
Durante años, muchas plataformas de datos han prometido ser abiertas. Sin embargo, en la práctica, la apertura solía quedarse en la capacidad de importar o exportar datos, no en compartirlos de forma nativa, gobernada y segura entre distintos motores y soluciones.
La madurez de Apache Iceberg como formato abierto y su adopción por plataformas como Snowflake y Microsoft Fabric marca un punto de inflexión: por primera vez es posible diseñar arquitecturas de datos verdaderamente interoperables, sin renunciar al gobierno, la seguridad ni el rendimiento.
En este artículo explico cómo y por qué Apache Iceberg sobre Snowflake se convierte en una pieza clave para arquitecturas multicloud y multitecnología, y cómo la colaboración con Microsoft Fabric amplía de forma natural los casos de negocio, incluyendo escenarios avanzados como Master Data Management (MDM).
Step-by-Step
Arquitectura y objetivos
Se usará Apache Iceberg en Snowflake para almacenar los datos en Azure Data Lake Gen2 mediante un External Volume (requisito de Iceberg en Snowflake). Snowflake actúa como Iceberg catalog y escribe / lee los metadatos de Iceberg en tu contenedor ADLS.
Se aplicará gobernanza con Snowflake Horizon Catalog:
- Clasificación / etiquetado de campos sensibles
- Dynamic Data Masking (enmascarado dinámico a nivel de columna)
- Row Access Policies (filtrado por filas)
Se consumirá la tabla desde:
- Notebook externo con Snowflake Connector for Python / Snowpark.
- Notebook de Microsoft Fabric instalando la librería de Snowflake en el entorno del workspace.
❗NOTA: si en el futuro quisieras permitir lectura / escritura desde otros motores Spark directamente sobre tablas Iceberg con políticas de Horizon aplicadas, revisa la guía de enforcement de políticas a través de Horizon + Spark Connector
Prerequisitos
- Almacenamiento Azure
Un contenedor ADLS Gen2 donde residan los datos + metadatos Iceberg. Habilita versioning en la cuenta de almacenamiento si quieres facilitar recovery. - Snowflake
Rol con privilegios para crear EXTERNAL VOLUME, DATABASE, SCHEMA, políticas y tablas Iceberg
Warehouse en ejecución (requisito al crear tablas Iceberg). - Cliente Python
snowflake-connector-python o snowflake.snowpark-python instalado - Notebook de Fabric
Permiso para gestionar librerías del entorno y usas %pip o publicar la dependencia en el Environment del workspace.
Creación del ADLS
Lo primero que se debe hacer es crear un Azure Data Lake Gen2 con un contenedor, en este caso, el contenedor tiene el nombre de «demo».
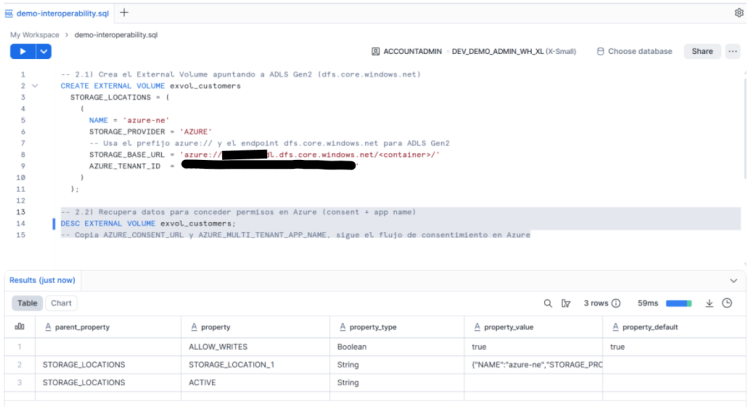
El siguiente paso es, desde Snowflake, crear un EXTERNAL VOLUME mediante este código de SQL.
-- Crea el External Volume apuntando a ADLS Gen2 (dfs.core.windows.net)CREATE OR REPLACE EXTERNAL VOLUME exvol_customers STORAGE_LOCATIONS = ( ( NAME = 'azure-ne' STORAGE_PROVIDER = 'AZURE' -- Usa el prefijo azure:// y el endpoint dfs.core.windows.net para ADLS Gen2 STORAGE_BASE_URL = 'azure://nombre_adls.dfs.core.windows.net/nombre_contenedor/' AZURE_TENANT_ID = 'incluye tu tenant id' ) );-- Recupera datos para conceder permisos en Azure (consent + app name)DESC EXTERNAL VOLUME exvol_customers;-- Copia AZURE_CONSENT_URL y AZURE_MULTI_TENANT_APP_NAME, sigue el flujo de consentimiento en Azure
❗NOTA: en la imagen se ejecuta la instrucción de descripción del recién creado volumen externo para obtener la URL desde la que se gestiona la creación del Service Principal asociado.
