
Hace unos días publiqué una entrada sobre Azure Data Lake como solución ideal sobre la que construir el almacén de datos empresarial y hoy amplio el contenido ofreciendo una visión más específica sobre las principales características que habilita con respecto a la seguridad.
Hay dos aspectos básicos que definen el nivel de seguridad que se puede implementar en Azure Data Lake, el primero es relativo a la retención del dato, mientras que el segundo pone el foco sobre el control y la gestión de la autorización.
Veamos más en detalle la parte de Data Retention y a qué afecta principalmente. Dentro de las políticas de retención de datos tenemos dos casuísticas fundamentales:
- Borrado, asegurando que el dato es eliminado exclusivamente cuando ya no es necesario.
- Inmutabilidad, asegurando que el dato no puede ser modificado ni eliminado hasta que no se especifique lo contrario. Esto se consigue habilitando el modo WORM (Write Once, Read Many). Para implementar este modo en Azure Data Lake podemos configurar nuestra política de datos especificando un intervalo de retención o en caso de desconocer dicho periodo, podemos configurarlo definiendo el recurso como Legal Hold.
Mencionar que, a día de hoy, la inmutabilidad aún está en preview para Azure Data Lake Gen2, con lo que hay que solicitar inscribirse en ella mediante la cumplimentación de este formulario y pasados unos días, dispondrás de dicha opción en tu suscripción.

Pues justo como indiqué, tras unos días recibí la confirmación por parte de Microsoft de que esa opción quedaba disponible en mi suscripción, con lo que, podemos continuar con la entrada 😉
En este caso, incluimos la Policy de inmutabilidad a nivel del container raw indicando el tipo como «Legal Hold» y añadiendo la Tag (obligatoria) de «audit», simplemente rellenando todos los cuadros de texto.

Una vez completada la parte de inmutabilidad, nos centramos en generar reglas que nos ayuden a manejar de una manera automática la disponibilidad de la información, por ejemplo cambiando el tipo de Tier entre los tres disponibles o incluso configurando la eliminación del dato una vez pasado un cierto periodo de tiempo. Para orquestar toda esta parte haremos uso de Lifecycle Management Policy, mediante la generación de diferentes reglas.

NOTA:
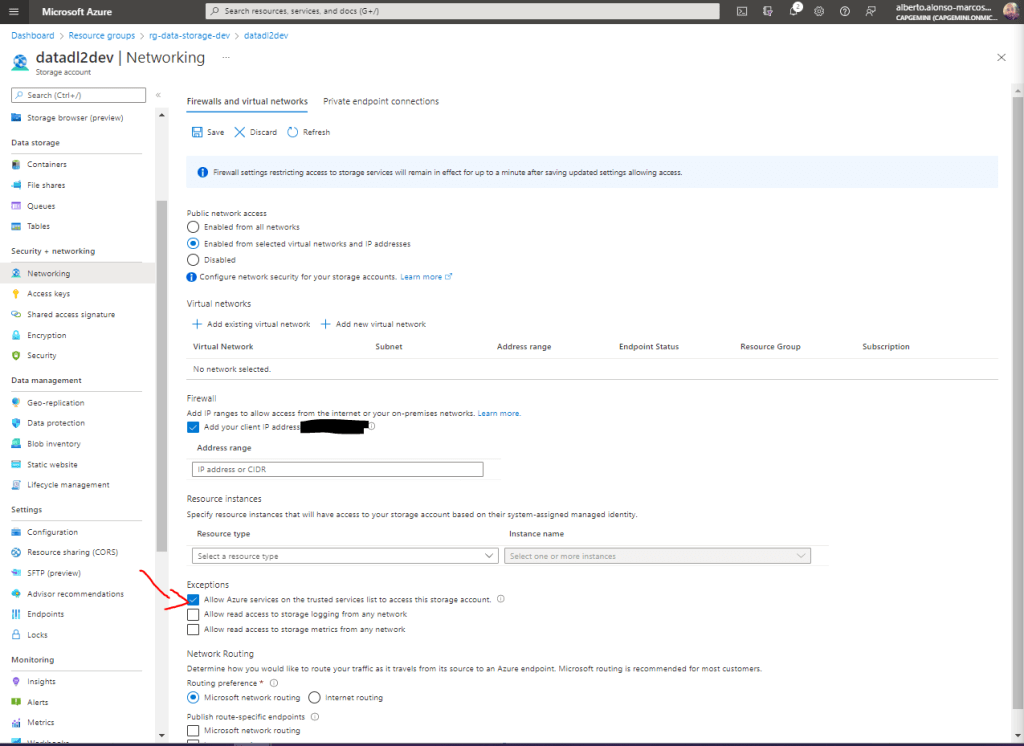
Recuerda configurar correctamente el Firewall de cara a que no interfiera en los procesos de Lifecycle Management. Para ello, en el caso de que el Firewall únicamente acepte un conjunto determinado de direcciones IP, recuerda marcar siempre la Excepción «Allow Azure services on the trusted services list to access this storage account«. Tal y como vemos en la imagen.
