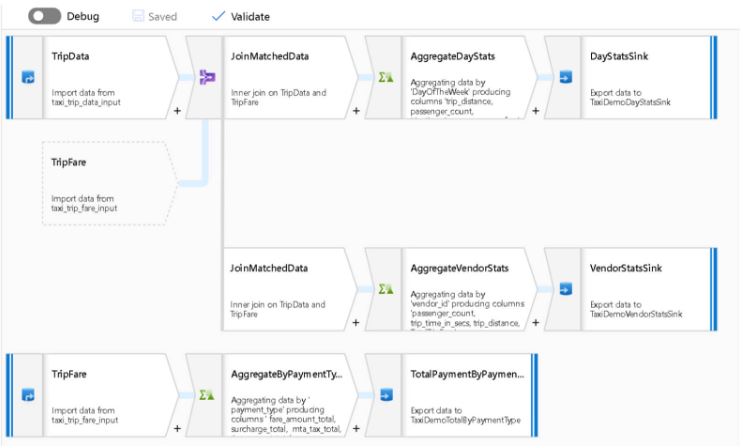
En este artículo vamos a describir en detalle los pasos a seguir para completar el despliegue automático de pipelines de Azure Data Factory en los entornos de Desarrollo (dev), Staging (stg) y Producción (prd). En desarrollo de software, el uso de la integración (CI) y el despliegue continuo (CD) se realiza para liberar mejor código de un modo rápido. Esta posibilidad existe también para los ingenieros de datos que trabajan con Azure Data Factory. Es decir, tendremos la posibilidad de mover pipelines entre los distintos entornos. Además, trabajando de este modo, varias personas del equipo podrán estar trabajando al mismo tiempo sobre el mismo data pipeline. En este caso, vamos a trabajar en un ejemplo de automatización del despliegue desde dev hasta prd. Todo gracias a la integración de ADF con Azure DevOps Automation. Veamos cómo.
La infraestructura necesaria para completar este proceso es
- Azure Resource Group
- Azure Storage
- Azure Key Vault
- Azure Data Factory
- Azure DevOps
Y como ya hemos comentado previamente, todo lo tendremos que “repetir” en los tres entornos con los que trabajaremos: Desarrollo, Staging y Producción. En el primero, es donde desarrollaremos toda la parte de los pipelines de un modo colaborativo, entre los distintos componentes del equipo. El segundo sería para Quality Assurance o Testing, tiene por objetivo testear los pipelines comprobando que realmente hacen lo que deberían hacer. Por último en el entorno de Producción, vendría a representar el mundo real.
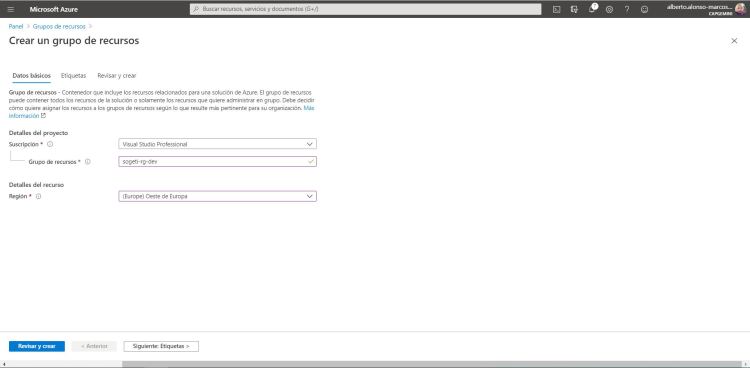
Creamos el primero grupo de recursos, en este caso para dev. Lo llamamos sogeti-reg-dev.
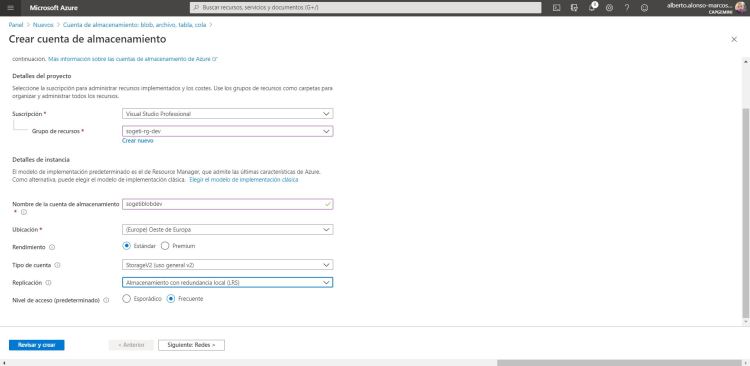
A partir de aquí, comenzamos a crear todos los componentes dentro de este grupo de recursos. Empezamos creando la cuenta de Azure Storage (sogetiblobdev), ten presente que para replicación sirve LRS.
Ya sólo nos queda provisionar dos containers (sink y staging).

Por último, y para completar esta primera parte, creamos una Azure Key Vault. La llamamos sogeti-key-dev.

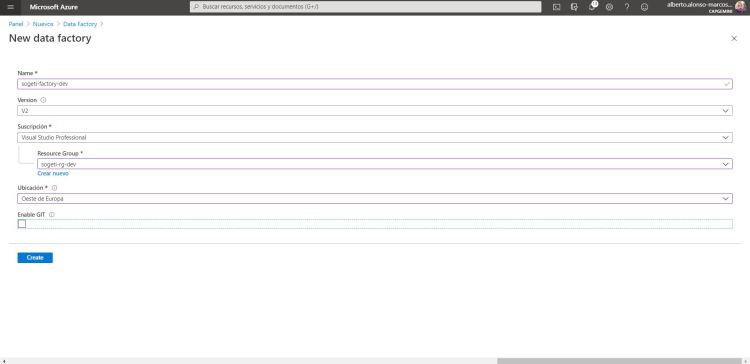
En la segunda parte, lo primero que debemos provisionar es la Azure Data Factory. El nombre que la daremos será sogeti-factory-dev. Y en este caso, dejaremos sin marcar la opción de GIT. Ya lo haremos más adelante.
Lo siguiente sería, copiar la cadena de conexión del Azure Blob Storage del entorno de dev y crear un secreto en la Azure Key Vault, con el nombre de storage-access-key. Esta es una buena práctica de cara a no publicar información sensible.

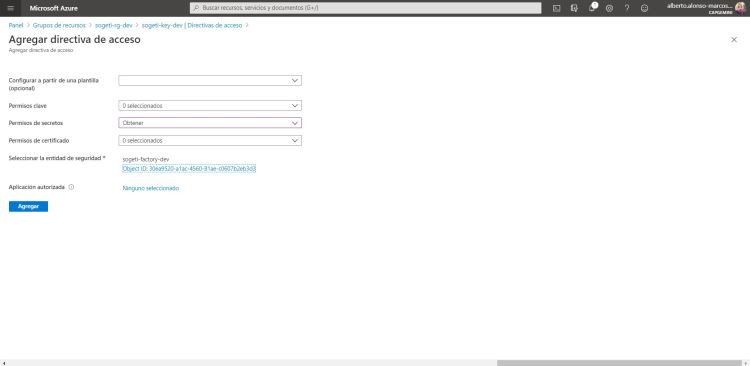
En el siguiente paso, añado una política de acceso. En este caso, con el permiso de secretos de obtener. Siendo nuestra sogeti-factory-dev, la entidad de seguridad seleccionada.
Hasta aquí los primeros pasos del despliegue automático de pipelines utilizando Azure DevOps y Azure Data Factory. En unos días, la parte 2.
