
El almacenamiento eficiente de datos es una de las piezas clave a la hora de dibujar la estrategia de tu organización, y soluciones como Azure Data Lake te permiten cumplir con las actuales recomendaciones de buenas prácticas en cuanto a arquitectura de datos.
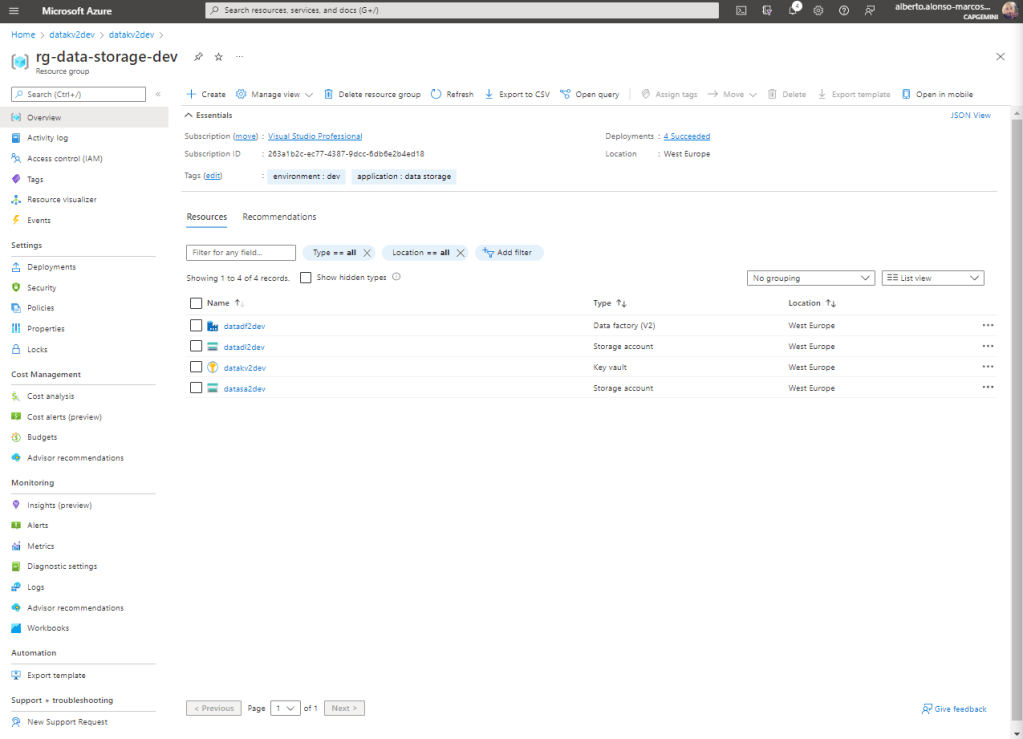
Para este caso de negocio, voy a necesitar un conjunto limitado de recursos, como vemos en la imagen de abajo.
El ejercicio a realizar va a ser el de configurar el movimiento dinámico de datos entre nuestro Azure Storage Account (origen) y Azure Data Lake Gen2 (destino) mediante Azure Data Factory. Nos ayudaremos de Azure Key Vault para securizar las cadenas de conexión a los recursos e implementaremos el proceso de copia de ficheros entre componentes de un modo dinámico. Por último, convertiremos los ficheros de origen en formato .json a ficheros con formato .parquet pues éstos se comportan de un modo mucho más eficiente en soluciones de almacenamiento masivo.
NOTA:
Recuerda que para que Azure Data Factory pueda usar los secrets de Azure Key Vault, debes incluirla en la Access Policies o te devolverá un error.
El primer paso es configurar en Azure Data Factory los correspondientes Linked Services, como vemos en la imagen de abajo. Dispondríamos de uno para el Azure Storage Account, otro para al Azure Data Lake y uno más para el Azure Key Vault donde incorporamos dos secrets que protegerán la Cadena de Conexión del primero y la Access Key del segundo.