Del mismo modo, recordar que en Azure Data Lake Gen2 disponemos de tres tiers, cada uno con sus características propias, para de este modo, permitirnos elegir el tipo que mejor se adapte a nuestras necesidades o incluso generar reglas que realicen movimiento de datos entre ellos, una vez cumplido un tiempo previamente definido.
- Hot, optimizado para el almacenamiento de los datos que son consultados frecuentemente.
- Cool, optimizado para almacenar datos por al menos 30 días y que son accedidos infrecuentemente.
- Archive, optimizado para almacenar datos por al menos 180 días y que son raramente accedidos.
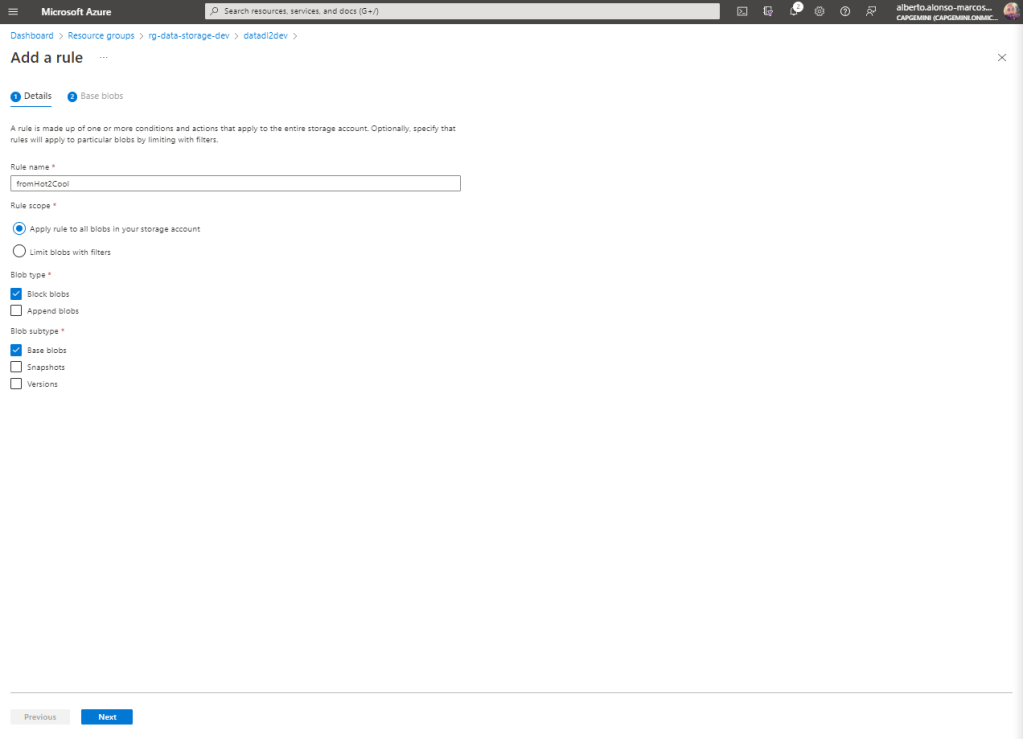
En este primera regla vamos a ejecutar el movimiento de fichero desde Hot hasta Cool tras pasar un periodo de 30 días. Para ello, completamos la primer a de las pantallas dando nombre a la regla y definiendo el scope, tipo de blob e incluso el subtipo.
