
En este artículo vamos a describir en detalle los pasos a seguir para completar el despliegue automático de pipelines de Azure Data Factory en los entornos de Desarrollo (dev), Staging (stg) y Producción (prd). En desarrollo de software, el uso de la integración (CI) y el despliegue continuo (CD) se realiza para liberar mejor código de un modo rápido. Esta posibilidad existe también para los ingenieros de datos que trabajan con Azure Data Factory. Es decir, tendremos la posibilidad de mover pipelines entre los distintos entornos. Además, trabajando de este modo, varias personas del equipo podrán estar trabajando al mismo tiempo sobre el mismo data pipeline. En este caso, vamos a trabajar en un ejemplo de automatización del despliegue desde dev hasta prd. Todo gracias a la integración de ADF con Azure DevOps Automation. Veamos cómo
La infraestructura necesaria para completar este proceso es
- Azure Resource Group
- Azure SQL Database
- Azure Key Vault
- Azure Data Factory
- Azure DevOps
Y como ya hemos comentado previamente, todo lo tendremos que “repetir” en los tres entornos con los que trabajaremos: Desarrollo, Staging y Producción. En el primero, es donde desarrollaremos toda la parte de los pipelines de un modo colaborativo, entre los distintos componentes del equipo. El segundo sería para Quality Assurance o Testing, tiene por objetivo testear los pipelines comprobando que realmente hacen lo que deberían hacer. Por último en el entorno de Producción, vendría a representar el mundo real.
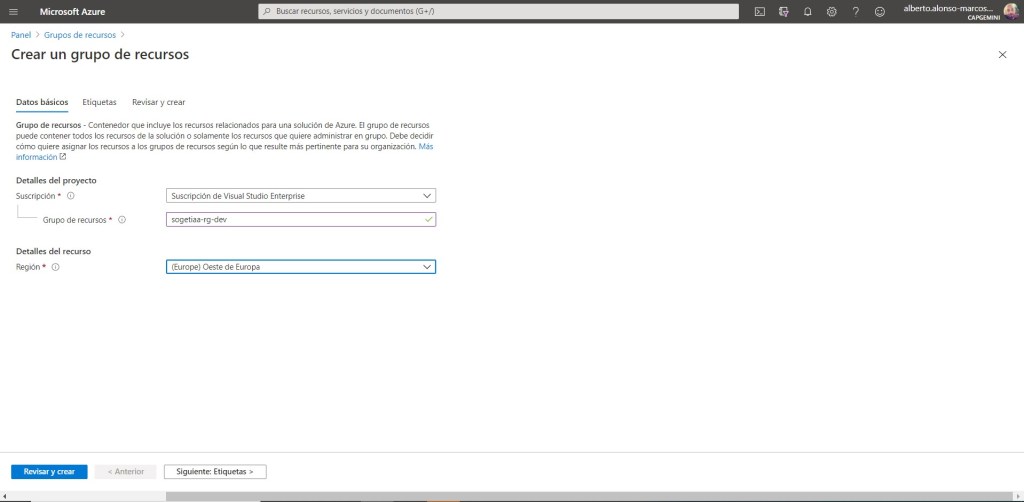
Creamos el primero grupo de recursos, en este caso para dev. Lo llamamos sogetiaa-rg-dev.
A partir de aquí, comenzamos a crear todos los componentes dentro de este grupo de recursos. Empezamos creando la base de datos sogetiaa-db-dev y su servidor sogetiaa-server-dev

