
En más de una ocasión he hablado acerca de la importancia de desarrollar con calidad nuestros proyectos, algo que resulta especialmente delicado cuando de datos se trata y es ahí, por tanto, donde cobra especial relevancia la adopción de buenas prácticas y cómo éstas se ponen en valor. En mi caso, abogo por utilizar un framework robusto de DataOps que permita la integración con repositorios, trabajo colaborativo, versionado de código, incorporación de test unitarios y herramientas de análisis de código, vulnerabilidades,…
Hoy voy a configurar Visual Code como IDE para trabajar con Azure Databricks. Existen otras muchas opciones, como por ejemplo, Intellij que será tratado en otra entrada.
Saltemos a realizar la configuración de Visual Code. En esta primera parte lo que voy a incorporar es un complemento desde el Marketplace que nos permitirá tener visibilidad de todos los elementos que disponemos en nuestro Azure Databricks Workspace. Incluso permitiéndonos, por ejemplo, encender o apagar nuestros clústeres. Para ello, lo primero es descargar la extensión Databricks VSCode desde el Marketplace.

Una vez instalado, debemos configurar la conexión desde los Settings de Visual Code
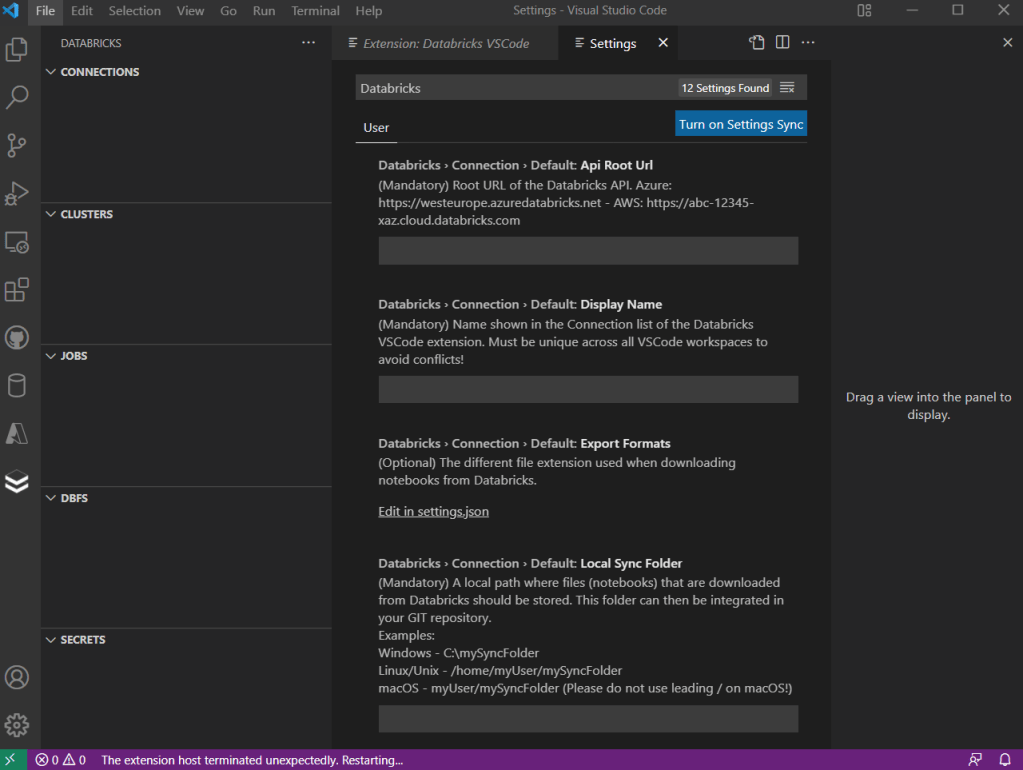
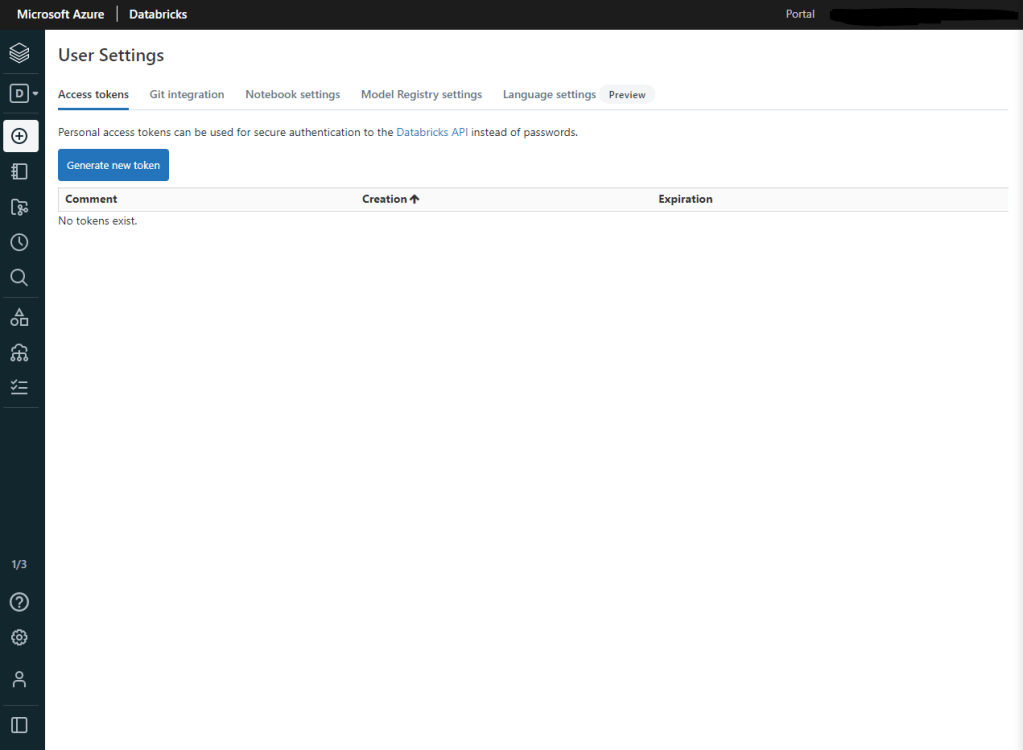
Mientras que incluimos la URL de nuestro Databricks y el nombre, debemos obtener un Token. Para ello lanzamos nuestro entorno de Databricks y en el