
La idea con esta entrada es profundizar en las capacidades Big Data que presenta Microsoft SQL Server 2019. Para ello, voy a realizar un tutorial paso a paso para que, de un modo sencillo, puedas realizar tú mismo la práctica y avanzar en tus conocimientos técnicos.
Esta fue una capacidad lanzada en la versión SQL Server 2019 (15.x) para ayudar a las organizaciones a manejar sus volúmenes de datos, incluso estando almacenados en fuentes de datos externas. La solución se orquesta mediante un clúster de Kubernetes gracias a contenedores Docker, lo que permite un fácil escalado.
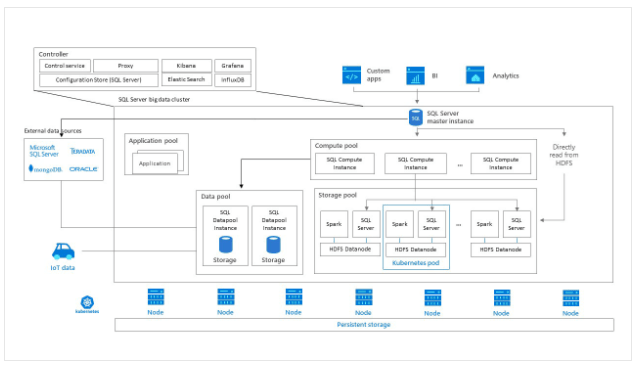
Los componentes principales de nuestro Clúster de Big Data son:
- Master Instance, que administra el grupo de datos (mediante DDL) manipula los datos de dicho grupo de datos (mediante DML) y direcciona la ejecución de consultas de análisis en el grupo de datos.
- Compute Pool, es el que provee de las instancias de SQL que soportan el cómputo
- Storage Pool, este componente permite combinar soluciones de ingesta de datos mediante Spark, también acceso y almacenamiento de tipo HDFS y finalmente puntos de conexión con SQL Server.
- Data Pool, provee de instancias SQL Server para el almacenamiento y proceso.
- Application Pool, nos permite proporcionar interfaces para la creación, administración y ejecución de aplicaciones. Un ventaja muy interesante presente en estas aplicaciones es la elevada capacidad de cálculo y el rápido acceso a datos. Por lo que es ideal para modelos de ML, por ejemplo.
Lo primero, para evitar sobrecargar mi ordenador, es configurar una Máquina Virtual en Azure, sobre la que configuraremos nuestro propio clúster de Kubernetes.
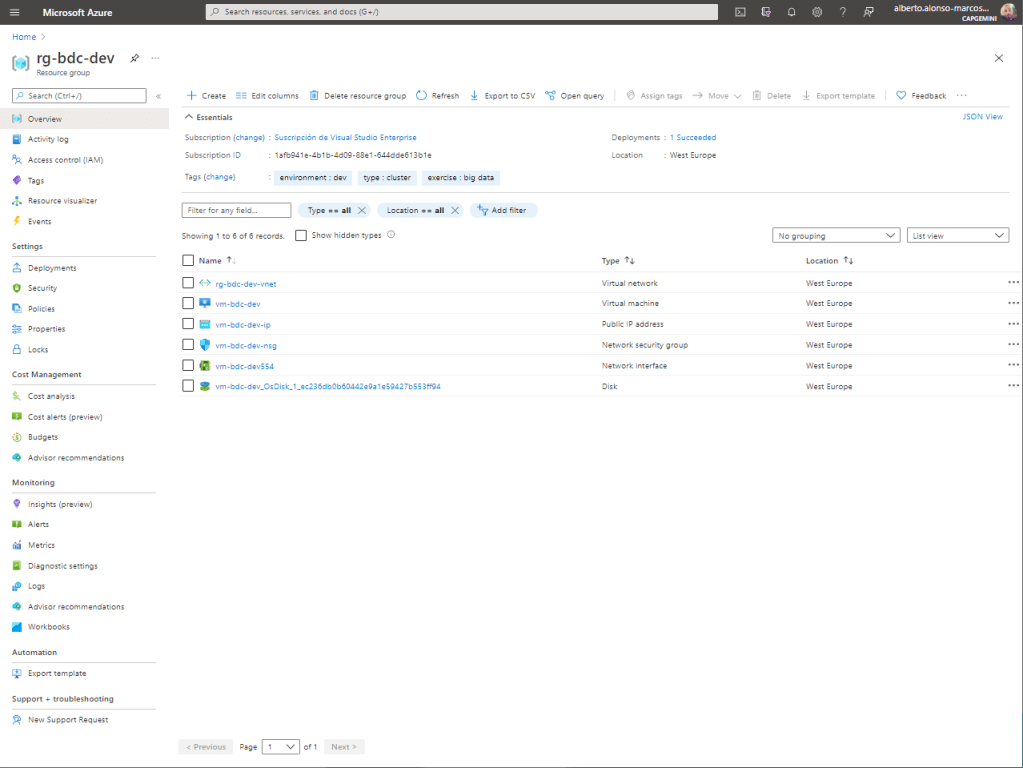
En este caso nuestra máquina dispondrá de sistema operativo Windows y en ella incluiré un conjunto de herramientas que necesitaré para completar el step by step.