Por último, y para completar esta primera parte, creamos una Azure Key Vault. La llamamos sogetiaa-key-dev.
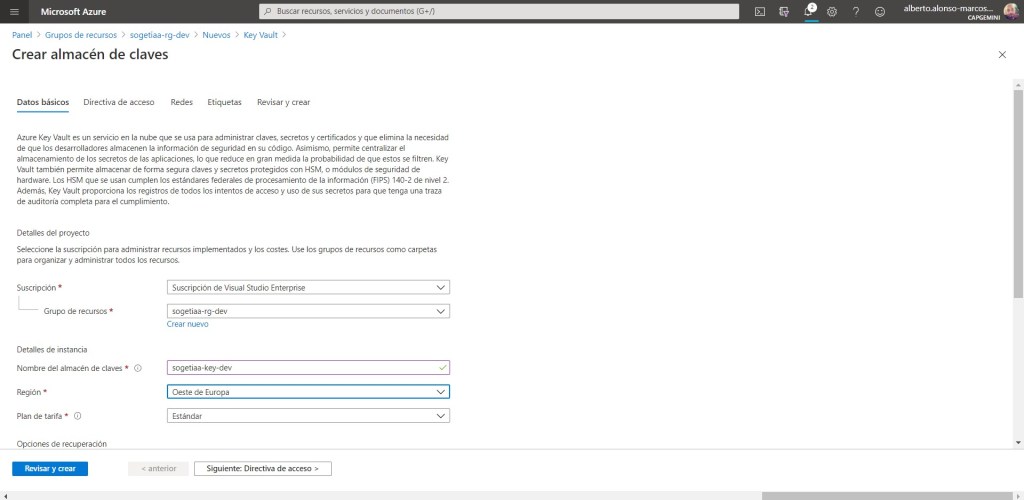
En la segunda parte, lo primero que debemos provisionar es la Azure Data Factory. El nombre que la daremos será sogetiaa-factory-dev. Y en este caso, dejaremos sin marcar la opción de GIT. Ya lo haremos más adelante.
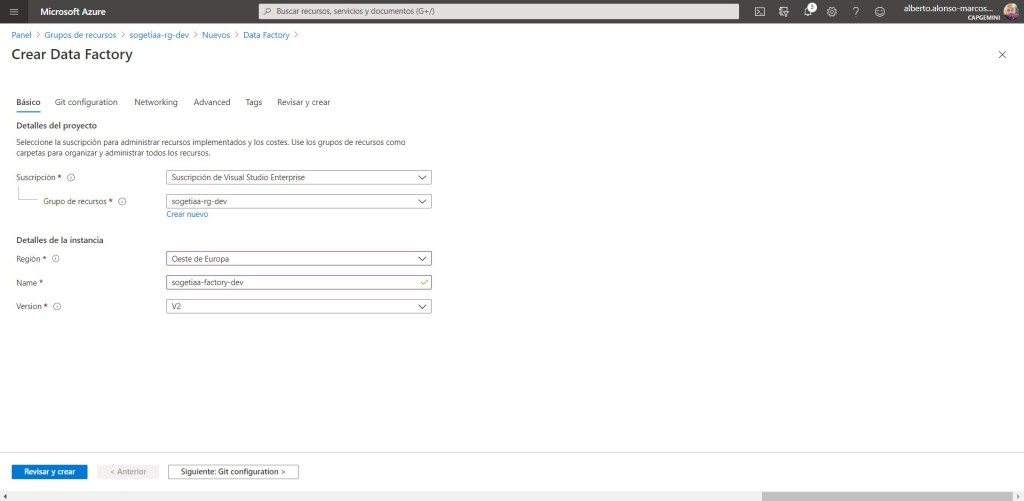
Lo siguiente sería, copiar la cadena de conexión de la Azure SQL Database del entorno de dev y crear un secreto en la Azure Key Vault, con el nombre de storage-access-key. Esta es una buena práctica de cara a no publicar información sensible
Copiamos la cadena de conexión de nuestra base de datos
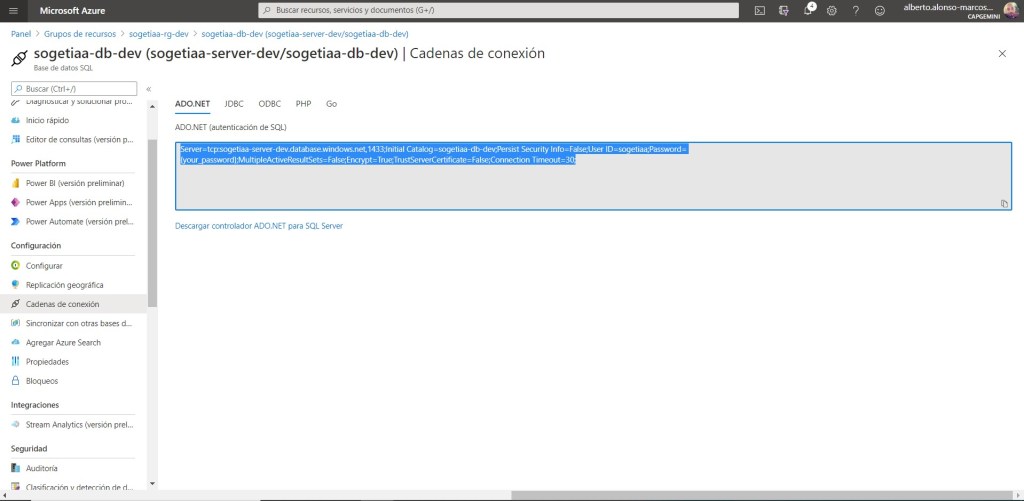
Y creamos el secreto añadiendo nuestra cadena de conexión.
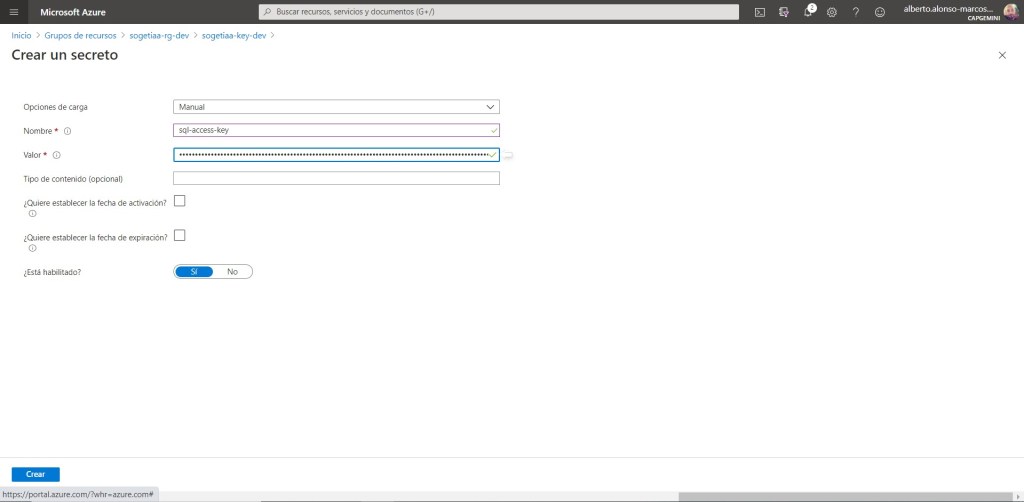
En el siguiente paso, añado una política de acceso. En este caso, con el permiso de secretos de obtener. Siendo nuestra sogetiaa-factory-dev, la entidad de seguridad seleccionada.
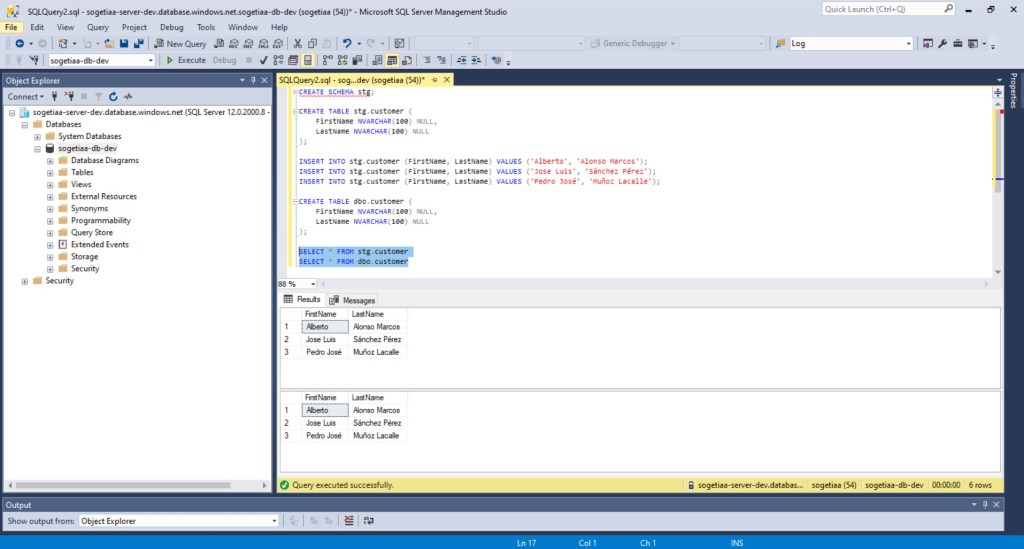
Ahora, en la base de datos creo un schema con nombre stg y la tabla customer tanto en el schema dbo como en el recién creado. En este último incluyo tres registros y compruebo que todo esté correcto.