área de User Settings, vemos que existe una pestaña con el nombre Access tokens. Pulsamos sobre generar un nuevo token y lo pegamos en nuestro Visual Code
Una vez completados todos los campos obligatorios, deberías ver todo el detalle de tu entorno de Azure Databricks en Visual Code en la zona izquierda de tu IDE.

Una vez configurado el componente del Marketplace, pasamos a la segunda parte donde incorporaremos Databricks Connector, lo que nos permitirá ejecutar nuestro código local desde Visual Code, en el clúster de Azure Databricks. Para ello, vamos a crear otro cluster e incluimos estas dos líneas en el apartado de Advanced Options
spark.databricks.service.server.enabled true
spark.databricks.service.port 8787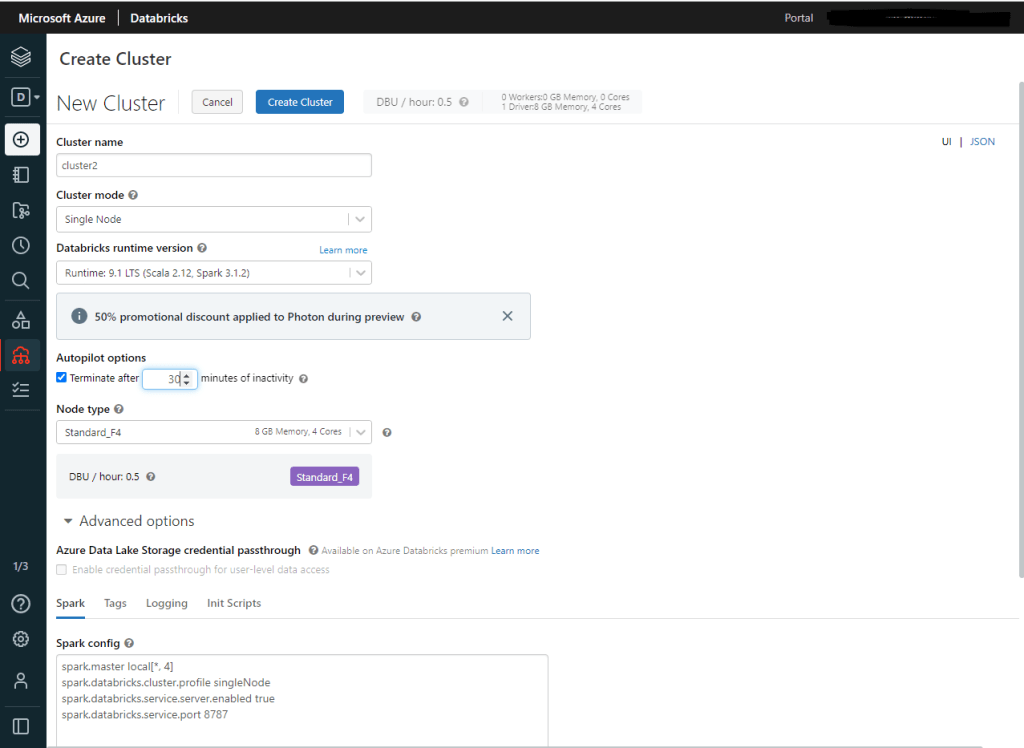
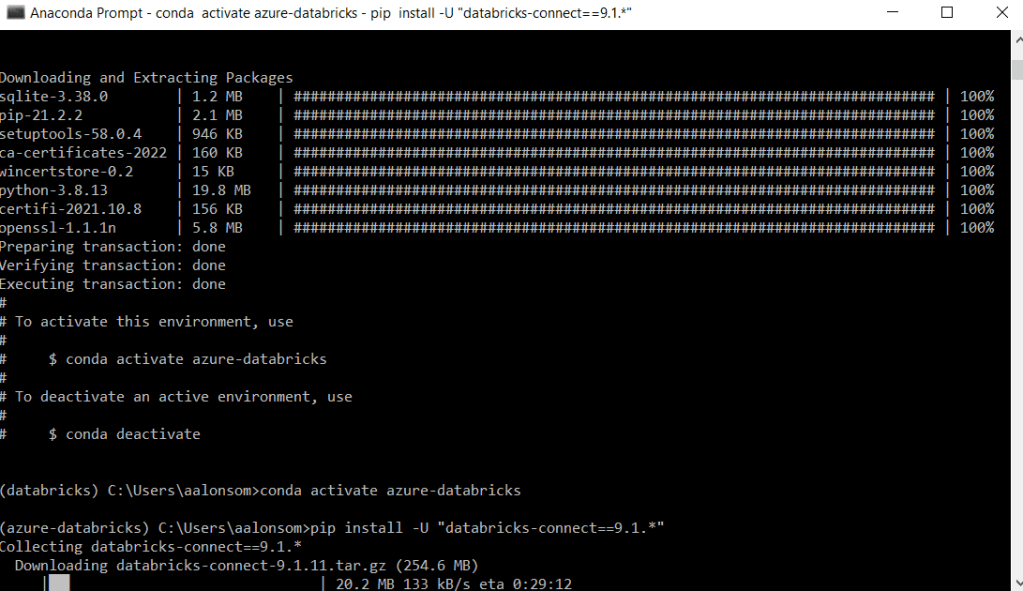
El siguiente paso es configurar un entorno virtual, que en mi caso al disponer de Anaconda, sólo requiere abrir la consola y ejecutar el siguiente grupo de instrucciones
Como el Runtime de nuestro clúster es la versión 9.1 LTS debo realizar los siguientes pasos
conda create --name azure-databricks python=3.8
Ahora cambio a este nuevo entorno
conda activate azure-databricks
Una vez allí, instalo la librería de Databricks-Connect mediante
pip install -U "databricks-connect==9.1.*"Veremos algo como esto
El siguiente paso es configurar la librería para poder así conectarnos. Deberemos completar todos los pasos
