
En este segundo capítulo, se realiza un ejercicio completo para conectar un Jupyter Notebook en local con el EXTERNAL VOLUME de ADLS gobernado por Snowflake para validar que se puede, no sólo leer la información sino que también escribir. Por supuesto, aplicando la capa de seguridad mediante las etiquetas de confidencialidad y máscara dinámica en función de los roles.
Instalar Snowflake Connector
Lo primero es instalar el conector de Snowflake, Para ello, se debe emplear (en mi caso) Conda Prompt y la instrucción pip.
pip install snowflake-connector-python# (opcional) pip install snowflake-snowpark-python
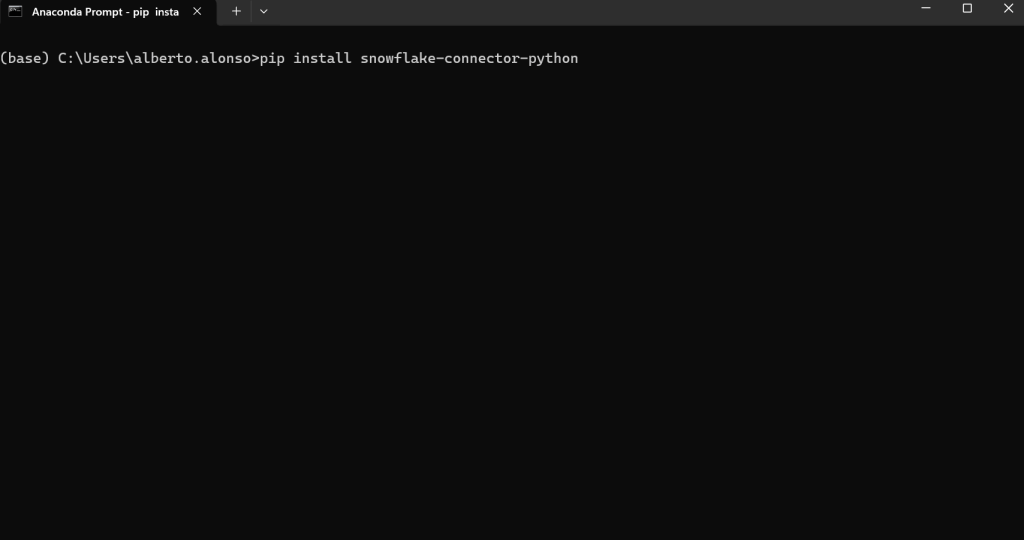
Se ejecuta el proceso y se instalan todos los elementos necesarios para realizar el ejercicio.
NOTA: recuerda que siempre es recomendable instalar estas librerías sobre entornos creados exclusivamente para tal fin y evitar usar el entorno <base>. Te recuerdo los pasos a seguir para ello.
Crear tu propio entorno en Anaconda
1️⃣ Activar el entorno
conda activate snow