Perfecto, ahora sólo queda comenzar con la creación del pipeline de Azure Data Factory, que nos permita pasar los datos de stg.customer a dbo.customer.
Para ello lo primero es crear un pipeline y un dataset de entrada.
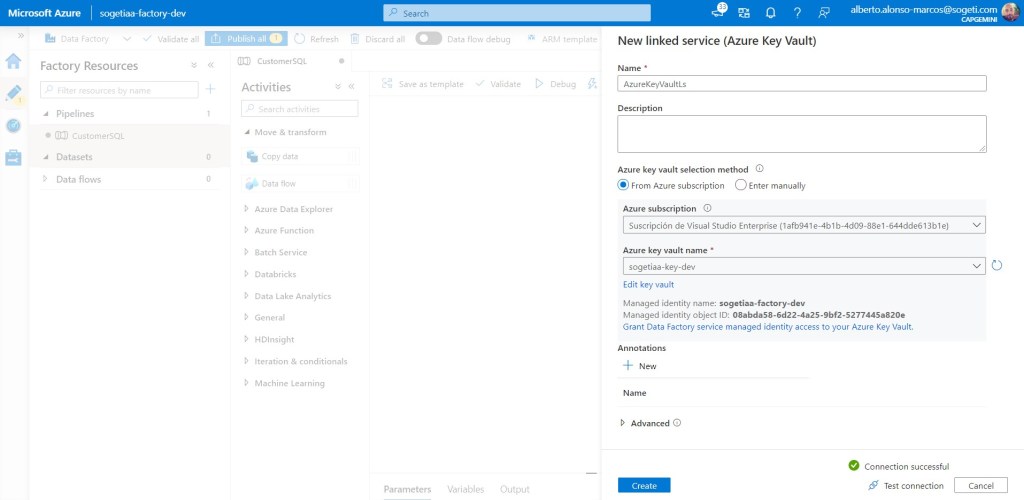
La implementación la realizaremos poniendo en juego el secreto que previamente guardamos en Azure Key Vault. Probamos la conexión del Linked Service creado entre ADF y nuestra cuenta de Azure Key Vault, y correcto. Podemos continuar.
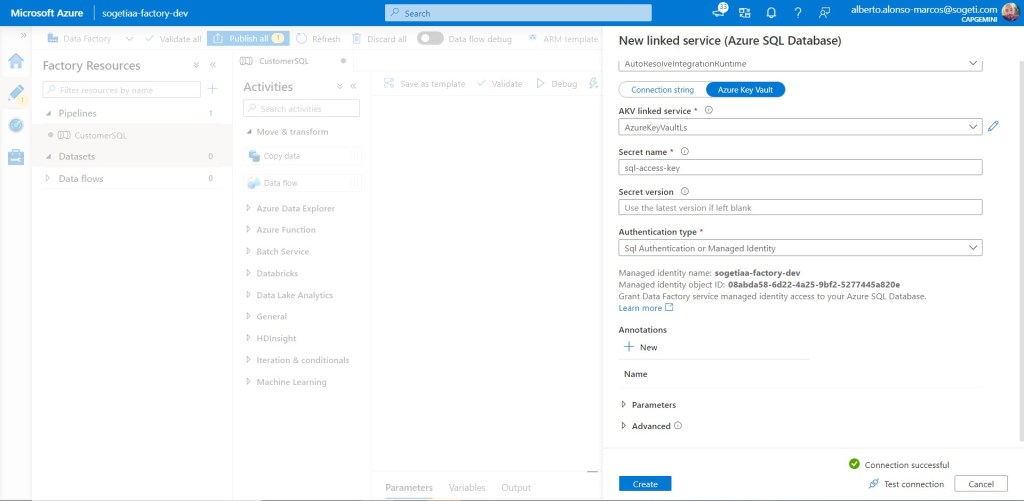
Ya sólo nos queda incluir el nombre del secreto que queremos utilizar desde nuestra cuenta de Azure Key Vault y listo. Probamos la conexión.
Ya únicamente nos quedaría indicar el nombre la de tabla de origen y al siguiente paso.

Comprobamos que todo esté correcto.

Repetimos el proceso para la tabla dbo.customer. Comprobamos.

Y en el pipeline incluimos la actividad de Copy Data. Configuramos la actividad indicando que el origen es mi tabla stg.customer.
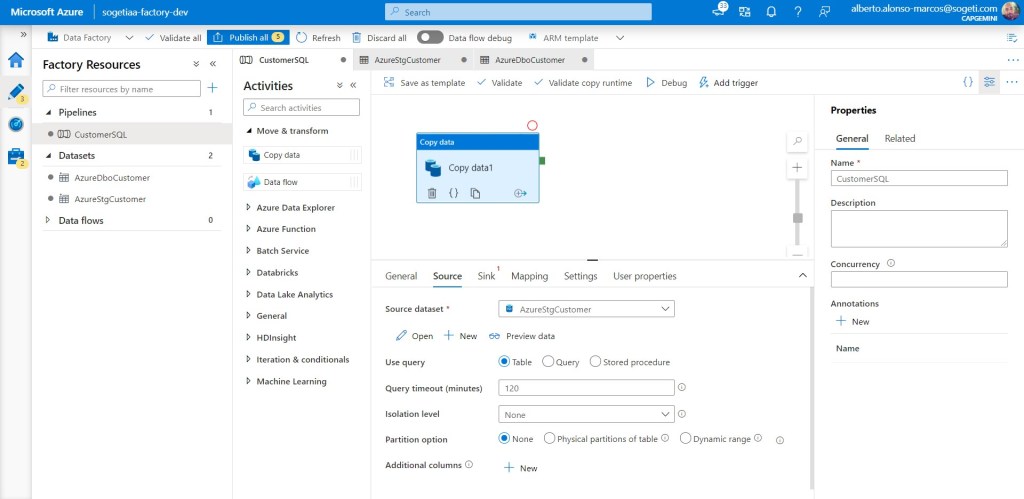
Y que el destino es la tabla dbo.customer.
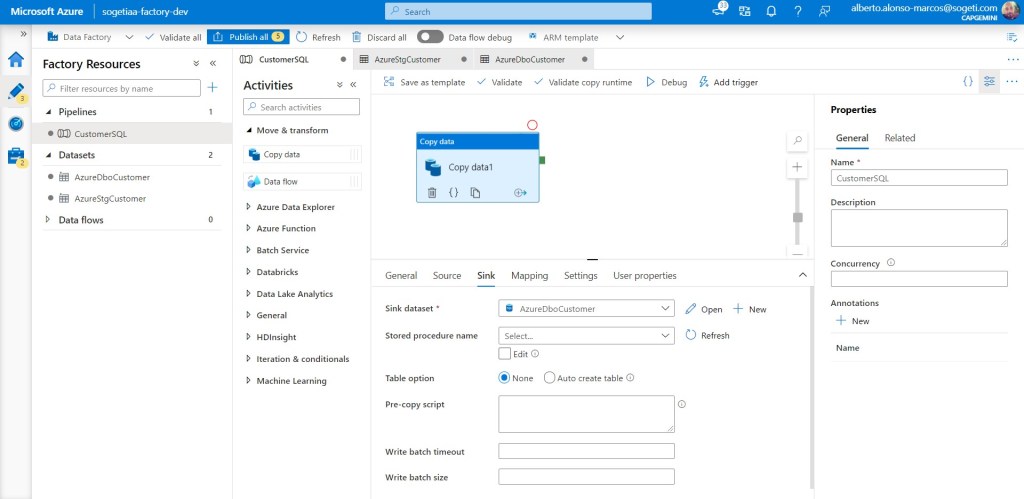
Publicamos los cambios y ejecutamos.

Comprobamos que todo ha funcionado correctamente al revisar el contenido de nuestras tablas en la base de datos.
Ahora nos queda la parte más interesante, combinar Azure Data Factory pipelines y Azure DevOps para la implementación del control de código. Para ello, lo primero es crearnos un nuevo repositorio en nuestra cuenta de Azure DevOps. El segundo paso es crear una nueva rama con el nombre de develop, que será la rama de colaboración. Comencemos.
Una vez creado, lo que debemos hacer es conectar Azure Data Factory con el repositorio de Azure DevOps. Para ello pulsamos sobre el icono de ADF de arriba a la izquierda.