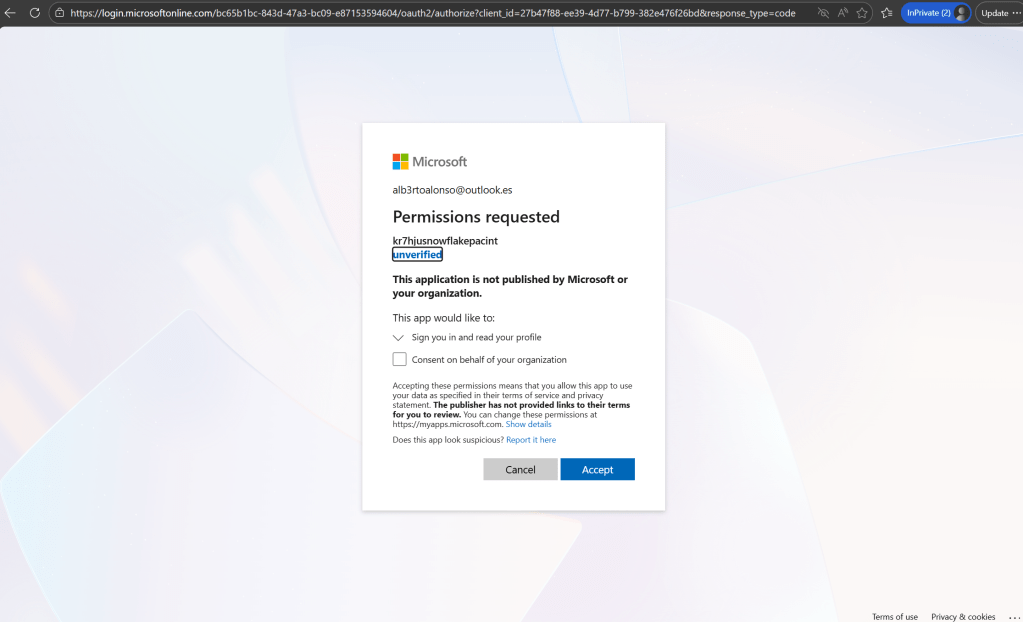
Conceder permisos al Service Principal
Para ello, lo primero es ir al enlace AZURE_CONSENT_URL que contiene el JSON de property_value que se obtiene al ejecutar la sentencia previa. El enlace abre una página de Microsoft para conceder permisos al Service Principal generado por Snowflake. Al aceptar, Snowflake queda autorizado a obtener tokens pero todavía no tiene permisos de acceso al Storage.
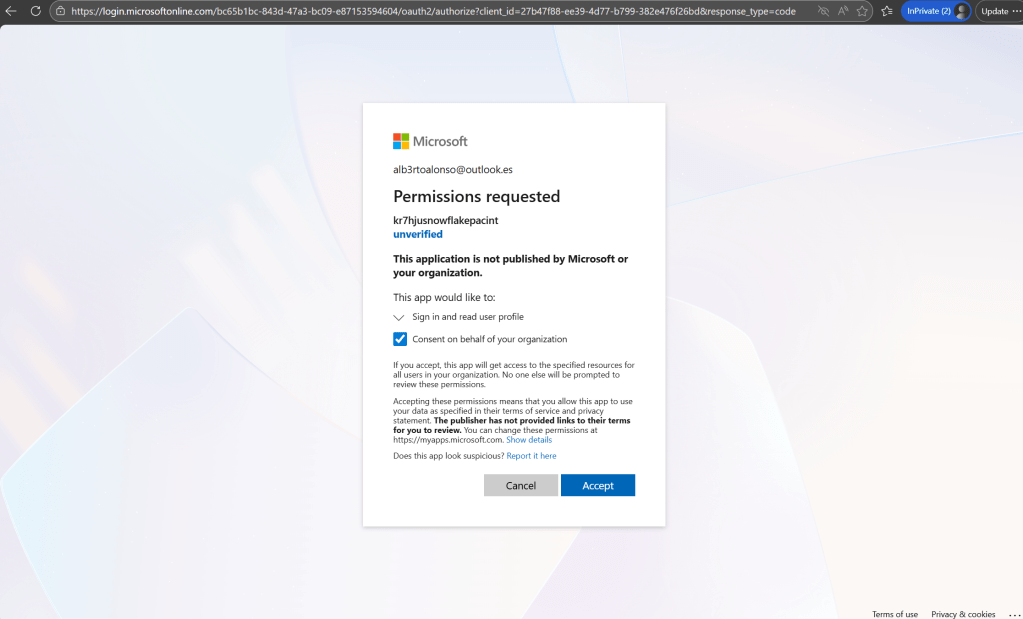
Se selecciona el consentimiento y se pulsa «Aceptar»
Dar permisos en Azure Storage (tu parte manual)
El siguiente paso es asignar el rol de Storage Blob Data Contributor al recién creado Service principal en el Azure Portal. Para ello, se pueden seguir los siguientes pasos:
- Ir a Storage Account > Access Control (IAM)
- Agregar asignación de rol
- Rol: Storage Blob Data Contributor
- Miembro: Buscar por el nombre mostrado en
AZURE_MULTI_TENANT_APP_NAME- ❗Puede tardar hasta 60–90 minutos en aparecer (proceso documentado por Microsoft).
