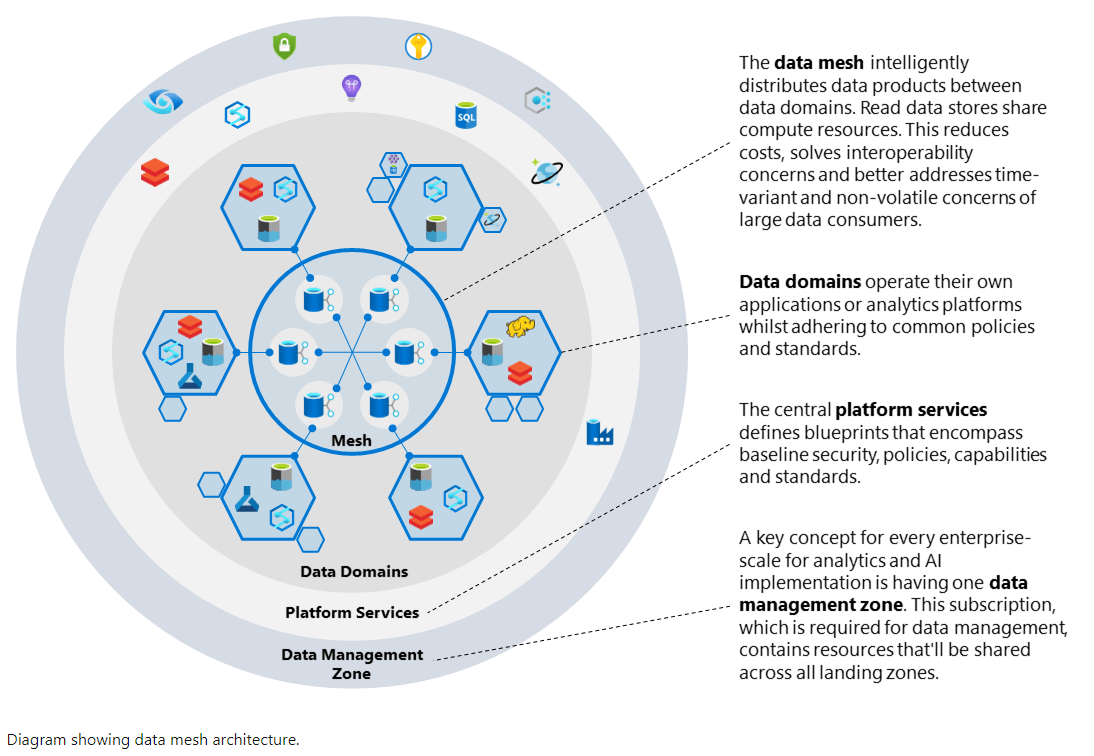
En el mundo de los datos, cada poco tiempo se lanzan nuevas palabras al ruedo y parece que se acerca una revolución. Ya pasó hace tiempo atrás con el Big Data (que empezó como 3V y ya va por nV), el Near Real Time, el Real Real Time y desde hace unos años, resuenan con fuerza Lakehouse, Data Fabric y Data Mesh. Pero, ¿qué hay detrás?
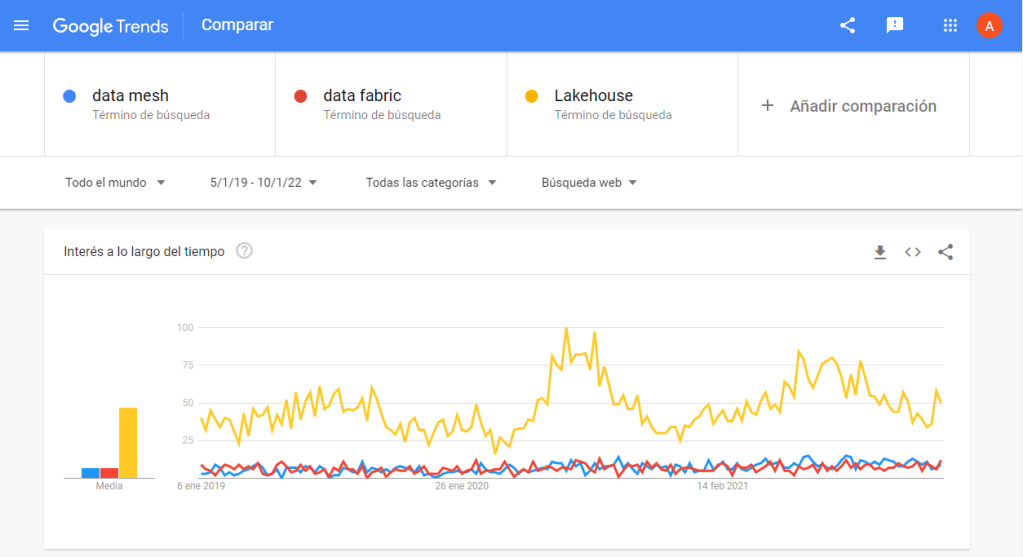
Como podemos observar en Google Trend, tanto Data Mesh como Data Fabric por ahora mantienen una tendencia muy similar en cuanto al número de búsquedas, nada que ver con el oscilante Lakehouse.
Significa eso que, ¿algo se cuece lentamente o por el contrario que son aproximaciones que no terminan de cuajar? Pues buceando en el término Data Mesh, encontré cierta bibliografía que incluyo al final del artículo, donde se explica bastante bien el concepto.