Lo configuramos, y pulsamos sobre Apply
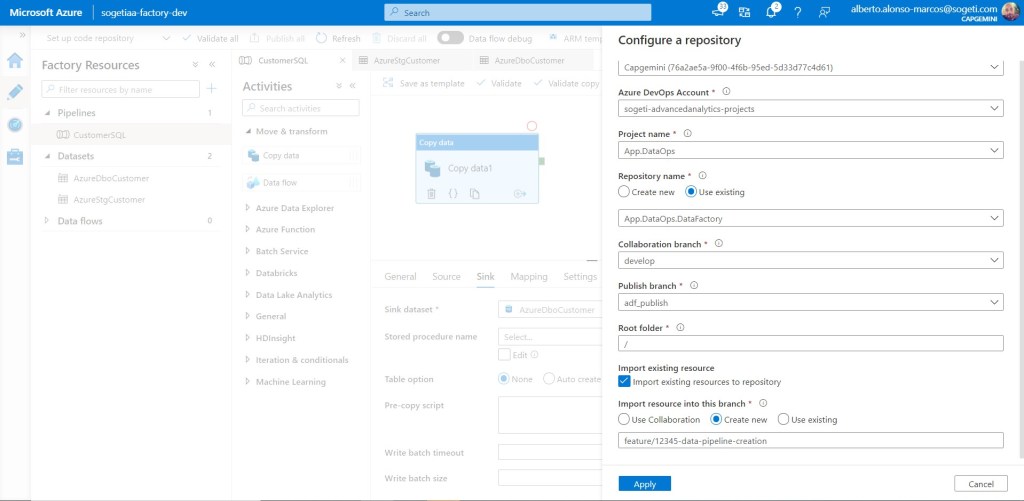
En el siguiente paso, indicamos sobre qué rama queremos trabajar. En nuestro caso será sobre la feature que tengamos vinculada desde nuestro Azure DevOps backlog. Por aquello de trazar el trabajo realizado y como parte de las buenas prácticas de desarrollo.

Si ahora me voy a mi repositorio de Azure DevOps y selecciono la rama feature/12345-data-pipeline-creation, veo que algo se ha incluido en ella.
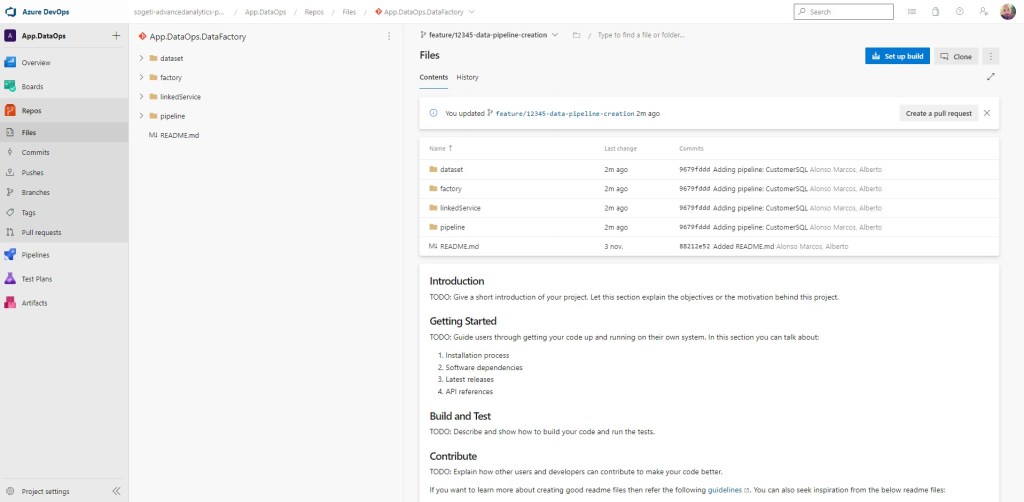
Sin embargo, de cara a trabajar con la automatización deberíamos recordar que esta parte sólo se puede comenzar a realizar cuando la rama de colaboración recibe la primera Pull Request aprobada y se realiza el publish desde ADF. Veamos.
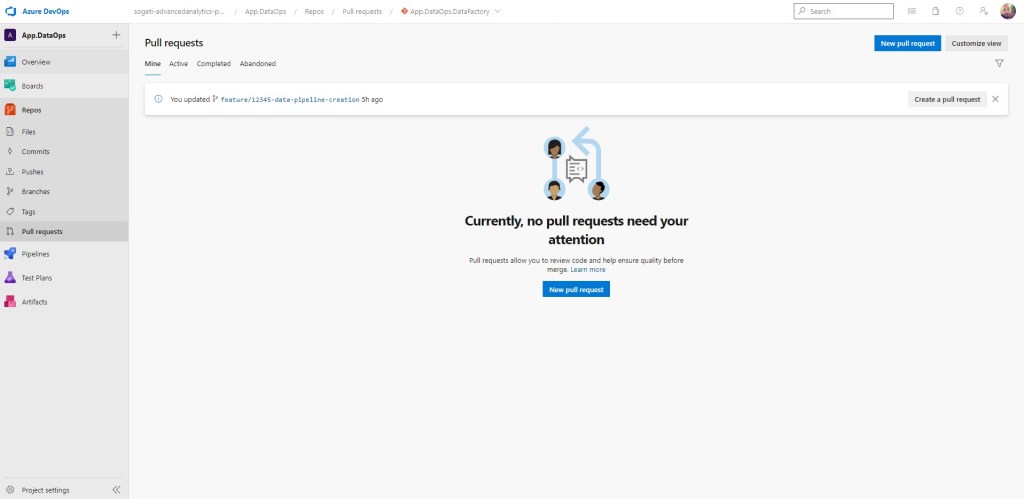
Como hemos definido que nuestra rama colaborativa es develop, solicitamos hacer la PR sobre dicha rama. Procedemos.

Me la auto apruebo, puesto que se trata de un ejemplo e indico que se elimine la rama de feature sobre la que estoy trabajando. También (no lo he seleccionado) puedo indicar que el work ítem del backlog se cierre.

Completado

Vamos a nuestra ADF y seleccionamos la rama develop. A continuación, publicamos.

En el momento de la publicación sobre la rama colaborativa, si desplegamos las ramas de nuestro repositorio, observamos una nueva con el nombre de adf_publish.