- Python
- kubectl
- azdata
- Azure Data Studio
- Extensión para virtualización de Azure Data Studio
- Visual C++ Build Tools
- Azure CLI
- Notepad++
- cURL
- 7ZIP
- SQL Server command line utilities
- Putty
Una vez creada la MV, procedemos a conectarnos a ella y comenzar con la instalación y configuración.

Set-ExecutionPolicy Bypass -Scope Process -Force; iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))Ahora instalo python3 mediante el código
choco install python3 -yY realizo lo mismo con el resto de prerequisitos
choco install notepadplusplus -y
choco install 7zip -y
choco install putty -y
choco install azure-data-studio -y
choco install sqlserver-cmdlineutils -y
choco install azure-cli -y
choco install kubernetes-cli -y
choco install visualcpp-build-tools -yUna vez completada esta parte, debemos preparar el entorno de Python e instalar Azdata, veamos cómo:
$env:Path = [System.Environment]::GetEnvironmentVariable("Path","Machine") + ";" + [System.Environment]::GetEnvironmentVariable("Path","User")
python -m pip install --upgrade pip
python -m pip install requests
python -m pip install requests -upgrade
pip install prompt-toolkit==2.0.2
pip3 install -r https://aka.ms/azdataNOTA: es obligatorio ejecutar los comandos de Powershell como administrador, recuerda.
Lo siguiente es incluir la extensión de virtualización en Azure Data Studio. Para ello, lo abrimos en nuestra MV y seleccionamos dicha extensión. Instalamos.

Una vez instalada la extensión, nos movemos hasta la parte de los servidores y pinchamos sobre los tres puntos a la derecha de Connection y de nuevo sobre New Deployment. Seleccionamos la categoría de Cloud y elegimos SQL Server Big Data Cluster.

Ahora sólo queda ir completando los pasos que se irán presentando ante nosotros. vamos a por el primero.
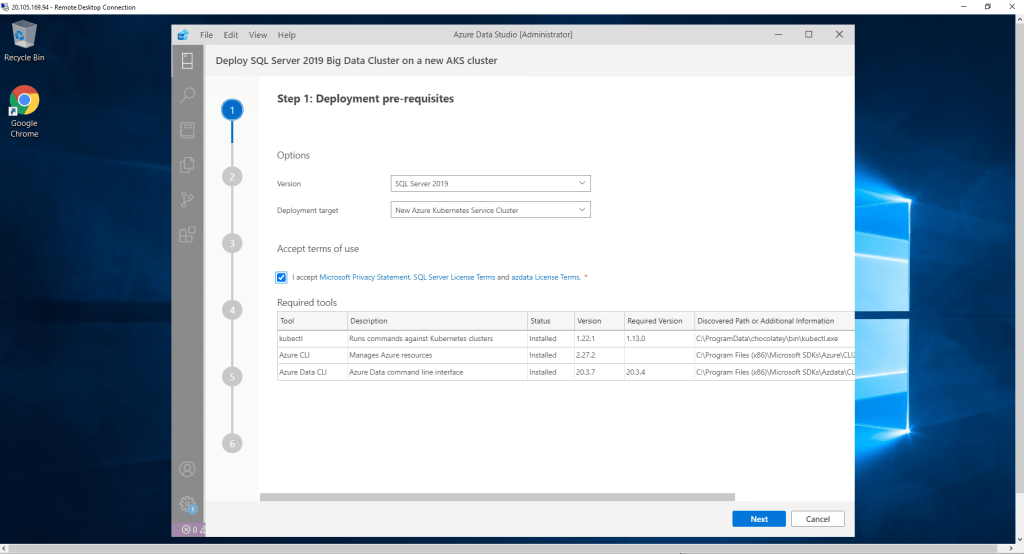
Al elegir la opción de crear un nuevo clúster de Kubernetes en Azure, en el siguiente paso tendremos la opción de decidir si se trata de un recurso para entornos de alta disponibilidad o no. En nuestro caso, decidimos que no disponga de alta disponibilidad.