El segundo paso es el de configurar nuestros Datasets en Azure Data Factory, en este caso de un modo dinámico. Veamos como. Lo primero es conocer la estructura de los ficheros origen (algo como «customer_2021-01-01.json») y cómo nos gustaría estructurar la jerarquía de carpetas en nuestro Azure Data Lake (algo como «YYYY/MM»).
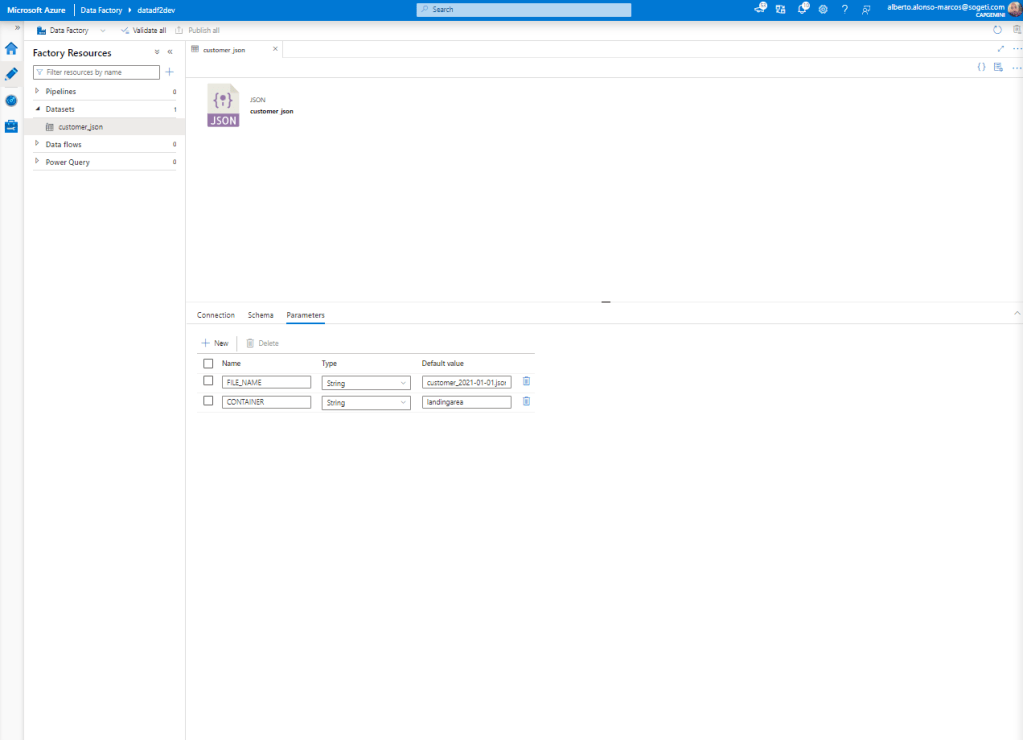
Una vez conocida esta parte, lo siguiente es avanzar con la creación del primer Dataset. Este toma como fuente el Azure Storage Account. Para que actúe de forma dinámica, creamos un par de parámetros, como vemos en la imagen.