- Guardar.
Con eso, el Service Principal creado por Snowflake ya puede leer/escribir en tu contenedor. ¡Lo tendremos!
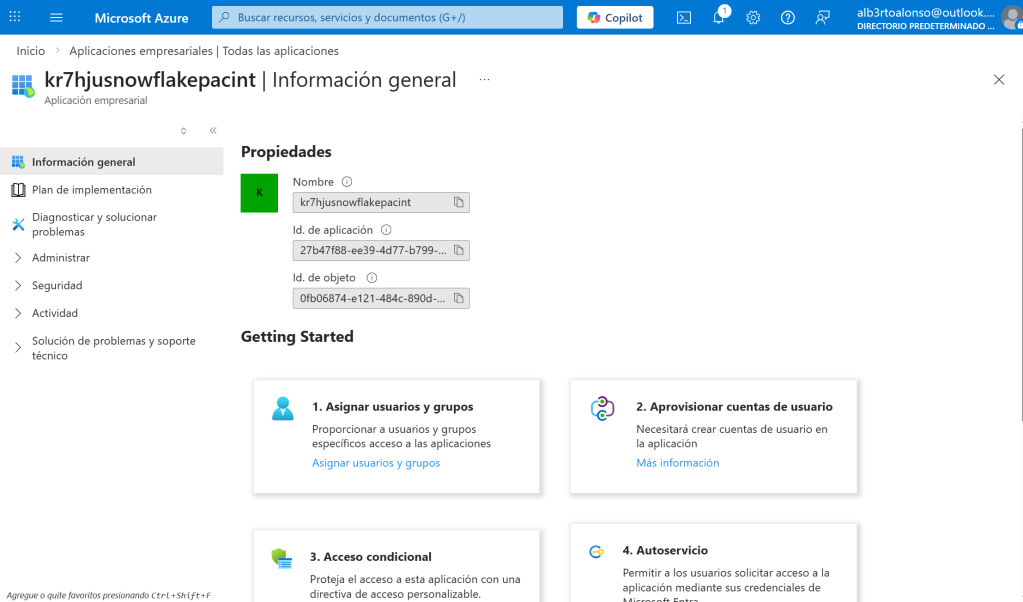
Aquí se observa cómo vincular el rol correspodiente con el Service Principal.