Incluimos los datos de nuestra suscripción de Azure, así como la ubicación, nombre del grupo de recursos, el nombre del clúster AKS y el número y tipo de máquinas virtuales que lo soportan.

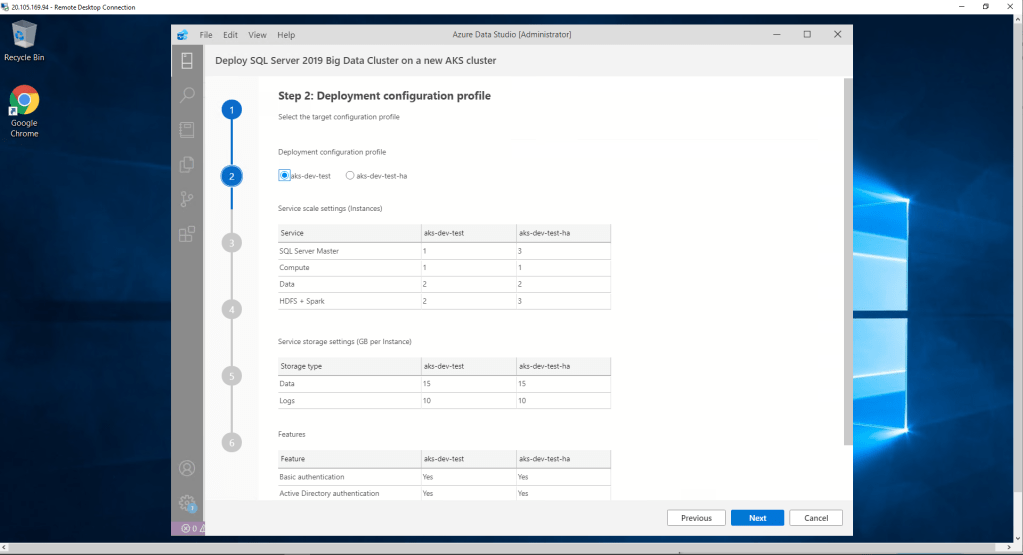
En el cuarto paso, configuramos todo lo relativo al clúster, como nombre, administrados, Password o modo de autenticación (Básico o mediante Active Directory). También podemos actuar sobre los contenedores.