Ahí es justo donde se publican las ARM Templates de nuestro ADF. El primer fichero, representa a la ARM Template de Azure Data Factory, mientras que el segundo incluye los diferentes parámetros, que nos facilitarán la vida al desplegar en los distintos entornos.
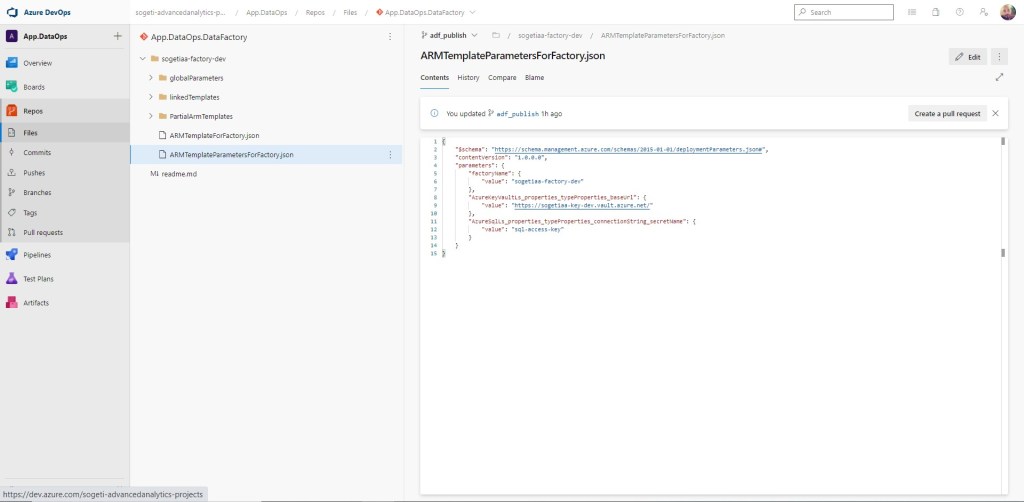
Ahora ya podemos avanzar hasta la automatización del despliegue en los distintos entornos.
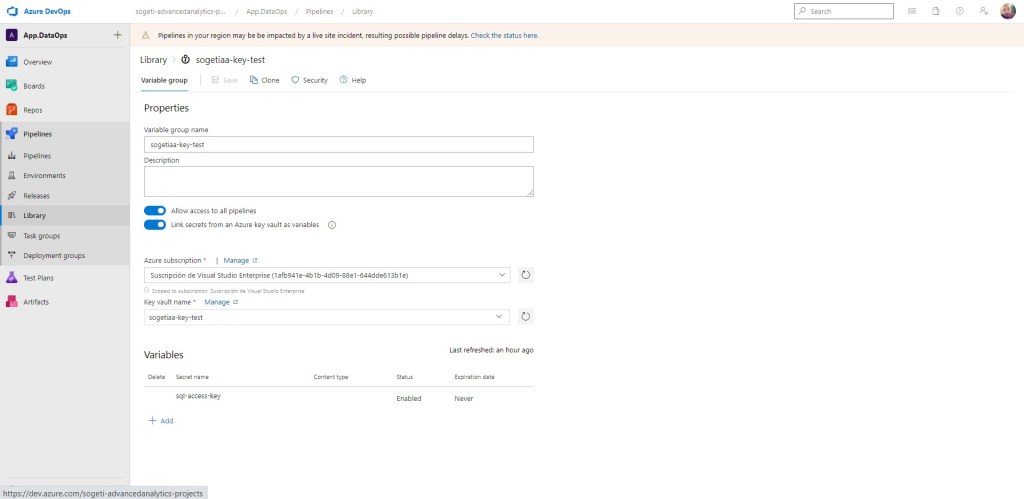
En esta segunda parte vamos a trabajar sobre la automatización para el despliegue de nuestro desarrollo en los distintos entornos de trabajo. Para ello, lo primero que vamos a hacer es crear un grupo de variables en nuestra librería. Así pues, creo el grupo de variables con el nombre de Testing y en variable, creo la variable entorno con el valor test
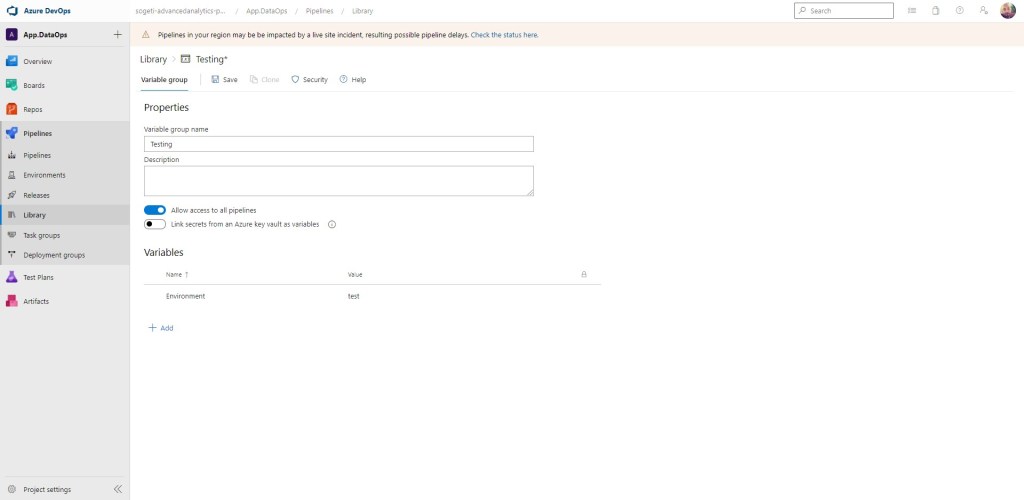
NOTA: Deberíamos repetir el proceso, en caso de trabajar con distintos entornos como stg, prd, etc.
Una vez completada esta parte, comenzamos con la creación de nuestro pipeline. Para ello creamos un nuevo pipeline y elegimos comenzar desde cero.

Renombro tanto la Release Pipeline como la etapa.

En este momento, creamos las variables del pipeline donde indicamos el tanto el nombre como el valor a incluir. Destacar que de cara a poder clonar la etapa, utilizamos una variable $(Environment) que recoge el valor que previamente hemos guardado en la variable de grupo. En el caso de Testing, será test.

Vamos a crear nuestro artifact. Para ello seleccionamos la fuente, el proyecto, repositorio y en la rama por defecto. Indicamos adf_publish. Comprobamos que elegimos la última publicada y grabamos.
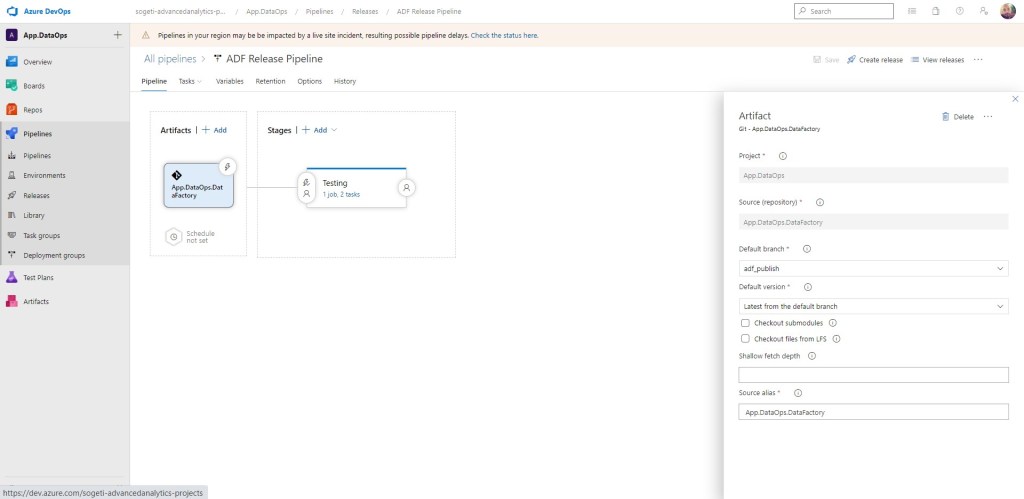
Al completar esta parte, añadiremos las distintas tareas de Development. La primera es habilitar la posibilidad de conectar con Azure Key Vault. Lo configuramos recordando sustituir dev por $(Environment)

