
Hoy día los equipo de #Data están continuamente moviendo datos y aunque existen opciones como la virtualización, en muchas ocasiones al menos uno o dos saltos son necesarios. Es por ello, que en la entrada de hoy he decidido hacer cuatro supuestos para que, de un modo sencillo, se pueda comprender las ventajas de una solución u otra.
Para poder comparar peras con peras y manzanas con manzanas, todos los procesos son pipelines de Azure Data Factory. En todos, la fuente de origen es un fichero .csv alojado en un Azure Blob Storage. Más concretamente es el fichero YellowTaxis.csv de 1,14 Gb y 9.999.995 filas con 19 columnas, quería que fuera un fichero de un tamaño «considerable» para comparar tiempos de carga.
Por otro lado, los cuatro supuestos son:
- Supuesto 1: paso 1, de .csv a Azure SQL Database y paso 2, entre tablas de Azure SQL Database
- Supuesto 2: paso 1, de .csv a Azure SQL Database y paso 2, entre tablas de Azure SQL Database, aplicando la opción de Bulk Insert en ADF.
- Supuesto 3: paso 1, de .csv a .parquet en Azure Data Lake Gen2 y paso 2, de .parquet a Delta Lake Table sobre ADLS
- Supuesto 4: paso único de .csv a Delta Lake Table sobre ADLS
Creo que es un buen conjunto de casos, el cubierto en esta breve entrada, con lo que espero que te ayude a comprender las posibilidades que te permite cada una de las combinaciones y tecnologías. Por supuesto, hay muchas otras opciones, sin ir más lejos, directamente ejecutando Notebooks de Azure Databricks, pero eso lo veremos en próximas entradas.
Supuesto 1 (No Bulk Insert)
Como he avanzado arriba, comencé con el supuesto 1. En el se configuró un pipeline de ADF con dos actividades «Copy», que lo único que hacía era, en un primer paso, mover los datos desde el origen, fichero en formato .csv y alojado en un Blob Storage, hasta el destino que en este caso era una tabla de Azure SQL Database. Para a continuación ejecutar un segundo movimiento de datos entre tablas de la misma Azure SQL Database. Veamos los tiempos de ejecución de ambos pasos:
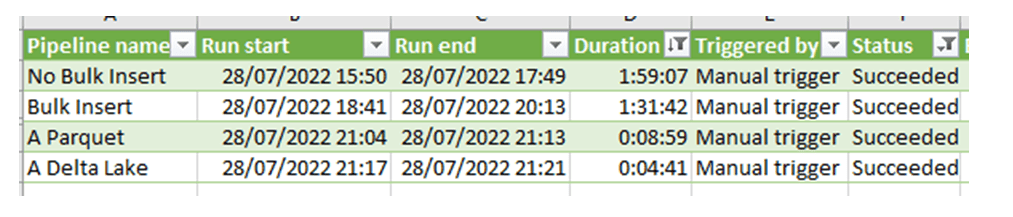
Paso 1 arroja un tiempo de procesado de 00:59:33
Paso 2 arroja un tiempo de procesado de 00:59:30
Uff!, el proceso toma para cada paso casi una hora ;(
Recordar que el tamaño del fichero .csv es de algo más de 1 Gb
Supuesto 2 (Bulk Insert)
En este caso, utilizamos una copia del primer pipeline únicamente habilitamos la opción de «Bulk insert» (nos permite bloquear la tabla para la inserción masiva) y ejecutaremos el proceso a ver qué ventajas nos ofrece. En caso de que ofrezca alguna 😉
Lo dicho, una vez cambiado el set en ambos pasos, procedemos a la ejecución manual del proceso y esperamos.
Paso 1 arroja un tiempo de procesado de 00:46:03
Paso 2 arroja un tiempo de procesado de 00:45:34
Vaya, en este caso se ha conseguido reducir el tiempo de ejecución en aproximadamente un 20%. Algo es algo, por tan sólo marcar una casilla 😉
Supuesto 3 (A parquet)
Saltemos ahora al tercer supuesto. Aquí hacemos un cambio de componentes, el primer paso lo que hacemos es persistir el fichero .csv en formato .parquet dentro de un Azure Data Lake Gen2, algo que vendría a ser como nuestro Raw Data, para acto seguido alimentar una tabla Delta Lake, que también está montada sobre un ADLS. ¡Veamos qué tiempos nos ofrece esta combinación!
Paso 1 arroja un tiempo de procesado de 00:02:59
Paso 2 arroja un tiempo de procesado de 00:05:55
¡Genial!, el tiempo empleado en total por el proceso ha sido de menos de 10 minutos. Un resultado increíble si lo comparamos con las casi dos horas del primer supuesto.
Supuesto 4 (A Delta Lake)
En este caso, el proceso se reduce a tan sólo un paso que carga el fichero .csv original directamente en la tabla Delta Lake del Azure Data Lake Gen2. Presumiblemente será más rápido en la ejecución, pero veamos.
Paso 1 (y único) arroja un tiempo de procesado de 00:04:38
Pues efectivamente, el tiempo de procesado se reduce a menos de la mitad del supuesto 3, si bien se pierde ese paso que en muchas ocasiones se marca como obligatorio de cara a cumplir frente a posibles auditorías como es disponer de una copia en crudo de los datos.
Tabla resumen de los tiempos empleados
CONCLUSIÓN
El Cloud nos ofrece una enorme cantidad de posibles configuraciones que den respuesta a nuestros casos de negocio. Es por ello, que conocer en detalle las ventajas e inconvenientes de cada uno de ellos es primordial de cara a poder ofrecer la solución que mejor cuadre en aspectos como la eficiencia, seguridad, escalabilidad y coste. Conviene emplear un tiempo en el análisis de las herramientas de cara a tomar una decisión informada, algo que evitará posteriores cambios de rumbo que impliquen sobrecostes y algún que otro quebradero de cabeza.
Foto de portada gracias a Ann H: https://www.pexels.com/es-es/foto/amarillo-fitnes-salud-investigacion-10895042/
