
En la primera entrada de DataOps con Visual Code y Azure Databricks realicé un step by step para conectar nuestro IDE con Azure Databricks y así poder ejecutar en local nuestros scripts de Spark (recordar que soporta varios lenguajes como pySpark, SparkQL, Scala, R). En la entrada de hoy, hablo acerca de cómo configurar los repositorios de código conectando con Azure DevOps y ejecutar un pipeline de Azure Data Factory.
Como se puede observar, seguimos sumando elementos e incrementando el control sobre cada uno de ellos gracias a la adopción de buenas prácticas DataOps. ¡Empecemos!
Lo primero es crear el proyecto en Azure DevOps y ambos repositorios, el primero para el código de Spark conectado a Azure Databricks y el segundo para Azure Data Factory.

NOTA:
Aprovechando que empezamos a sumar piezas y que en entradas anteriores he profundizado en algunas de ellas, os dejo al final del artículo un conjunto de links a revisar, por si quieres ampliar información.
Una vez creados los dos repositorios, App.DataOps.Databricks.ADF y App.DataOps.Databricks.PySpark pasamos a vincularlos con los diferentes recursos, por un lado con Data Factory, y el segundo repositorio tanto con Visual Code como con Databricks.
Comenzamos con incorporando el repositorio en nuestro Azure Databricks Workspace.

El siguiente es clonarlo en Visual Code, sencillo, mediante la URL del repositorio 😉
Una vez completado el proceso, creamos la primera rama feature/12345-step-1 y completamos nuestro primer script de Spark que será ejecutado en nuestro Azure Data Factory
Ese código sólo extrae información, la transforma (mediante un simple filtro) y la carga
from pyspark.sql import SparkSession
from pyspark.sql.functions import lit, col
spark = SparkSession.builder.getOrCreate()
df = spark.read.format("csv").option("header", "true").load("/databricks-datasets/asa/planes")
df = df.withColumn("NewCol", lit(0)).filter(col("model").isNotNull())
df.write.format("delta").mode("overwrite").saveAsTable("exDatabricks")Saltamos un momento a nuestra Azure Data Factory para por un lado, vincularla al repositorio, como ya visto en uno de los artículos publicados el año pasado, y por otro lado, incluir una acción de Databricks que ejecute el código de arriba.
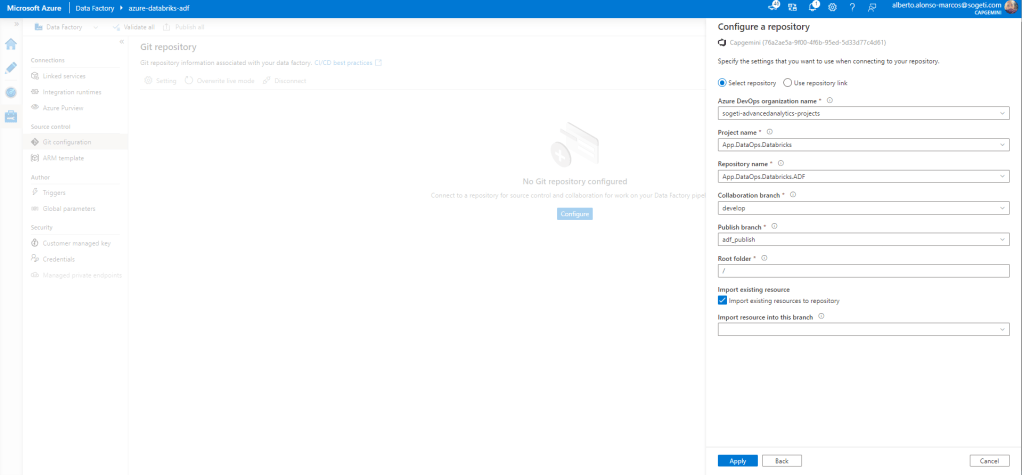
Ya hemos completado la creación del recurso en Azure, con lo que pasamos a completar la configuración del Linked Service de Azure Databricks.
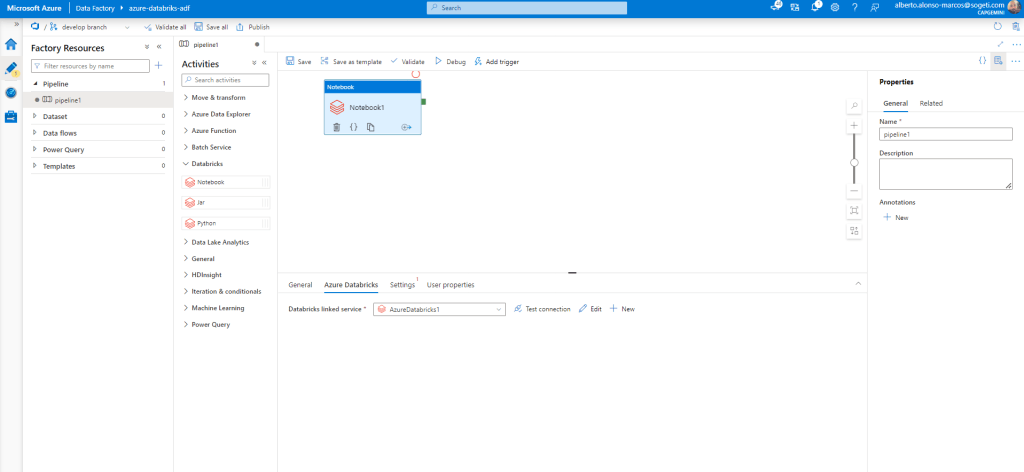
Aquí hay un punto importante y es que las acciones de Data Factory para Databricks no ejecutan directamente el código pySpark subido al repositorio. Para ello, hay que completar un Notebook desde el que crear una casilla que ejecute dicho código. Sería algo así:

Para acto seguido, subir nuestros cambios desde Visual Code desde la rama feature y hacer una Pull Request sobre develop y desde ahí a main
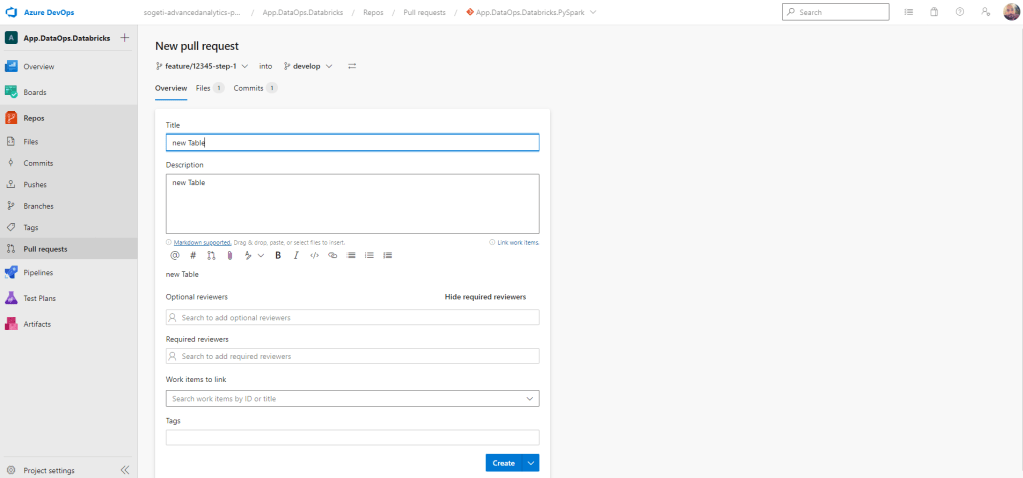
Una vez completada la PR, ya podemos hacer uso de ese script desde la tarea de Data Factory
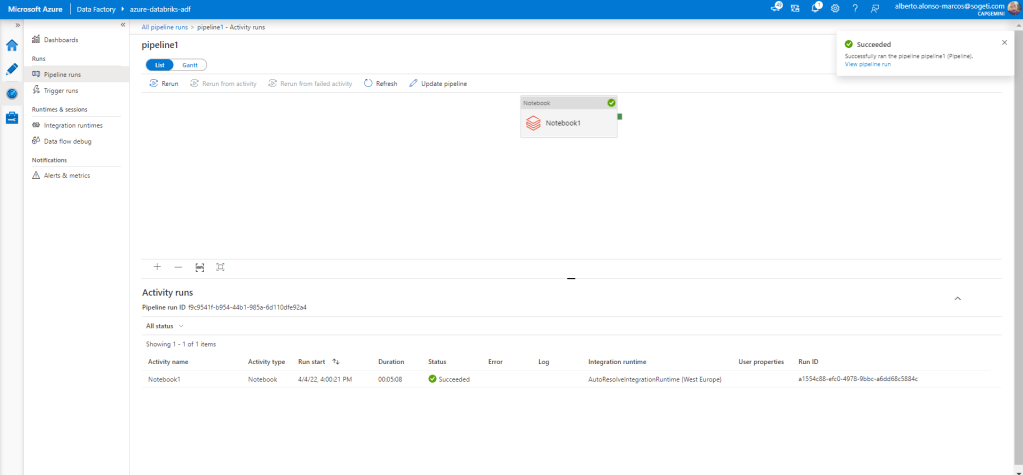
IMPORTANTE:
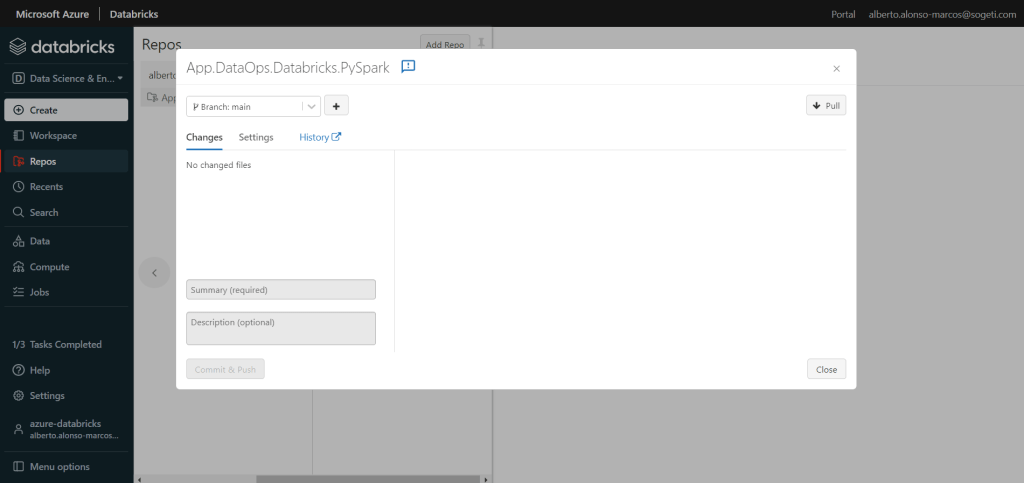
La actualización automática de la rama en Databricks no se ejecuta, por lo que siempre hay que recordar hacer Pull, os pongo el ejemplo. En la primera subida de código pySpark, el nombre de la Tabla a crear fue «example2», mientras que en la última subida, la cambié a «exDatabricks». Como se aprecia en el repositorio al acceder desde Databricks, el código no está actualizado.