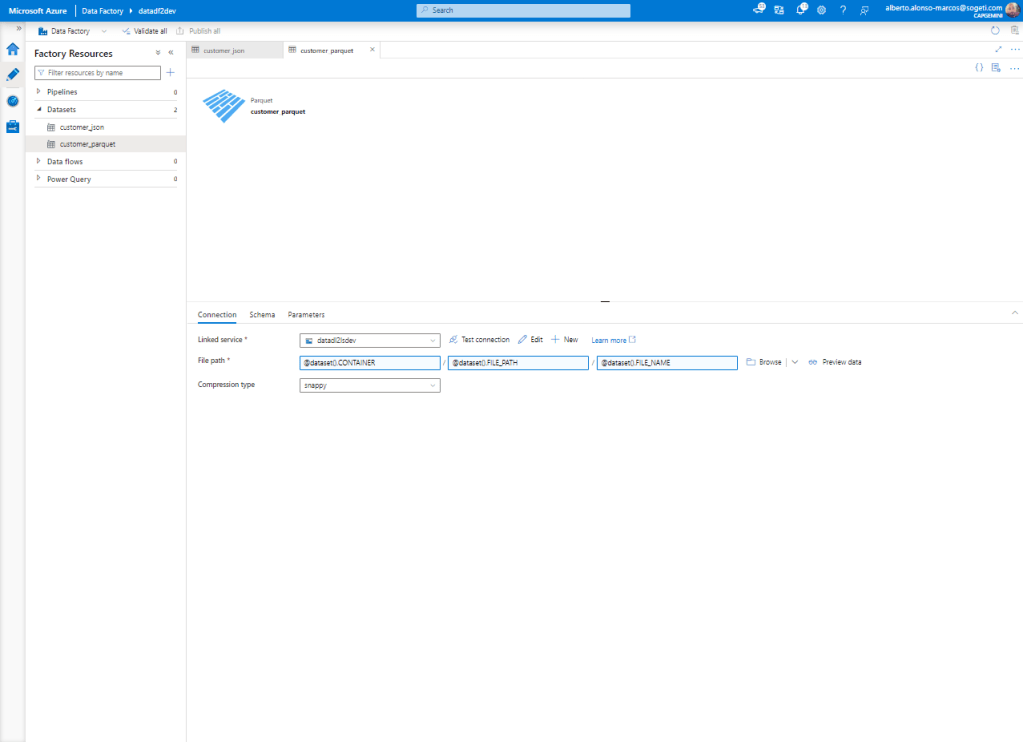
Acto seguido, configuramos la conexión para que se ejecute de forma dinámica. Para ello completamos el proceso incorporando la información que vemos en la imagen.

Llegados a este punto, comenzamos con la configuración del Dataset correspondiente a Azure Data Lake. En este caso, añadimos tres parámetros mediante los cuales podremos ejecutar la carga de forma dinámica en nuestro almacén de datos.
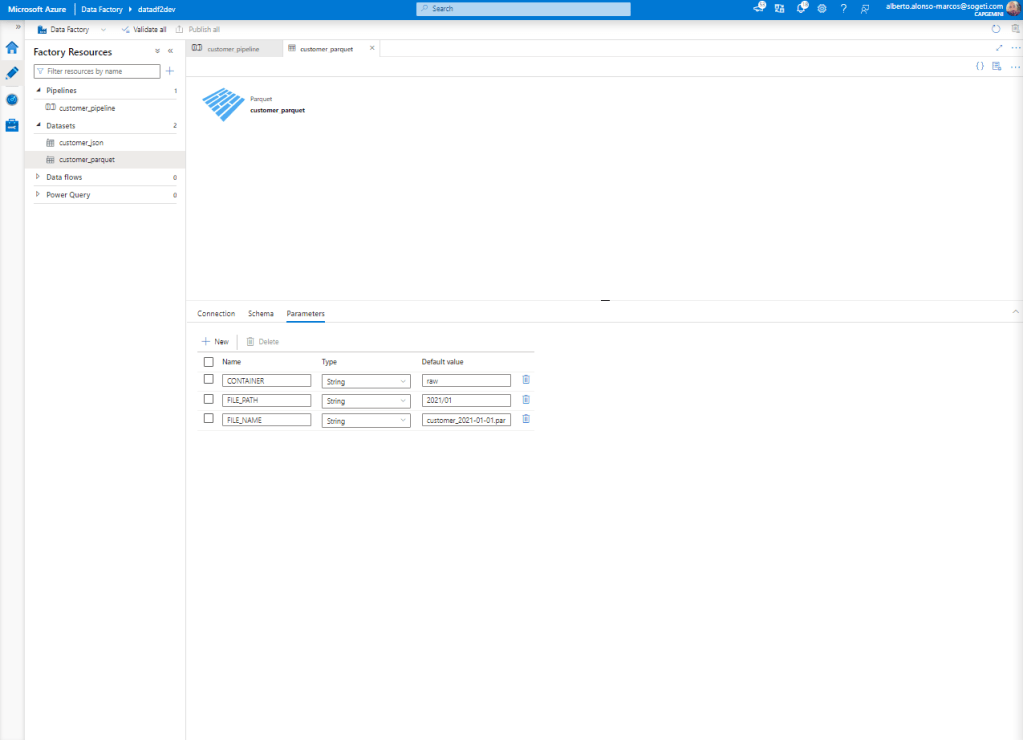
Ahora sólo queda configurar el contenido dinámico de nuestro Dataset, vemos como queda en la imagen de abajo.
