson')Nuevamente, creamos una nueva tabla «production.employee_department«
CREATE TABLE IF NOT EXISTS production.employee_department
(
emp_dept_code INT,
empcode INT,
deptcode INT
);Insertamos los registros
INSERT INTO production.employee_department (emp_dept_code, empcode, deptcode) VALUES (1, 1, 1), (2, 2, 1), (2, 2, 2)Y finalmente, creamos la tabla de resumen: «production.resume«
NOTA:
Recuerda que este paso será distinto en el caso del schema de «manufacturing«
CREATE TABLE IF NOT EXISTS production.resume
(
resumeid STRING,
deptname STRING,
firstname STRING,
lastname STRING
)Ahora sólo queda incluir los registros en la tabla, que para el caso que nos ocupa, proceden de una query que emplea las tablas previamente creadas. ¡Veamos!
INSERT INTO production.resume (resumeid, deptname, firstname, lastname)
SELECT
CONCAT(T1.empcode,'-',T1.deptcode),
T0.deptname AS deptname,
T2.firstname AS firstname,
T2.lastname AS lastname
FROM production.department AS T0
JOIN production.employee_department AS T1
ON T0.deptcode = T1.deptcode
JOIN production.employee AS T2
ON T1.empcode = T2.empcodeRepetimos el proceso para el schema «manufacturing«
CREATE TABLE IF NOT EXISTS manufacturing.department
(
deptcode INT,
deptname STRING,
location STRING
);
INSERT INTO manufacturing.department (deptcode, deptname, location) VALUES (1, 'primary', 'BB1'), (2, 'secondary', 'BB2')
CREATE TABLE IF NOT EXISTS manufacturing.employee
(
empcode INT,
firstname STRING,
lastname STRING
);
INSERT INTO manufacturing.employee (empcode, firstname, lastname) VALUES (1, 'Karl', 'Malone'), (2, 'Denise', 'Rodman')
CREATE TABLE IF NOT EXISTS manufacturing.employee_department
(
emp_dept_code STRING,
empcode INT,
deptcode INT
);
INSERT INTO manufacturing.employee_department (emp_dept_code, empcode, deptcode) VALUES (1, 1, 1), (2, 2, 1), (2, 2, 2)Hasta aquí, todo exactamente igual que en el caso del schema «production». Ahora viene la diferencia. La creación de la tabla resumen y la incorporación de los registros se hará en un único paso.
CREATE TABLE IF NOT EXISTS manufacturing.resume
AS SELECT
CONCAT(T1.empcode,'-',T1.deptcode) AS resumeid,
T0.deptname AS deptname,
T2.firstname AS firstname,
T2.lastname AS lastname
FROM manufacturing.department AS T0
JOIN manufacturing.employee_department AS T1
ON T0.deptcode = T1.deptcode
JOIN manufacturing.employee AS T2
ON T1.empcode = T2.empcodeData Explorer
Lo primero es acceder al explorador de datos y seleccionar el Catalog «datamodelversion1» para observar que nuestros dos schemas principales están ahí. Una vez chequeado, desplegamos el contenido de uno y otro y vemos que las tablas se han creado correctamente y que además contienen datos.