2️⃣ Instalar ipykernel en ese entorno
conda install ipykernel -y
3️⃣ Registrar el entorno como kernel de Jupyter
python -m ipykernel install --user --name snow --display-name "snow"
4️⃣ Abrir Jupyter Notebook
jupyter notebook
Habilitando la conexión de la tabla CUSTOMER en Apache Iceberg
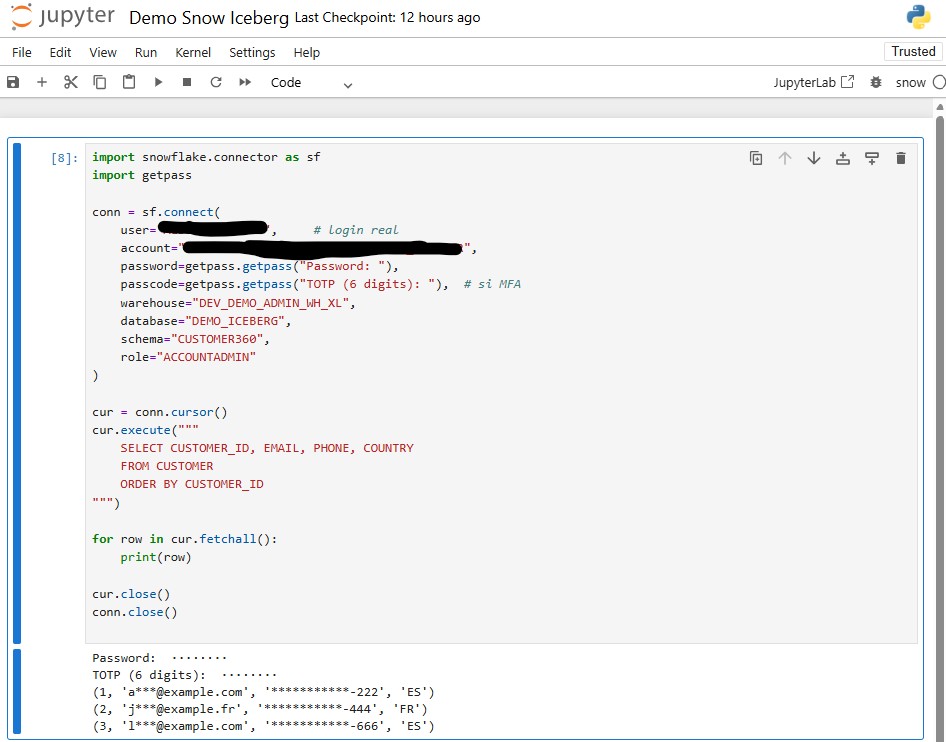
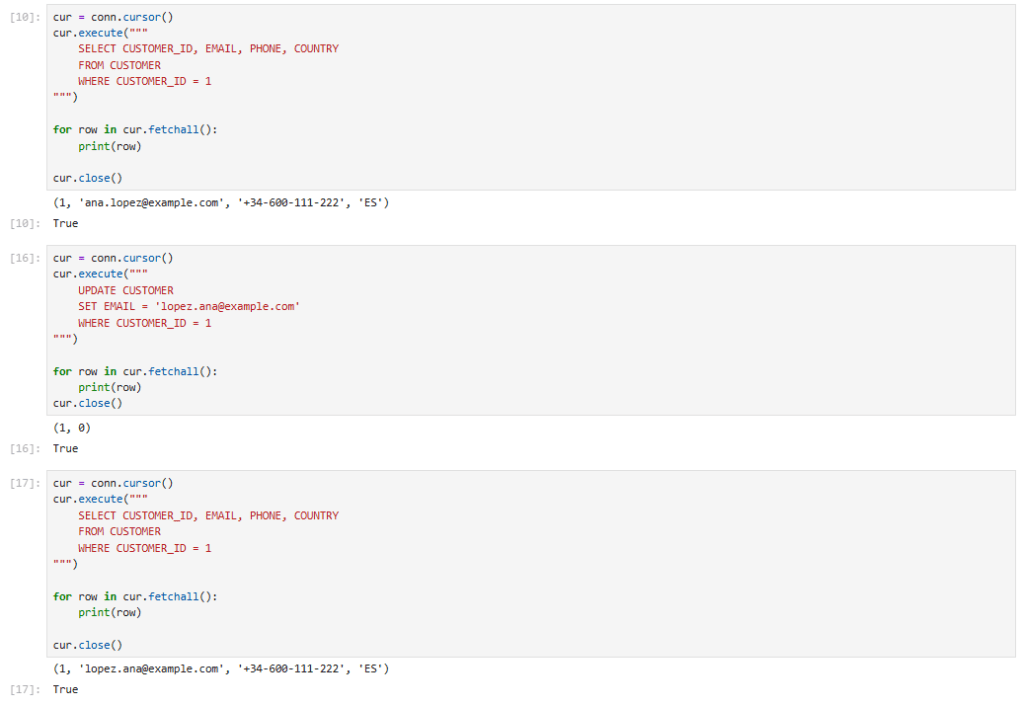
import snowflake.connector as sfimport getpassconn = sf.connect( user="SNOWFLAKE_USER", # login real account="SNOWFLAKE_ACCOUNT", password=getpass.getpass("Password: "), passcode=getpass.getpass("TOTP (6 digits): "), # si MFA warehouse="DEV_DEMO_ADMIN_WH_XL", database="DEMO_ICEBERG", schema="CUSTOMER360", role="ACCOUNTADMIN")cur = conn.cursor()cur.execute(""" SELECT CUSTOMER_ID, EMAIL, PHONE, COUNTRY FROM CUSTOMER ORDER BY CUSTOMER_ID""")for row in cur.fetchall(): print(row)cur.close()conn.close()
En el paso previo se pide tanto el password del usuario como el código que devuelve el MFA. Una vez se han validado los permisos, se muestra el resultado de la consulta.