Llegados a este punto, debemos construir el grupo de recursos y para ello utilizamos la tarea ARM template deployment. Configuramos

Es importante incluir la variable $(Environment) en el campo de Resource Group. Al igual que acordarnos de sobrescribir los parámetros de la template, incluyendo las variable $(factoryName) y $(AzureKeyVaultLs_properties_typeProperties_baseUrl) creadas anteriormente.
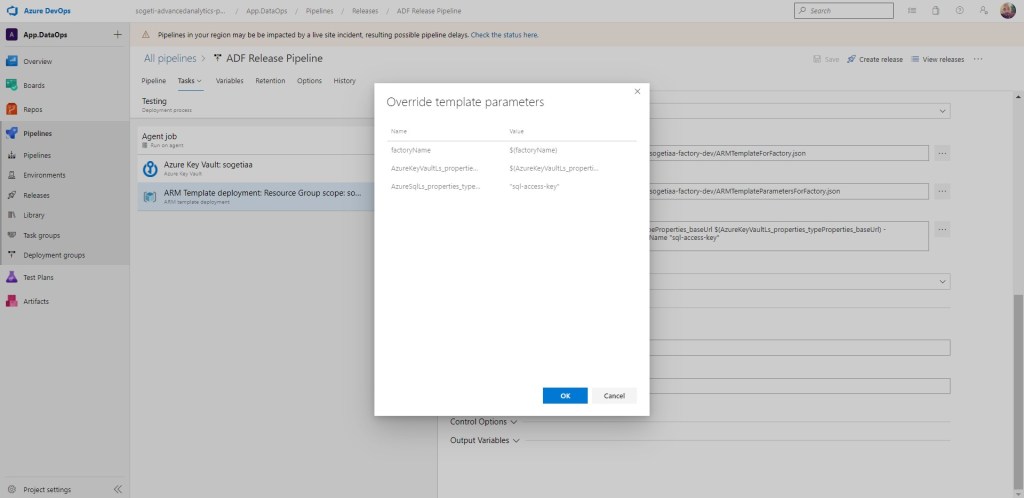
Una vez llegados hasta aquí, debemos usar un pre y post script de PowerShell que Microsoft ofrece para evitar fallos debido a aspectos como que existan triggers corriendo. Dejo el link para descargarlo.
Tenemos dos opciones para utilizarlo, la primera es incluirlo de forma manual en la tarea en DevOps o incluir el script dentro de adf_publish. Yo voy a optar por la segunda opción, ya que su tamaño excede lo máximo permitido en Inline script.

Subido

Una vez subido el fichero, lo que debemos incluir son dos tareas de Azure PowerShell. La primera será el predeployment script. Procedemos.
Es interesante destacar el uso del script path, para localizar el fichero subido anteriormente. Y copiar y adaptar el Script Arguments para vuestros propios ejemplos.

Script Arguments
-armTemplate $(System.DefaultWorkingDirectory)/App.DataOps.DataFactory/sogetiaa-factory-dev/ARMTemplateForFactory.json -ResourceGroupName sogetiaa-rg-$(Environment) -DataFactoryName sogetiaa-factory-$(Environment) -predeployement $true -deleteDeployment $false
Ahora sólo queda clonar la tarea de Azure PowerShell y cambiar el nombre y modificar los dos últimos argumentos a los valore contrarios a la tarea del predeployment.
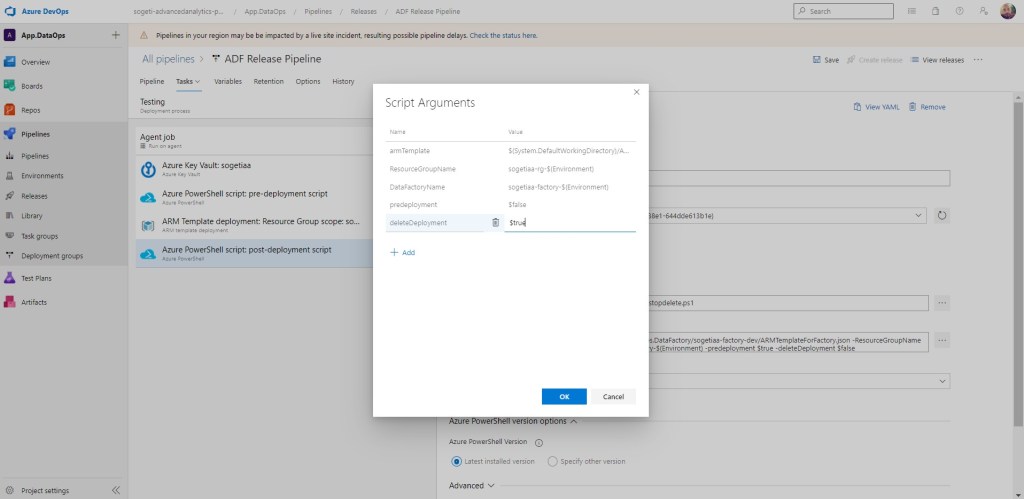
Ya tenemos nuestro pipeline terminado, con lo que construir un nuevo entorno, es algo que tenemos a mano de un click y pocos cambios adicionales. Veamos cómo.
Lo primero, como ya vimos, es tener creado el entorno en la librería como un grupo de variables. En este último caso, con el nombre de Production y la variable de entorno con el nombre de prd.

Una vez completado, vemos que podríamos construir la siguiente Stage replicando los pasos anteriores, o simplemente clonando la existente. Clonemos pues.

Una vez clonada, comenzamos a realizar las pertinentes modificaciones.
La primera, el nombre. Renombramos a Production. El segundo paso es algo más “complicado”. Debemos asignar las variables previamente creadas a la Stage correspondiente. Veamos.
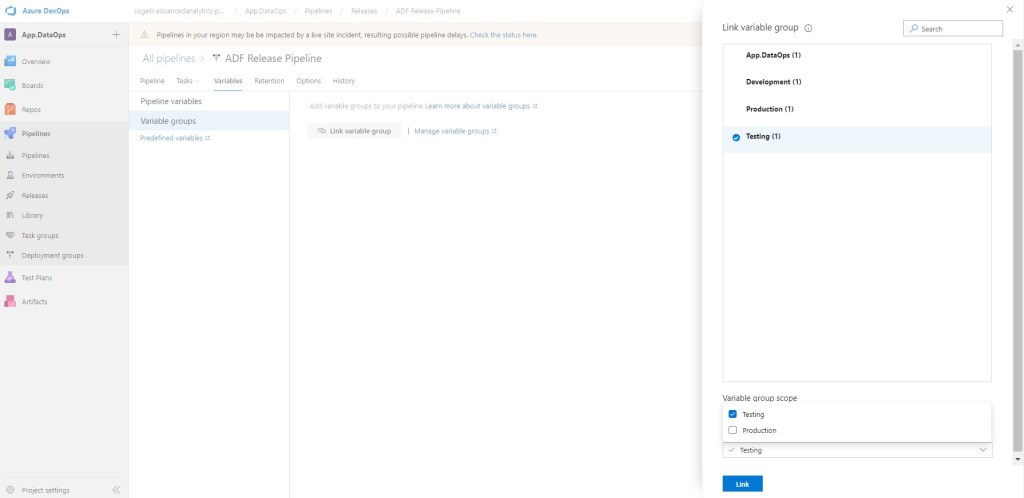
Lo tenemos

Llegados hasta aquí, nos queda acceder en una de nuestras cuentas de Azure data Factory, ir hasta la pestaña de asignaciones de roles y buscar nuestro principal y copiar el nombre.
Ahora vamos a automatizar la tarea de despliegue en caso de actualización de adf_publish. Para ello pulsamos sobre el rayo del Artifact y habilitamos Continuous deployment trigger. Seleccionamos la rama adf_publish.