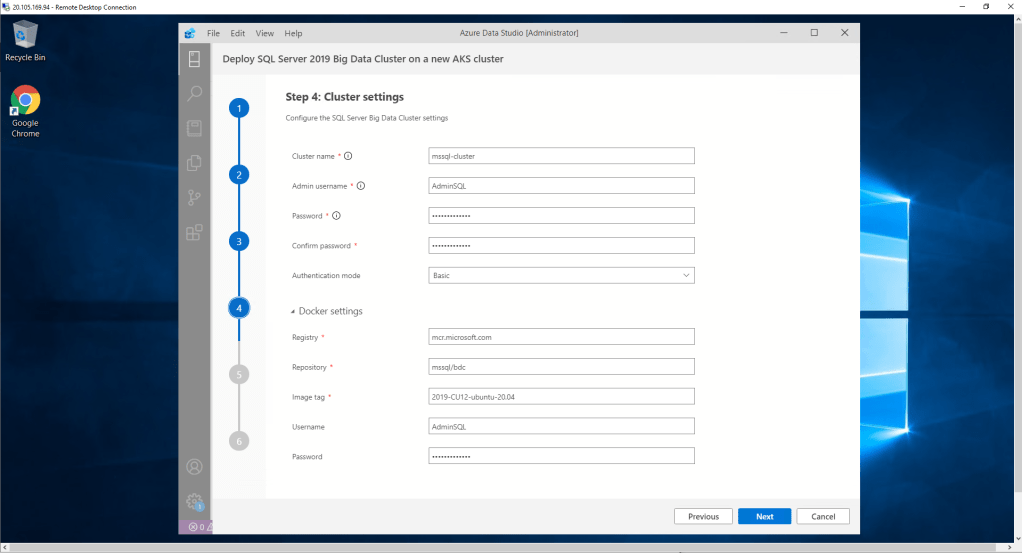
En el quinto paso configuramos el número de los principales componentes del Big data Clúster.

Finalmente, como casi en todos los procesos de creación de recursos en Azure, nos aparece la pantalla de resumen. Validamos la información y continuamos.
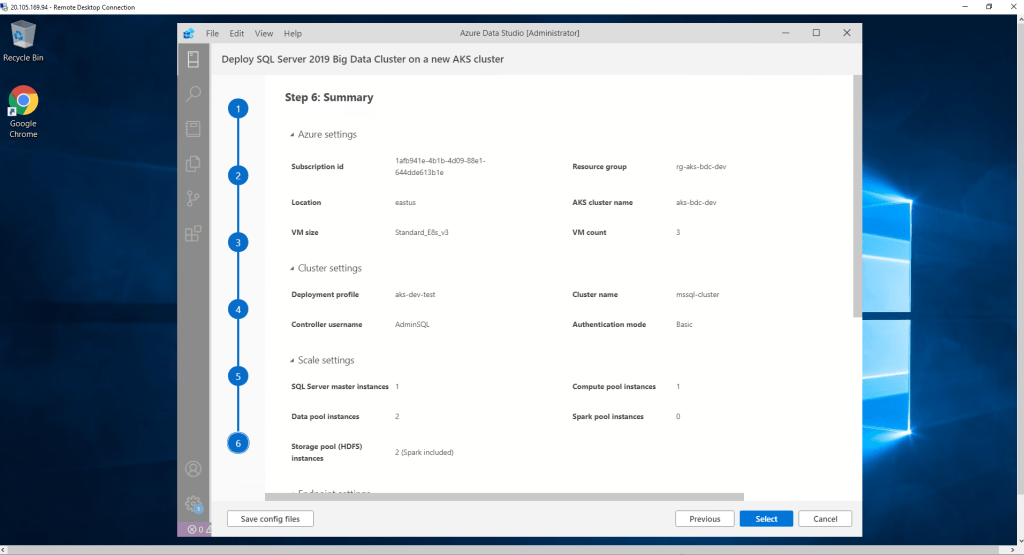
NOTA: Recuerda grabar la configuración del nuevo despliegue.
Una vez completado el despliegue el nuevo recurso, saltamos a la configuración del motor de nuestro Notebook. Como habíamos instalado previamente Python, no tenemos que repetir el proceso. Así que elegimos nuestra instalación.

El sistema directamente nos detecta posibles dependencias y continuamos con la configuración.