Una vez completada la creación de los Datasets, comenzamos con la preparación del Pipeline. La primera actividad es del tipo Get Metadata. Se conecta al Dataset de origen y extrae todos los elementos «hijo». Quedaría algo como la imagen de abajo.
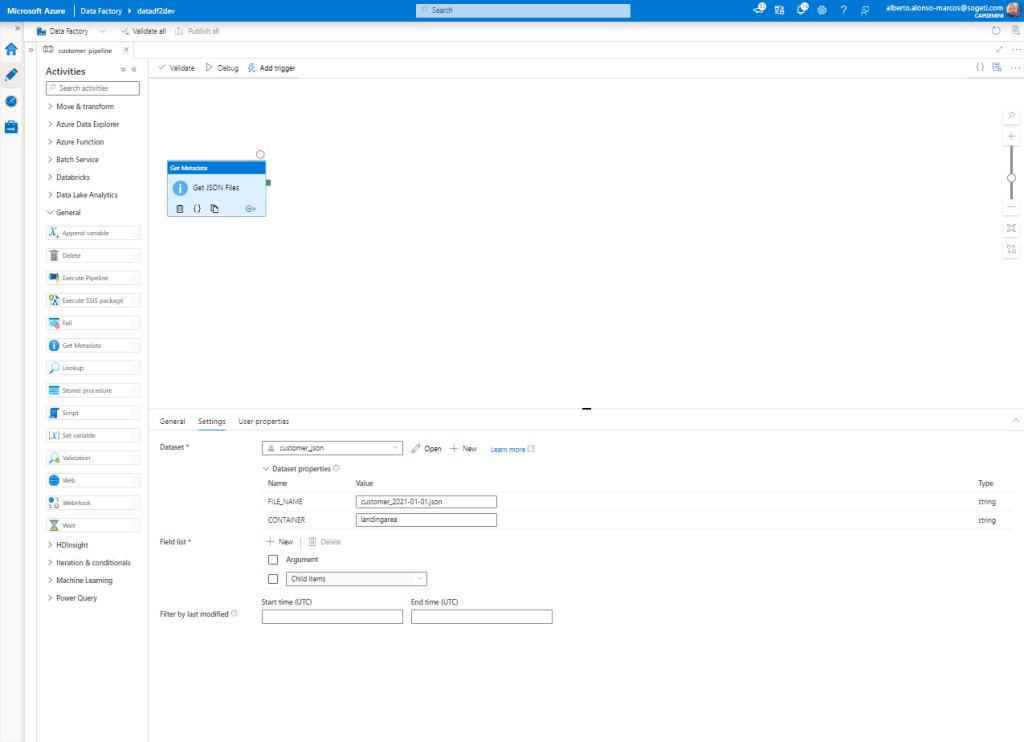
El siguiente paso es configurar un iterador del tipo «For Each» para que mueve cada elemento desde el origen.

NOTA:
Seleccionamos el check de «Sequential» para que tan sólo se ejecute la tarea si la previa resultó exitosa.
Ahora únicamente nos quedaría completar la actividad a realizar dentro del bucle «For Each». Esta se trata de un «Copy Files» que tendrá como origen nuestro Azure Storage Account que para ejecutarse dinámicamente se seleccionará la opción «Wildcard file path» y en el nombre del archivo, incluiremos @item().name tal y como se muestra en la imagen.