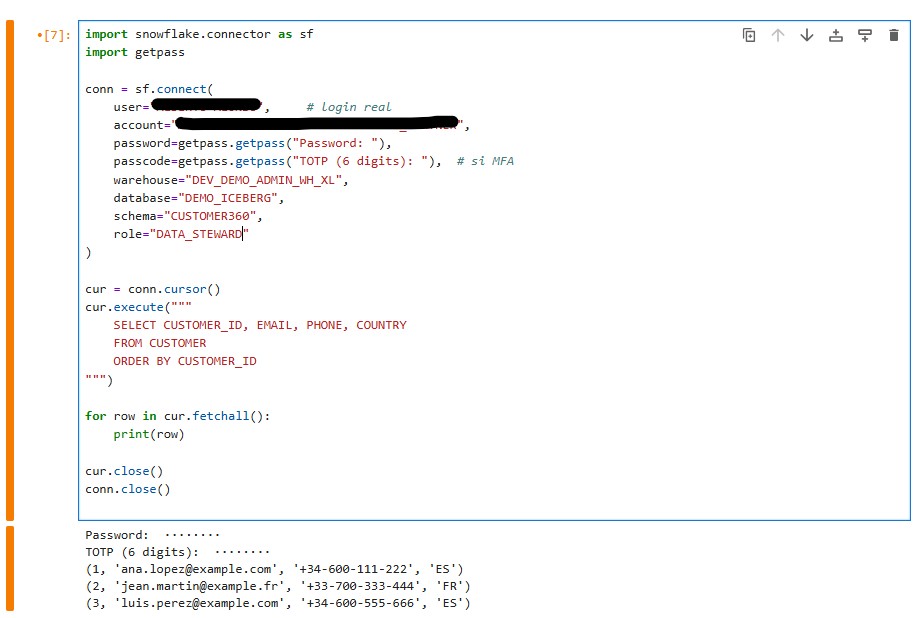
En caso de ejercutar la misma QUERY con el rol de DATA_STEWARD, el resultado es que se visualizan los registros sin máscara, tal y como se aprecia en la captura de abajo.
El siguiente paso es el de realizar una actualización sobre uno de los registros. En concreto sobre el de el cliente: «Ana López». Y vemos que con esta configuración desde un motor externo se puede leer y escribir sobre formato Apache Iceberg manteniendo el gobierno y la seguridad de los datos.
Ahora un poco de teoría para aprender un poco más acerca de Apache Iceberg.
Por qué Iceberg y los formatos abiertos cambian las reglas del juego
Apache Iceberg no es “otro formato más”. Es el contrato común que permite que distintos motores y plataformas trabajen sobre los mismos datos, con:
- Transacciones ACID
- Evolución de esquema controlada
- Metadatos explícitos y versionados
- Independencia entre almacenamiento y cómputo
Esto rompe un paradigma histórico: los datos dejan de “pertenecer” a una herramienta concreta.
Cuando Snowflake, Fabric, Spark u otros motores leen y escriben sobre el mismo formato abierto, el foco vuelve a donde debe estar: 👉 el dato, su significado y su gobierno, no la herramienta.
En los siguientes capítulos está pendiente habilitar lectura / escritura desde Microsoft Fabric y crear un Open Catalog para utilizar Iceberg REST.
Foto de portada gracias a Fernando Narvaez: https://www.pexels.com/es-es/foto/sala-de-control-avanzado-en-el-agustino-lima-32529341/