A continuación, pulsamos sobre el rayo de la Stage de Production y en este caso seleccionamos ejecución manual. Así tendremos la potestad de ejecutarlo sólo cuando nosotros queramos, ya que precisa de aprobación.
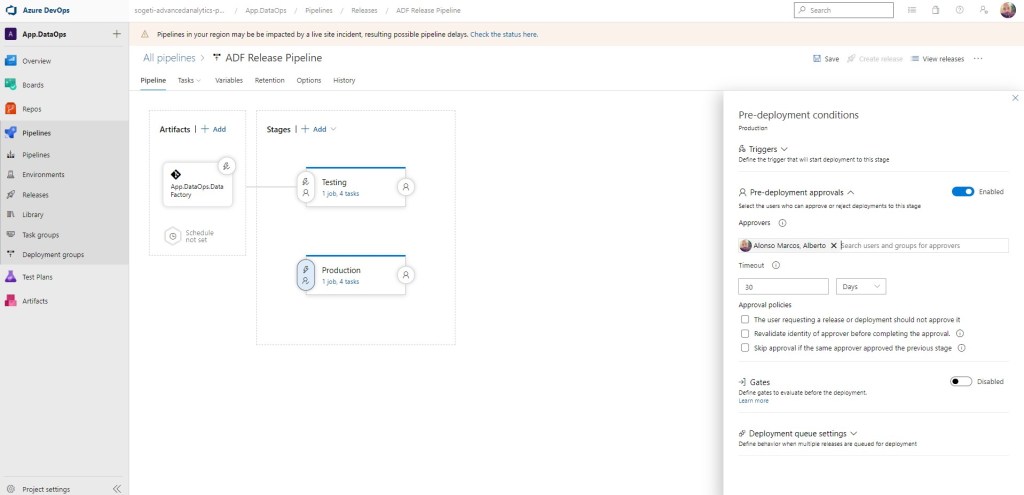
Realizamos la prueba, ejecutamos el trigger.
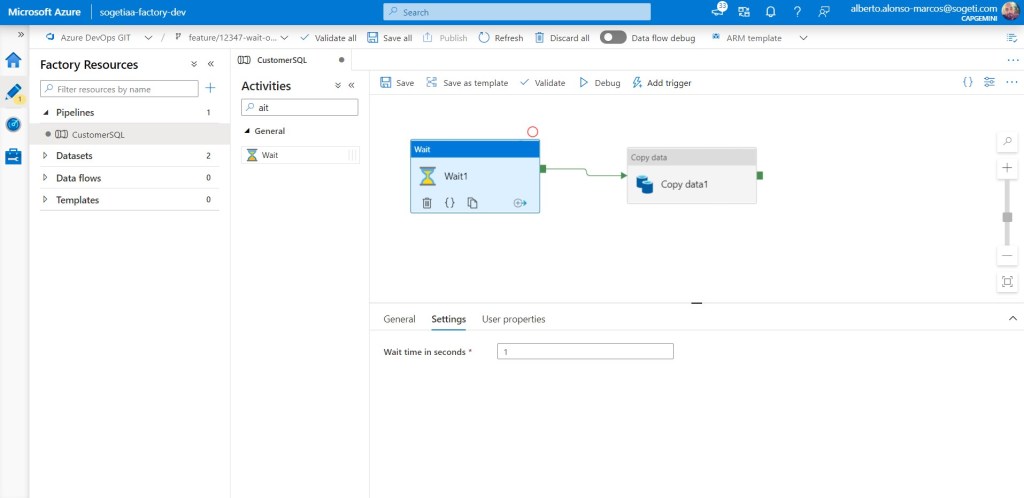
Como todo ha funcionado correctamente, solicitamos hacer la Pull Request desde la rama feature/12347-wait-one-second sobre la rama de develop.

Aprobamos la PR
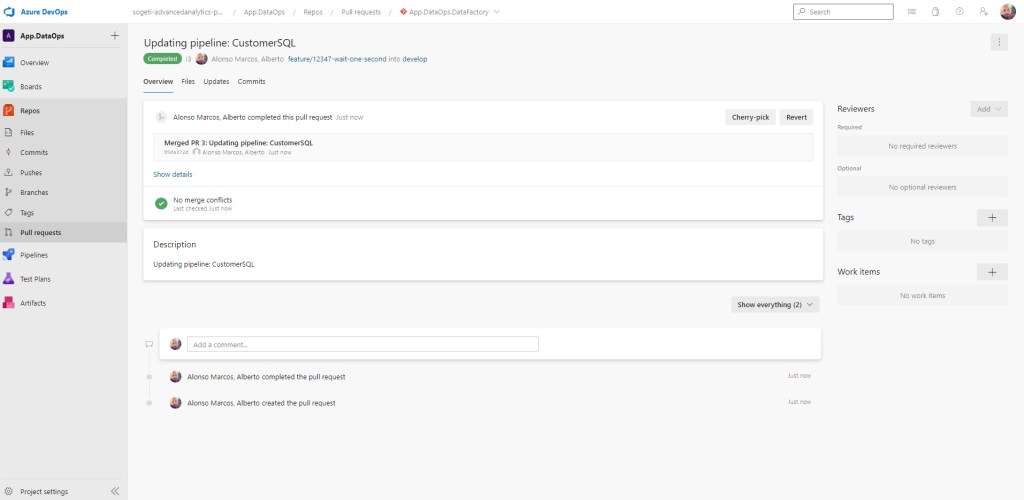
Cambiamos de la rama de feature a la de develop en ADF y publicamos.

Al terminar la publicación del adf_publish en nuestro repositorio, desencadenará la ejecución de la release en el entorno de Test.
Comprobamos que es así. Como vemos en la imagen de abajo, se está ejecutando el despliegue en el entorno de Test.