Ahora ya únicamente nos queda configurar el destino, que será nuestro Azure Data Lake. En el proceso se realizará de forma dinámica, para ello en el Value de FILE_PATH incluiremos:
@concat(split(item().name,'_')[0],'/',split(split(item().name,'_')[1],'-')[0],'/',split(split(item().name,'_')[1],'-')[1])Y en el caso del FILE_NAME incorporaremos:
@concat(split(item().name,'.')[0],'.parquet')Quedando algo como lo que tenemos en la imagen de abajo.

Tan sólo faltaría hacer el Mapping entre fuentes incluyendo el nombre de cualquiera de los ficheros de origen y listo.

Una vez completado el Pipeline, pulsamos sobre «Debug» y comprobamos que no existen errores.

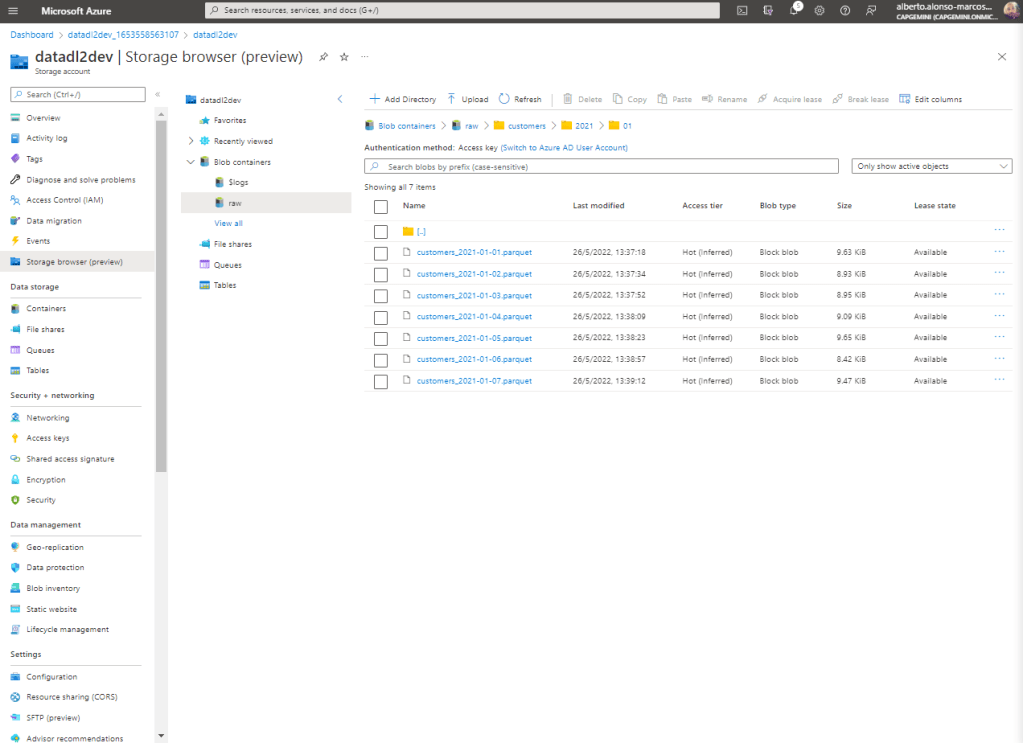
Finalmente verificamos que la información se está cargado correctamente en nuestro Azure Data Lake.