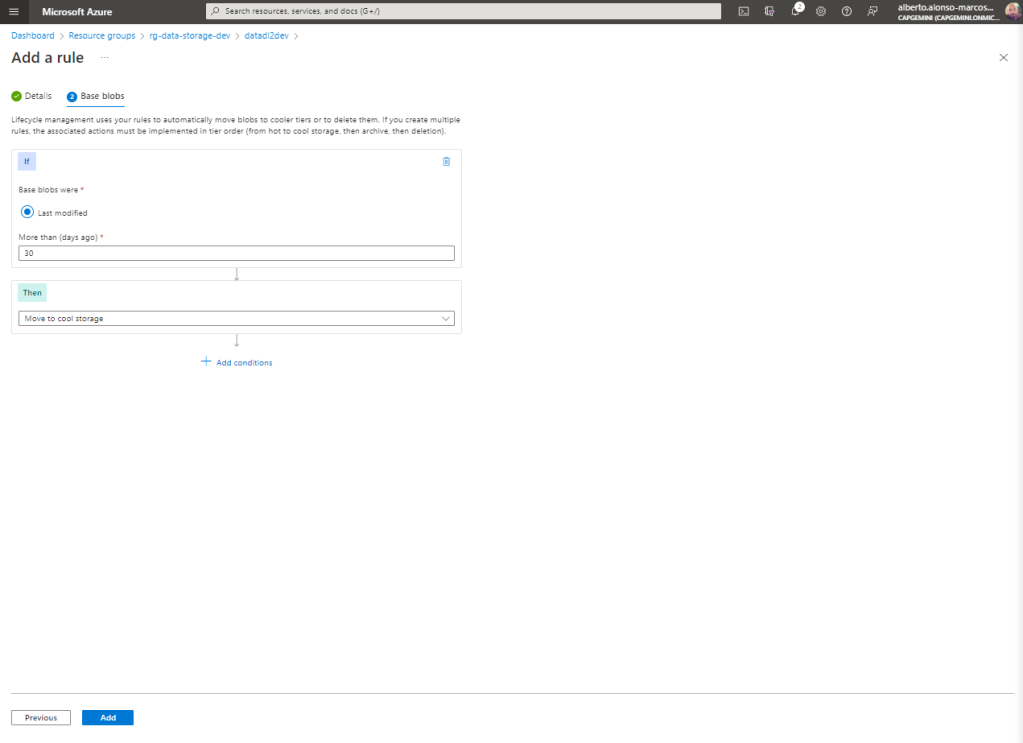
Para acto seguido crear la condición, definiendo el periodo y el tipo de acción.
Con respecto al segundo punto, los métodos de acceso al dato, voy a excluir los típicos de Shared Access Key y Shared Access Token puesto que tienen una grave limitación de seguridad respecto a su revocación, para centrarme en las diferencias entre Azure RBAC y ACL o Azure Control List. Veamos
Como muchos sabemos, para dar de alta la aplicación que acceda a nuestro recursos debemos incluirla en en Service Principal de nuestro Active Directory, lo que nos permitirá habilitar el acceso mediante RBAC y de este modo acceder a la recurso en su totalidad o bien habilitar ACL para limitar el acceso a nivel de ficheros o directorios. Es por ello, que debemos conocer el nivel de granularidad requerido para construir la mejor solución.
En el caso de ACL, como he indicado un poco más arriba, podemos configurar el acceso al directorio o incluso al fichero.

TIPS
Es muy recomendable generar un nuevo grupo en el Active Directory, para de este modo asignar los permisos de lectura, escritura y ejecución para, a posteriori, manejar los usuarios y aplicaciones directamente en dicho grupo.
CONCLUSIÓN
Me resulta muy interesante toda la parte de inmutabilidad del registro, puesto que evita un mal mayor como el borrado accidental de información. Así que espero que Microsoft lo ponga pronto en disponibilidad general. Y finalmente, me ha gustado la posibilidad de trabajar con ACL de cara a poder manejar de mejor modo los permisos de acceso a la información eliminando el problema de la revocación de acceso previamente comentado.