Una vez completado, verificamos que todo ha ido correctamente en Azure DevOps.
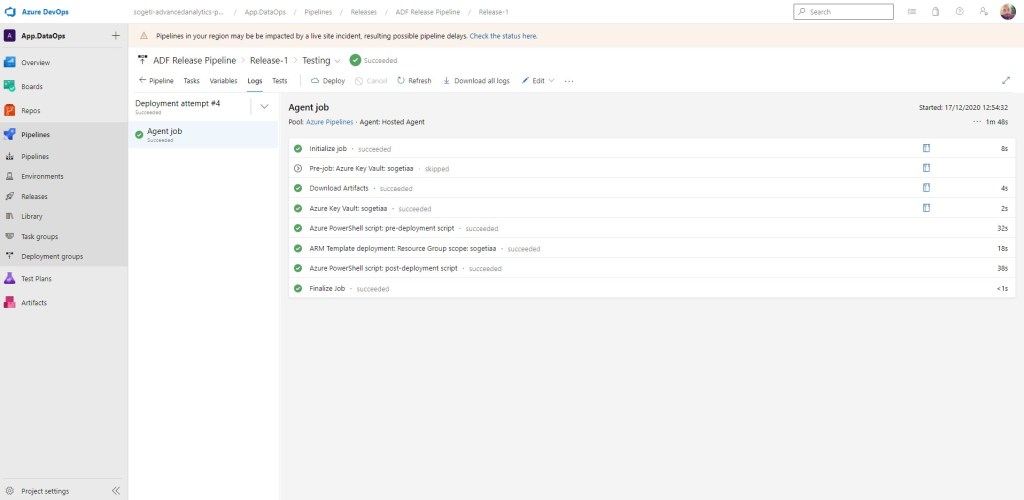
Ya sólo queda ir a nuestra Azure Data Factory en el entorno de Test y MAGIA. Vemos que el mismo conjunto de acciones que tenemos en dev, se han replicado en este segundo entorno.

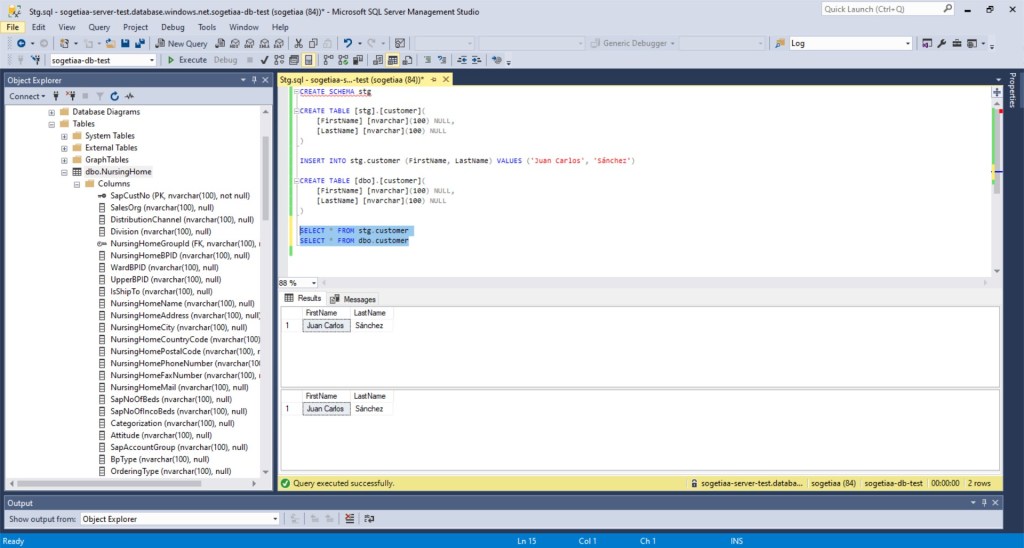
Vamos a chequear que en nuestra base de datos de test, sólo tenemos un registro en la tabla del schema stg.

Ejecutamos el trigger en el entorno de Test.
Esperamos a que se complete.
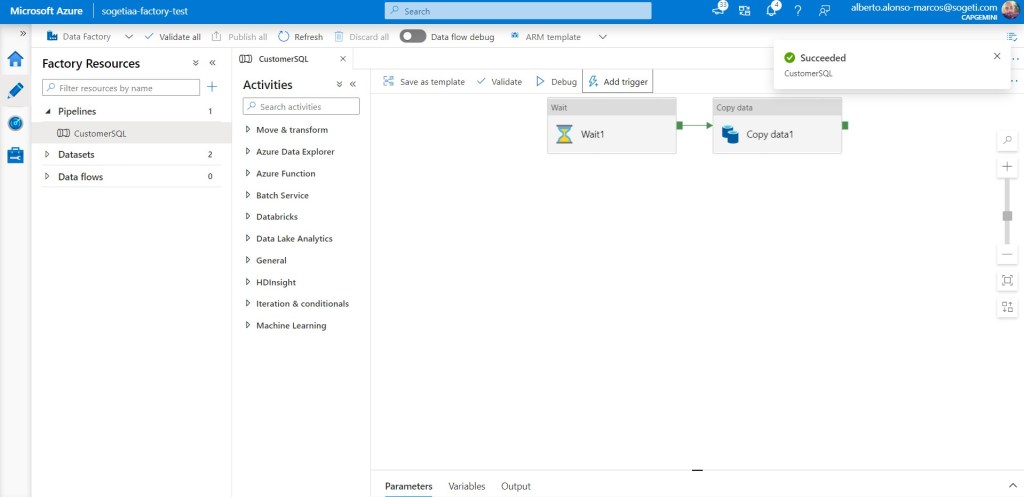
Comprobamos el contenido de ambas tablas y vemos que ahora también tenemos un registro en el schema dbo. Por lo que nuestro pipeline funciona correctamente.
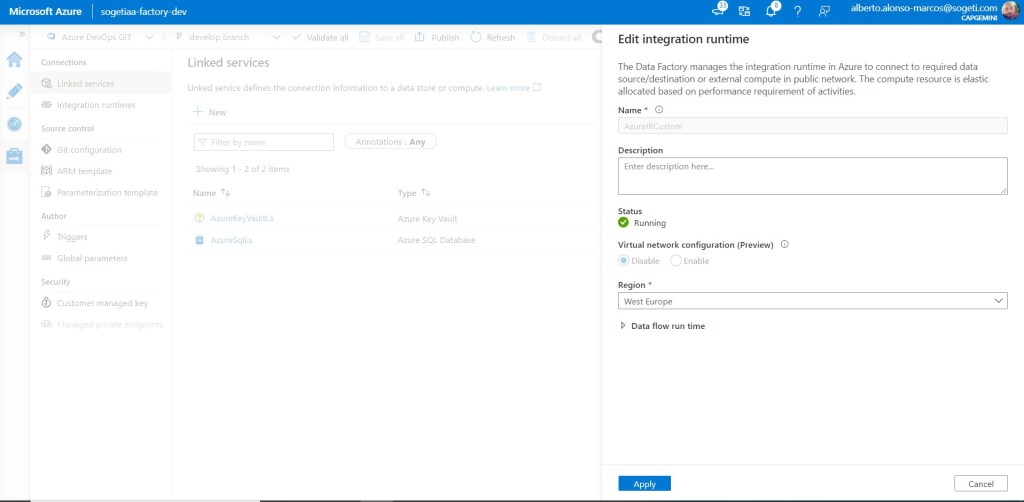
NOTA:
Con el fin de controlar el rango de IP que utilizará Azure Data Factory para conectar con los distintos recursos, conviene customizar el Integration RunTime. Así siempre controlaremos el rango de direcciones a habilitar.

Reblogueó esto en El Bruno.
Me gustaMe gusta