CONCLUSIÓN
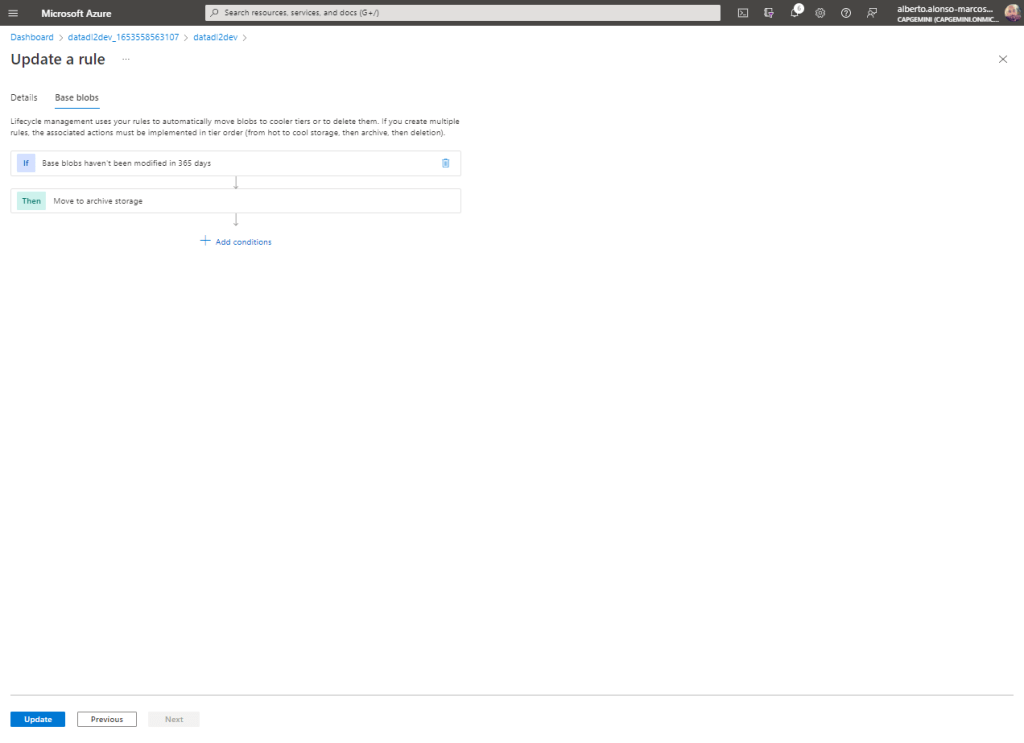
Este sencillo ejemplo, permite entender cómo configurar dinámicamente el almacenamiento jerárquico en nuestro raw container de Azure Data Lake, si bien es un primer paso, pues ahora quedaría la puesta en marcha de por ejemplo, cargas Delta o incorporación de reglas de «Lifecycle Management» para eliminar ficheros y/o cambiar el tipo de Tier de Hot a Cold o Archive.
TIP
Una forma sencilla de limpiar el Dataset de origen según vamos moviendo la información es incluir una nueva actividad del tipo «Delete Files» a continuación de la que nos copia los ficheros en Azure Data Lake, pasando únicamente el @item().name como «Wildcard file name».
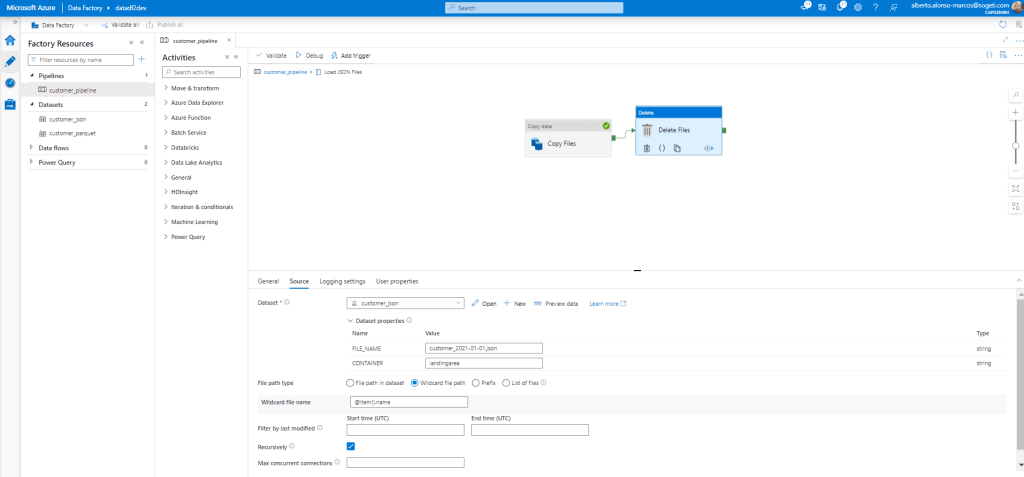
Foto de portada gracias a Ihsan Adityawarman