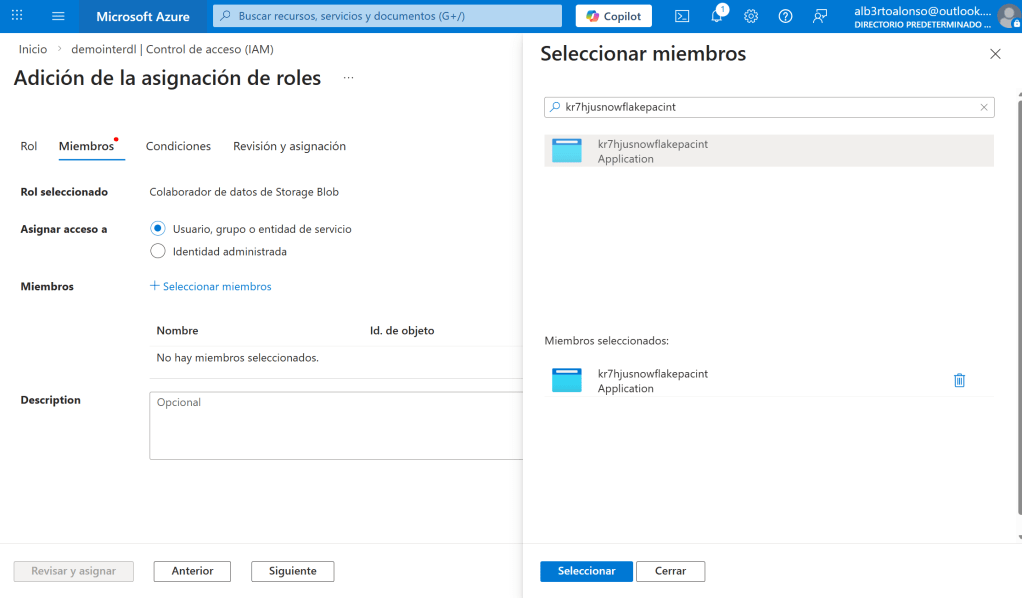
Verificar desde Snowflake
Tras la asignación del rol a Service Principal, toca validar desde Snowflake que realmente se ha habilitado el volumen externo. Para ello, se ejecuta el siguiente código
SELECT SYSTEM$VERIFY_EXTERNAL_VOLUME('exvol_customers');
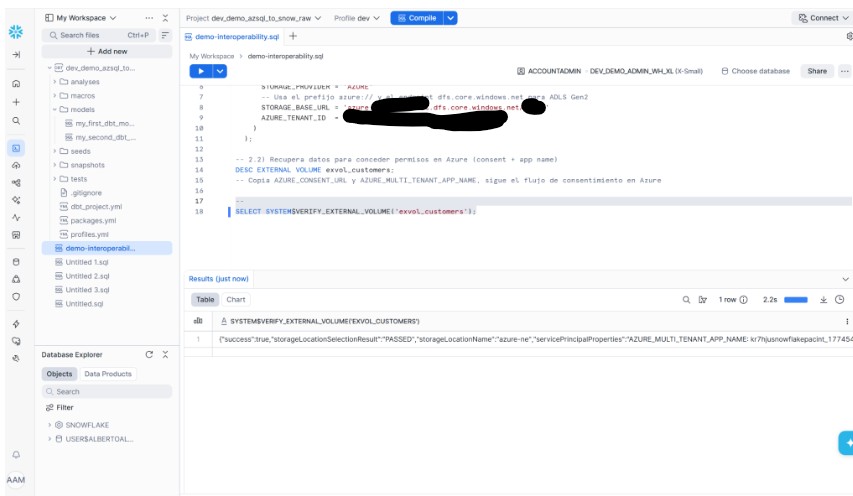
Si todo es correcto → Snowflake ya puede trabajar con Iceberg en tu almacenamiento.
Creación de recursos desde Snowflake
Lo primero es crear la estructura lógica en Snowflake (DB/Schema/Warehouse). Para ello, se comparte este código de ejemplo.
