
Cuando hablamos de optimización en Microsoft Fabric, la mayoría de conversaciones se centran en:
- optimización de queries
- tuning de pipelines
- diseño del modelo semántico
Sin embargo, hay un componente que suele quedar fuera del foco… hasta que es demasiado tarde:
«el crecimiento descontrolado del almacenamiento en OneLake«
En entornos productivos, este es uno de los principales drivers de coste oculto.
El problema real: el almacenamiento crece más rápido de lo esperado
La arquitectura de Fabric, basada en OneLake como capa unificada de almacenamiento, introduce una ventaja clara:
👉 una sola copia de los datos para todos los workloads
Pero también introduce un riesgo:
- almacenamiento centralizado
- sin políticas de limpieza por defecto
- con crecimiento continuo desde el día 1
En pocos meses, es habitual encontrarse con:
- capas Bronze con años de históricos
- snapshots intermedios que nunca se eliminan
- datos staging o temporales persistidos indefinidamente
Y lo más relevante:
«todo este volumen se almacena en hot tier por defecto«
La respuesta: OneLake Lifecycle Management
Para abordar este problema, Microsoft introduce un componente clave dentro de OneLake:
👉 Lifecycle Management Policies
Estas políticas permiten automatizar la gestión del ciclo de vida de los datos mediante reglas basadas en:
- fecha de creación
- última modificación
- última lectura
Su objetivo es claro:
«mover automáticamente los datos hacia tiers de almacenamiento más económicos en función de su uso«
Storage tiers en OneLake: el nuevo eje FinOps
OneLake introduce tres niveles de almacenamiento:
| Tier | Uso típico | Coste |
|---|---|---|
| Hot | Datos en activo | Alto |
| Cool | Datos poco consultados | Medio |
| Cold | Archivo / compliance | Bajo |
A medida que se desciende en los tiers:
- disminuye el coste de almacenamiento
- aumenta el coste de acceso
Este modelo está diseñado para ajustar el coste al patrón real de uso
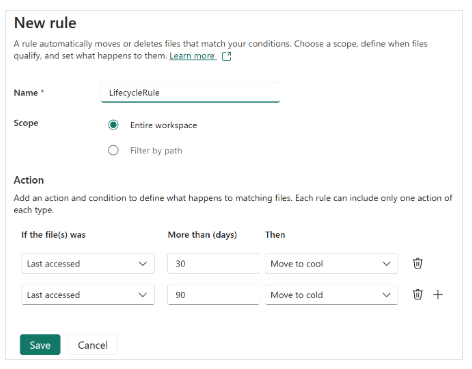
Ejemplo práctico de política de lifecycle
Un enfoque típico en entornos productivos podría ser:
- Datos no modificados en 30 días → mover a cool tier
- Datos sin acceso en 90 días → mover a cold tier
- Acceso posterior → volver automáticamente a hot tier
Este tipo de estrategia permite:
✅ reducir costes automáticamente
✅ evitar intervención manual
✅ adaptar el almacenamiento al uso real
Buenas prácticas FinOps en Fabric
Más allá de la funcionalidad, lo importante es cómo diseñar la estrategia.
Definir el ciclo de vida desde el inicio
El lifecycle no debe tratarse como una operación posterior.
👉 Es una decisión de arquitectura
Debe responder a preguntas como:
- ¿cuánto tiempo es útil cada dato?
- ¿qué capa necesita acceso en tiempo real?
- ¿qué datos pueden degradarse a cold storage?
Segmentar correctamente por capas (Arquitectura de Medallas)
Un error común es tratar todo el almacenamiento de igual forma.
Un enfoque recomendado sería:
| Capa | Estrategia |
|---|---|
| Bronze | Lifecycle agresivo (cool / cold rápido) |
| Silver | Mixto según uso |
| Gold | Mantener en hot el tiempo necesario |
Automatizar siempre (evitar procesos manuales)
Las lifecycle policies:
- se ejecutan automáticamente
- aplican reglas a nivel workspace
- pueden filtrarse por rutas específicas
👉 Esto elimina errores humanos y deuda operativa.
Alinear almacenamiento con patrones de acceso
El punto clave de cualquier estrategia FinOps:
«no optimizar por volumen, sino por uso«
Ejemplos:
tablas operativas → hot
datos de auditoría → cold
datasets de ML históricos → cool
Entender el trade-off: coste vs rendimiento
Mover datos a cold tier reduce el coste de almacenamiento, pero:
- aumenta el coste de acceso
- puede afectar a tiempos de respuesta
👉 La estrategia óptima no es minimizar coste, sino equilibrarlo con el uso esperado.
Reducir duplicidad con OneLake shortcuts
Un error clásico en arquitecturas legacy:
- copiar datasets entre entornos
- multiplicar el almacenamiento
Con OneLake:
👉 puedes usar shortcuts para evitar duplicación
Esto tiene impacto directo en FinOps:
- menos datos duplicados
- menor huella de almacenamiento
Insight clave: el almacenamiento también es un workload
En modelos tradicionales, el foco de optimización estaba en compute.
En Fabric, esto cambia:
«el almacenamiento es un vector clave de coste que debe gestionarse activamente«
Lifecycle Management no es una opción operativa:
👉 es una pieza fundamental de la arquitectura FinOps.
Conclusión
Microsoft Fabric facilita la creación de soluciones analíticas rápidas y escalables, pero:
- el crecimiento del almacenamiento es inevitable
- el coste asociado también
La diferencia entre una plataforma eficiente y una costosa no está en la tecnología, sino en cómo se gobierna.
👉 Las organizaciones que adopten:
- lifecycle policies
- estrategias de tiering
- eliminación de duplicidad
podrán construir plataformas:
✅ más eficientes
✅ más sostenibles
✅ y alineadas con principios FinOps reales
Foto de portada gracias a HAMZA YAICH: https://www.pexels.com/es-es/foto/puesto-de-control-de-seguridad-en-un-monumento-historico-32027096/