Para ello hay que ir a la rama y pulsar, como ya había apuntado, el botón de Pull
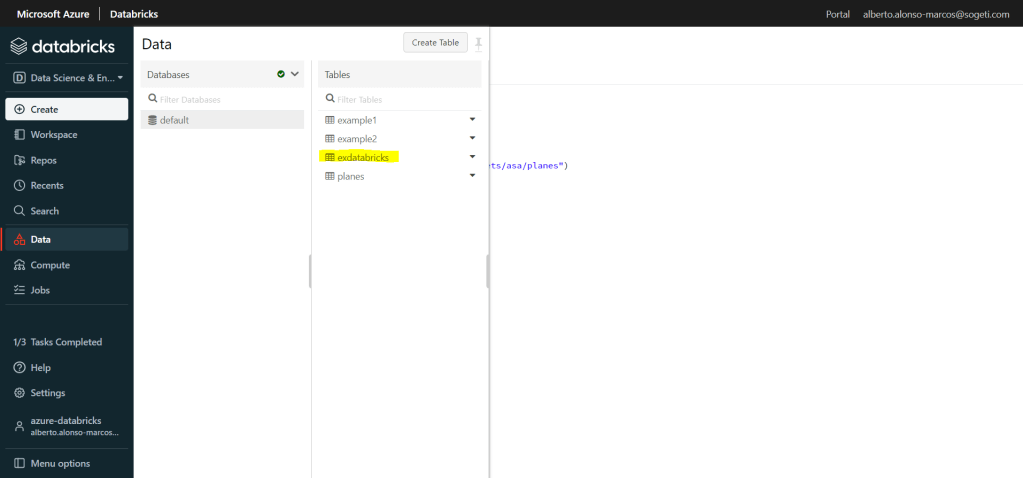
Ahora sí que veremos nuestro código pySpark actualizado y listo para ejecutarse mediante Data Factory.

Tras lo cual podremos observar una nueva tabla con el nombre de «exDatabricks» en la sección Data de Azure Databricks
CONCLUSIÓN
Como sabéis, los que seguís habitualmente mis publicaciones, el control de versiones y el trabajo colaborativo son piezas clave junto con herramientas de control de código, análisis de vulnerabilidades, test unitarios, etc. Es decir, trata siempre de construir con las mayores garantías de éxito, para ello, implementar unas Buenas Prácticas de DataOps es básico y te lo tienes que grabar «a fuego».
Como hemos podido apreciar, databricks presenta un inconveniente con respecto a la necesidad de hacer Pull desde la rama del repositorio, por carecer de sincronización automática. Esto sin duda debe estar documentado y el responsable de la aprobación de PR deberá hacer seguimiento a dicha manualidad.
En la próxima entrada, trataré de hacer un step-by-step de cómo presentar una estructura de proyecto básica, incluyendo test unitarios.
Links de interés
https://alb3rtoalonso.com/2022/03/31/dataops-con-vs-code-y-azure-databricks/
Foto de portada gracias a RUN 4 FFWPU en Pexels