-- Usa/crea un warehouse para la sesiónCREATE WAREHOUSE IF NOT EXISTS WH_ICEBERG_XS WITH WAREHOUSE_SIZE = 'XSMALL' AUTO_SUSPEND = 60;USE WAREHOUSE WH_ICEBERG_XS;-- Crea DB/Schema de trabajoCREATE DATABASE IF NOT EXISTS DEMO_ICEBERG;CREATE SCHEMA IF NOT EXISTS DEMO_ICEBERG.CUSTOMER360;USE DATABASE DEMO_ICEBERG;USE SCHEMA CUSTOMER360;
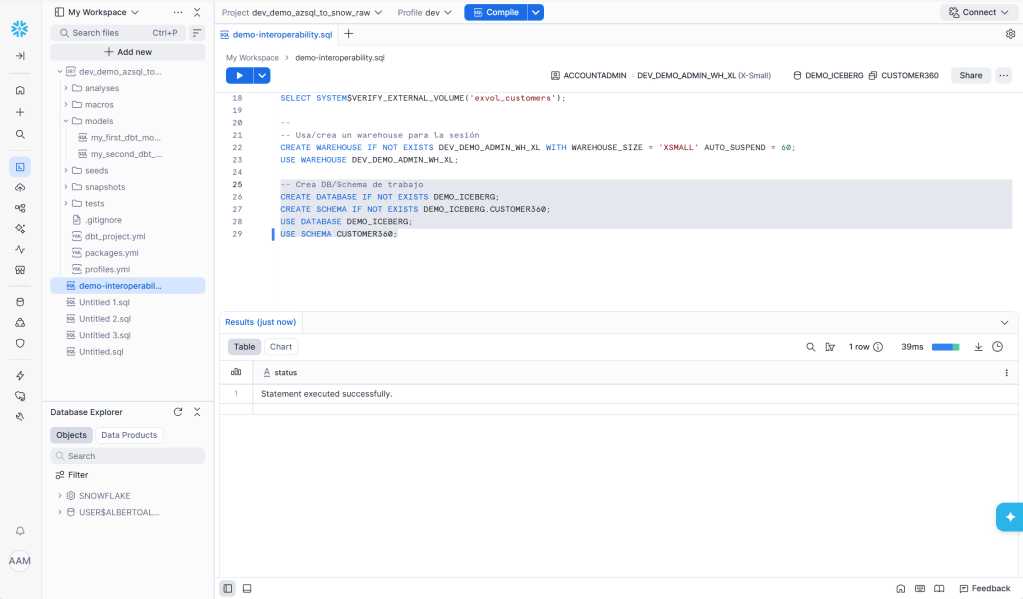
NOTA: Las tablas Iceberg requieren warehouse activo en la sesión al crearlas.
Gobernanza con Horizon Catalog: etiquetas, enmascarado y acceso por filas
Etiquetas (tags) para PII
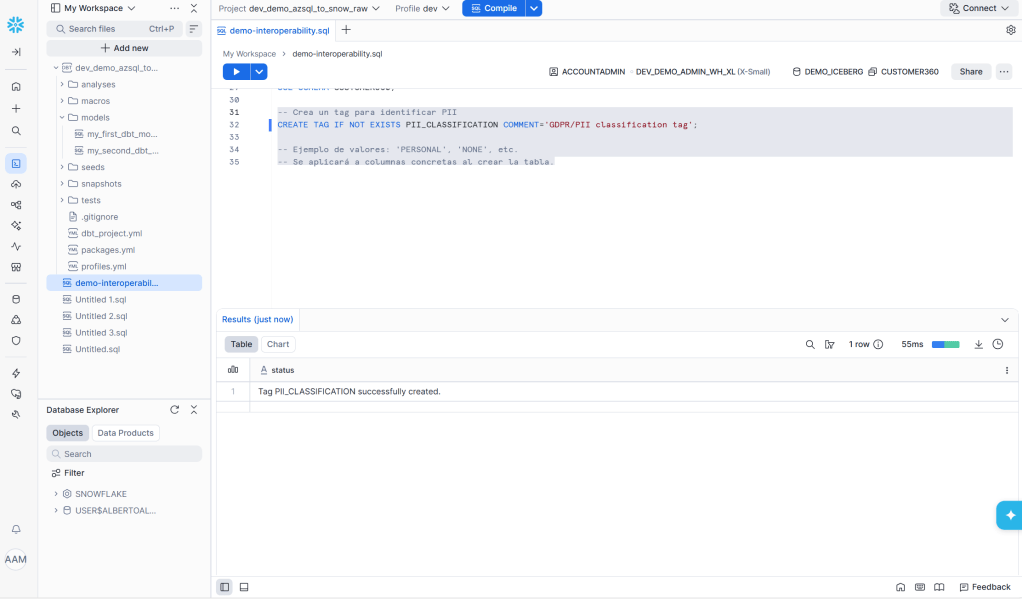
Mediante el siguiente código se crea una etiqueta que se reutilizará para «marcar» atributos clasificados como PII que se quieran identificar en nuestros activos de datos. Para ello, se comparte este ejemplo de código
-- Crea un tag para identificar PIICREATE TAG IF NOT EXISTS PII_CLASSIFICATION COMMENT='GDPR/PII classification tag';-- Ejemplo de valores: 'PERSONAL', 'NONE', etc.-- Se aplicará a columnas concretas al crear la tabla.