El siguiente paso es seleccionar la tabla «manufacturing.resume» y pulsar sobre la pestaña de Linaje.
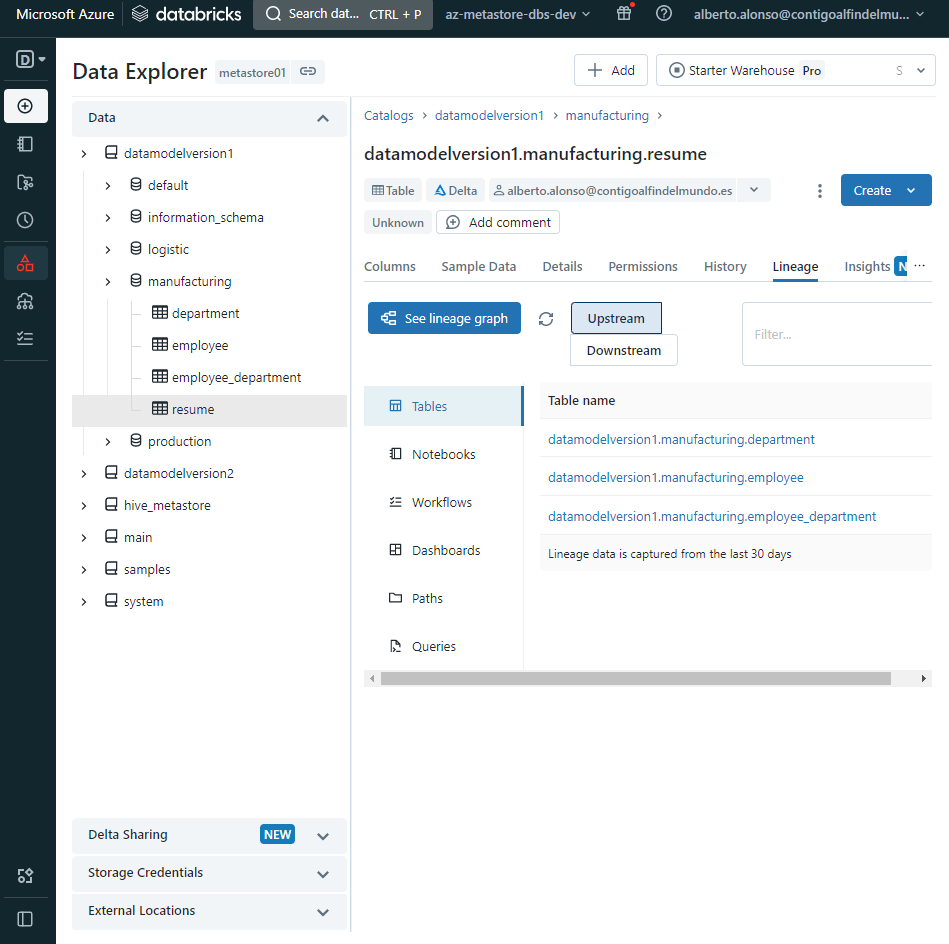
Por defecto, vemos el mode «Upstream» seleccionado, de ahí que aparezcan nuestras tres fuentes de datos en el tablero. Si ahora pulso sobre «See lineage graph» veré lo siguiente.

Pero, y qué sucede con el caso de la tabla resumen del schema de «production«. ¿Se verá igual?

Pues sí, se ve completamente igual. Es decir, da lo mismo cómo creemos nuestra tabla, Unity Catalog realiza la tarea de hacer el tracking y mostrarnos los flujos de datos de un modo muy visual, algo que ayuda y mucho cuando hablamos de transformaciones complejos.
Es más, incluso si pulsas sobre cada uno de los campos de la tabla resumen, te muestra el detalle de sus orígenes, por ejemplo en el caso de resumeid. ¡Veamos!

Tal y como describe la sentencia SQL: «CONCAT(T1.empcode,’-‘,T1.deptcode) AS resumeid» el gráfico nos muestra ambos campos de la tabla de origen, por lo tanto podemos afirmar que el nivel de detalle que ofrece la solución de Linaje es realmente interesante.
Por último, destacar que incluso el componente nos informa del Notebook involucrado en el proceso.

CONCLUSIÓN
Unity Catalog vuelve a demostrar su valor, en este caso en la parte de Gobierno del Dato, área cada vez más tenida en cuenta por los CDO o responsable de los departamentos de Datos de las grandes corporaciones. Ser capaz de conocer en detalle los procesos que han sufrido nuestros datos ayuda a entender de mejor manera el resultado obtenido.
Como dije al comienzo de la entrada, Databricks está haciendo las cosas bien y espero que siga en este camino durante los próximos años, algo que sin duda les ayudará a posicionarse en los primeros puestos de soluciones de Analítica Avanzada.
NOTA:
En breve espero poder ampliar esta parte de Gobierno de Dato mediante la conexión a herramientas de terceros, como puede ser Microsoft Purview u otras. Algo que mejorará si cabe la experiencia de los responsable del dato.
Foto de portada gracias a Brett Sayles: https://www.pexels.com/es-es/foto/edificio-de-hormigon-gris-937493/

Un comentario en “Data Linaje con Unity Catalog de Databricks”