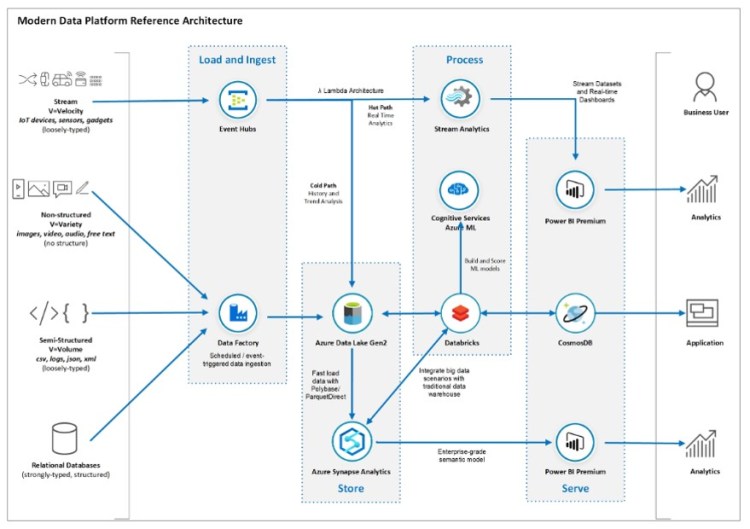
En esta ocasión, el propósito del artículos es que quiero remarcar los aspectos clave de Data Mesh y dónde aprecio sus beneficios frente a lo que puede ser una Plataforma Moderna de Datos de tipo monolítica como la de Microsoft en Azure.
La principales diferencias radican en la visión de los datos como producto y en la descentralización de la gestión. El primero no me parece mal, cada área o departamento empresarial es el que, teóricamente, más conocimiento tiene de su propio negociado, con lo que involucrarles en los procesos, me resulta interesante. Con respecto al segundo punto, la descentralización en la gestión, aún siendo a través de un gobierno federado, ya me produce más miedo, pues en cierto modo lo veo como un paso atrás hacia el aislamiento y la reaparición de silos. Ha costado mucho romper las barreras entre departamentos para la distribución efectiva de información a lo largo de las organizaciones. No me gustaría desandar lo andado. Por último, mencionar el autoservicio como punto de fricción adicional a tener en cuenta.
Con todo ésto, ¿dónde veo muy interesante realizar esta aproximación? Sin duda, en empresas multinacionales, pues con el cambio en el tratamiento del dato hacia producto, permite aspectos como la anonimización de los mismos, así como la construcción de sus correspondientes medidas e indicadores muy cerca del lugar donde se produce el dato. Es decir, se delega la confección de la información al dominio. De este modo, se evitan riesgos por incumplimiento de políticas como GDPR o HIPAA, ya que el dato siempre reside en el territorio y la información que se lanza afuera no contiene datos PII. Sin duda, todo un up con respecto a seguridad y cumplimiento normativo.
Por otro lado, esta aproximación reduce los requerimiento computacionales, ya que divide la carga de trabajo por cada región, país, departamento. Lo que beneficia el procesado de la misma, tanto a nivel local como global. Igualmente el performance se ve beneficiado, pues al utilizar regiones más próximas a la ubicación del dato, la disponibilidad es superior y la latencia es menor. Es decir, todo redunda en una mayor eficiencia.
Sin embargo, al delegar el trabajo en cada región podríamos pensar que la mantenibilidad, el conocimiento y velocidad de desarrollo se verían penalizadas. No es cierto, ya que, por ejemplo desarrollando colaborativamente, acotando por dominio, como si de cualquier otro proyecto se tratara y sumando las capacidad de configurar pipelines de despliegue a múltiples regiones, el resultado sería justamente lo contrario. Dispondríamos de la misma imagen replicada n veces. Es decir, si cada sucursal dispone de un CRM y debe hacer un mismo proceso de transformación, el equipo del dominio sería el encargado de desarrollar el código del trabajo y éste se desplegaría en cada región con un simple golpe de click. Resumiendo, trabajas una vez y propagas a n.
Continuando con los equipos, llega el turno de hablar acerca del equipo de la plataforma. Aquí sucedería algo muy similar. Para ser tremendamente eficiente, sería idóneo construir toda la infraestructura como código, es decir, componentes como plantillas. De este modo, con un simple despliegue a través de Pipelines de Azure DevOps homogeneizarías todas las regiones.
Otra aspecto positivo es que, al designar al dominio y su equipo como el propietario de los datos, la opción de trabajar bajo metodología SAFe puede resultar tremendamente interesante. Pues SAFe no es otra cosa que un framework industrial de escalado para metodología ágil común en grandes empresas.
Mediante su uso, se podrían visibilizar riesgos vinculados al dato entre dominios de un modo sencillo e incluso las dependencias entre distintos proyectos de transformación que requieran de la creación o actualización de alguno de los servicios del dominio. Esto también redunda en una mejor estimación, pues el propietario del domino, como hemos comentado anteriormente, dispone de un alto grado de conocimiento sobre el servicio.
CONCLUSIÓN
En cierto modo se asemeja mucho a cómo trabajan las arquitectura de aplicaciones basadas en microservicios. Estás tienen su puntos fuertes y debilidades, pero está claro que para ciertos casos de negocio, son una muy buena opción. Desde mi punto de vista, creo que Data Mesh es una opción más dentro de las arquitecturas de datos, pero que cobra especial sentido en el ámbito de organización multinacional.
Más información en:
- Zhamak Dehghani, 20 Mayo 2019, https://martinfowler.com/articles/data-monolith-to-mesh.html
- Zhamak Dehghani, 3 Diciembre 2020, https://martinfowler.com/articles/data-mesh-principles.html
- James Serra, 16 Febrero 2021, https://www.jamesserra.com/archive/2021/02/data-mesh/
- Gerardo Vázquez, 15 Septiembre 2021, https://www.bbvanexttechnologies.com/pills/data-mesh-una-nueva-aproximacion-para-una-arquitectura-de-datos-transformacional/