Horizon centraliza metadatos, búsqueda, linaje y políticas (máscaras/row access) y las aplica de forma consistente también sobre Iceberg
Dynamic Data Masking (correo/teléfono)
La idea es crear un rol con permisos para consultar los registros sin máscara con el nombre de DATA_STEWARD
-- Rol opcional para administración de políticasCREATE ROLE IF NOT EXISTS MASKING_ADMIN;GRANT APPLY MASKING POLICY ON ACCOUNT TO ROLE MASKING_ADMIN;-- Role para la visualización de los registros sin máscaraCREATE ROLE IF NOT EXISTS DATA_STEWARD;GRANT APPLY MASKING POLICY ON ACCOUNT TO ROLE DATA_STEWARD;-- Policy que muestra correo completo a roles autorizados y máscara al restoCREATE OR REPLACE MASKING POLICY EMAIL_MASK_POLICY AS (val STRING) RETURNS STRING -> CASE WHEN IS_ROLE_IN_SESSION('DATA_STEWARD') THEN val ELSE REGEXP_REPLACE(val, '(^.).+(@.*$)', '\\1***\\2') END;-- Policy para teléfono: deja últimos 4 dígitos visiblesCREATE OR REPLACE MASKING POLICY PHONE_MASK_POLICY AS (val STRING) RETURNS STRING -> CASE WHEN IS_ROLE_IN_SESSION('DATA_STEWARD') THEN val ELSE REPEAT('*', GREATEST(LENGTH(val) - 4, 0)) || RIGHT(val, 4) END;
❗NOTA: Recuerda que debes asignar ese rol con tu usuario para poder ejecutar las consultas visualizando los registros sin la máscara.
Crear la tabla Iceberg CUSTOMERS (Snowflake como catálogo)
Se usará el tipo Iceberg (Snowflake mapea a sus tipos internos preservando interoperabilidad) y aplicaremos tags y masking en la creación
-- Crear tabla Iceberg en ADLS Gen2 con partición por paísCREATE OR REPLACE ICEBERG TABLE CUSTOMER ( CUSTOMER_ID LONG NOT NULL, FULL_NAME STRING NOT NULL, EMAIL STRING WITH MASKING POLICY EMAIL_MASK_POLICY TAG (PII_CLASSIFICATION = 'PERSONAL'), PHONE STRING WITH MASKING POLICY PHONE_MASK_POLICY TAG (PII_CLASSIFICATION = 'PERSONAL'), COUNTRY STRING NOT NULL, SIGNUP_DATE DATE, IS_ACTIVE BOOLEAN)PARTITION BY (COUNTRY)CATALOG = 'SNOWFLAKE'EXTERNAL_VOLUME = 'exvol_customers'BASE_LOCATION = 'customers/'; -- subcarpeta dentro del contenedor-- Cargar algunos registros de ejemploINSERT INTO CUSTOMERS (CUSTOMER_ID, FULL_NAME, EMAIL, PHONE, COUNTRY, SIGNUP_DATE, IS_ACTIVE) VALUES (1, 'Ana López', 'ana.lopez@example.com', '+34-600-111-222', 'ES', '2024-11-02', TRUE), (2, 'Jean Martin','jean.martin@example.fr', '+33-700-333-444', 'FR', '2025-01-15', TRUE), (3, 'Luis Pérez', 'luis.perez@example.com', '+34-600-555-666', 'ES', '2025-02-20', FALSE);-- VerificaciónSHOW ICEBERG TABLES IN SCHEMA DEMO_ICEBERG.CUSTOMER360;SELECT * FROM CUSTOMERS LIMIT 10;
Se consulta la tabla con cualquiera de los ROLES dosponibles excepto el de DATA_STEWARD y el resultado es el siguiente:
SELECT CUSTOMER_ID, EMAIL, PHONE, COUNTRY FROM DEMO_ICEBERG.CUSTOMER360.CUSTOMER ORDER BY CUSTOMER_ID;

Mientras que si el ROL empleado es DATA_STEWARD el resultado no tendrá campos enmascarados
USE ROLE DATA_STEWARD;SELECT CUSTOMER_ID, EMAIL, PHONE, COUNTRY FROM DEMO_ICEBERG.CUSTOMER360.CUSTOMER ORDER BY CUSTOMER_ID;

En el siguiente capítulo, se habilitará la conectividad desde un Notebook al volumen externo gobernado por Horizon en Azure. ¡No te lo puedes perder!
Foto de portada gracias a Brett Sayles: https://www.pexels.com/es-es/foto/cable-de-conexion-cables-alambres-mantenimiento-de-cable-panel-de-parche-4682189/