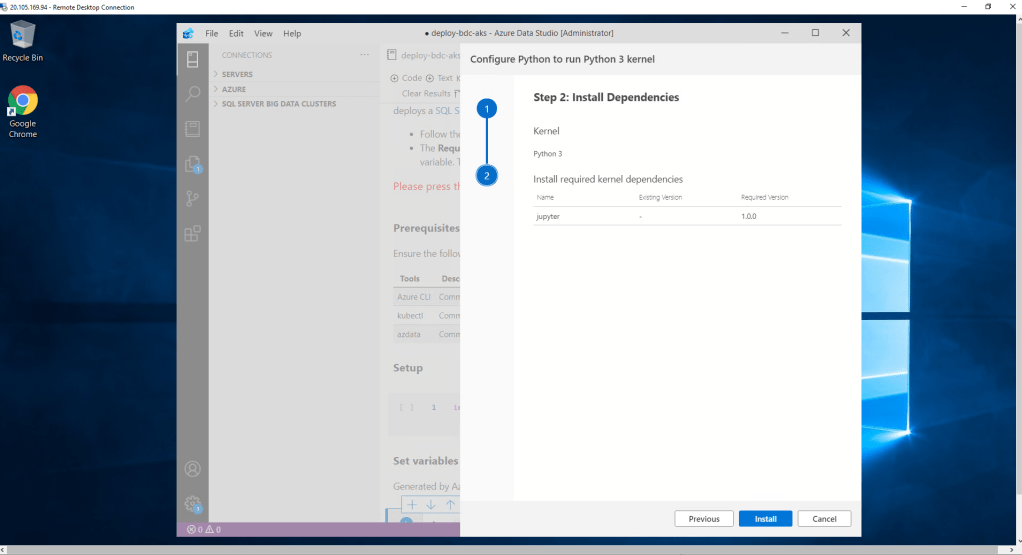
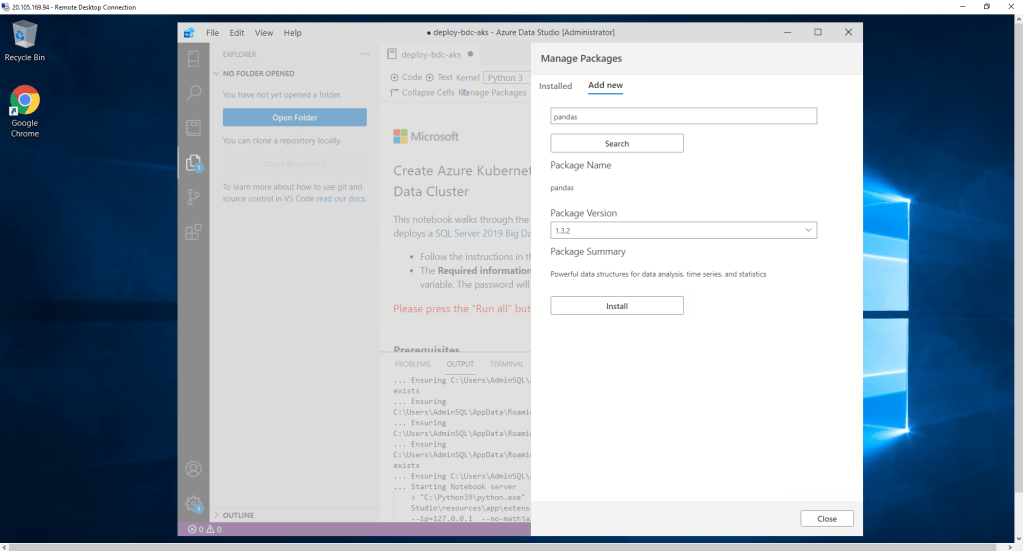
Parece que ya está todo completado pero no es así. Si comenzamos a ejecutar el Notebook que tenemos abierto por defecto, observamos que al ejecutar la primera celda, nos devuelve un error respecto del módulo pandas. hay que instalarlo. ¿Cómo?
Pulsando sobre el icono de manage Packages arriba a la derecha y seleccionando la pestaña de Add new. Incluimos pandas y pulsamos Install.
Lo mismo sucede con el AKS configurado anteriormente. Si vamos a nuestra suscripción, aún no está. Tenemos que ejecutar el Notebook para completar el despliegue. Los pasos anteriores únicamente era wizard para ayudarnos en el paso a paso y facilitarnos el despliegue del AKS y resto de recursos mediante código. Interesante, ¿verdad?
Ahora sí, una vez completados correctamente todas la celdas de nuestro primer Notebook, ya podremos ver el nuevo grupo de recursos con todos los servicios desplegados y a punto.
En la próxima entrega de veremos cómo trabajar con grandes volúmenes de datos aprovechando este Big Data Clúster en Azure Kubernetes Services con SQL Server 2019.
Foto de portada gracias a Markus Spiske en Pexels