databricks-connect configureAceptamos e incluimos la URL del Databricks Host
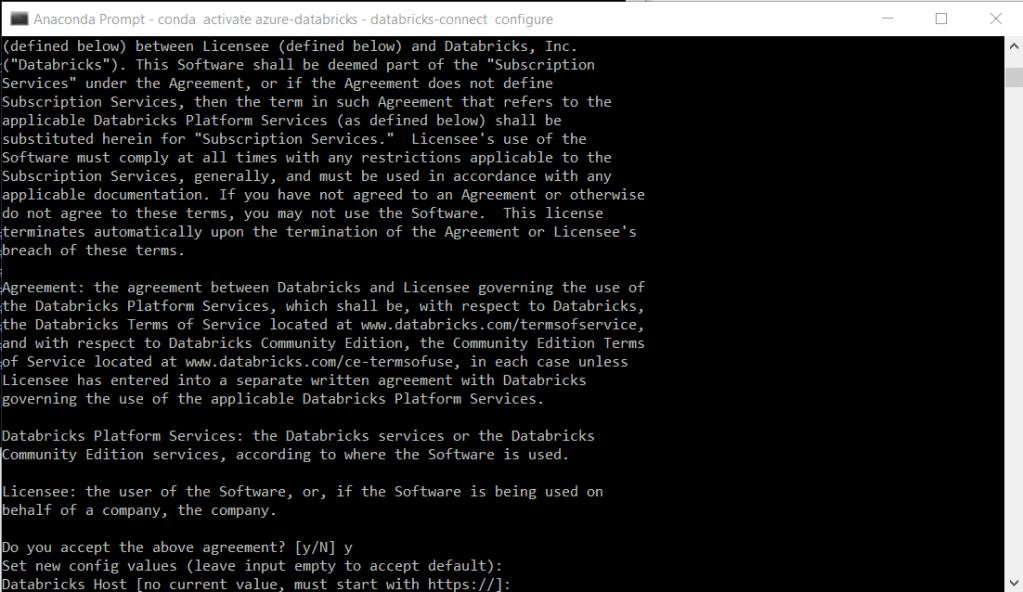
El siguiente paso es incluir un Token, para ello volvemos a a User Settings de nuestro Azure Databricks Workspace y pulsamos sobre «Generate new token»
El siguiente es el ClusterID que, también se encuentra en el apartado de Advanced options
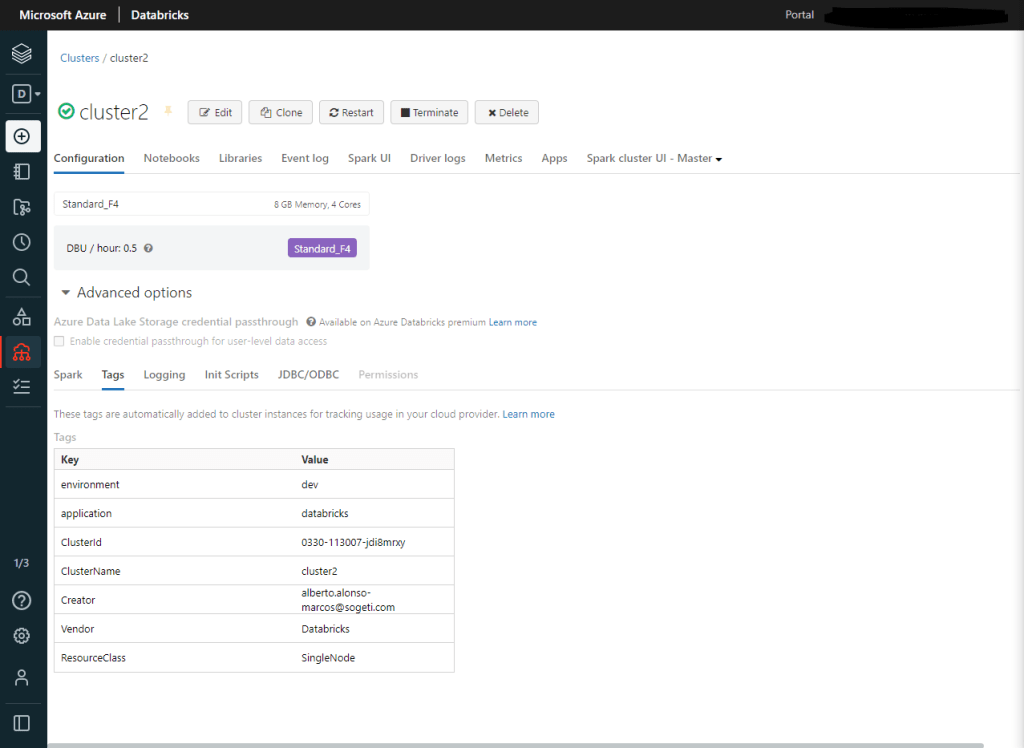
El siguiente es el OrgId (exclusivo de Azure) que se encuentra en la URL del cluster. Es justo el número que aparece sin ocultar en el navegador 😉
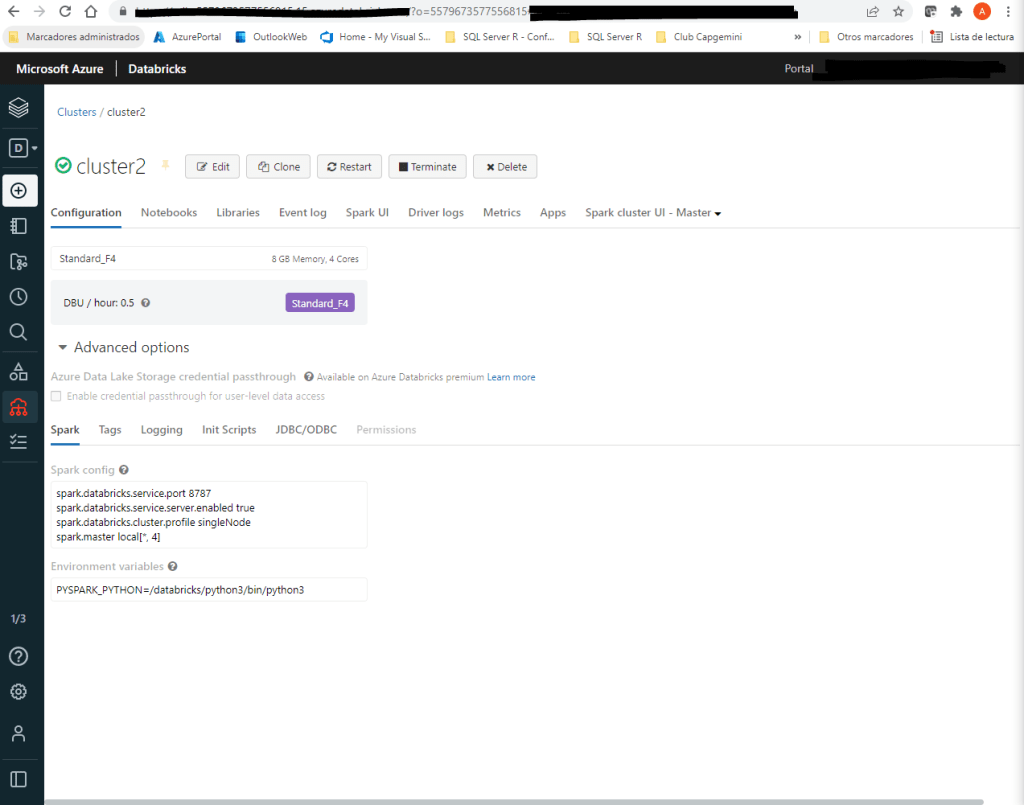
Lo siguiente es el puerto, que en nuestro caso será el 8787, como ya habíamos indicado en el momento de crear nuestro nuevo clúster.
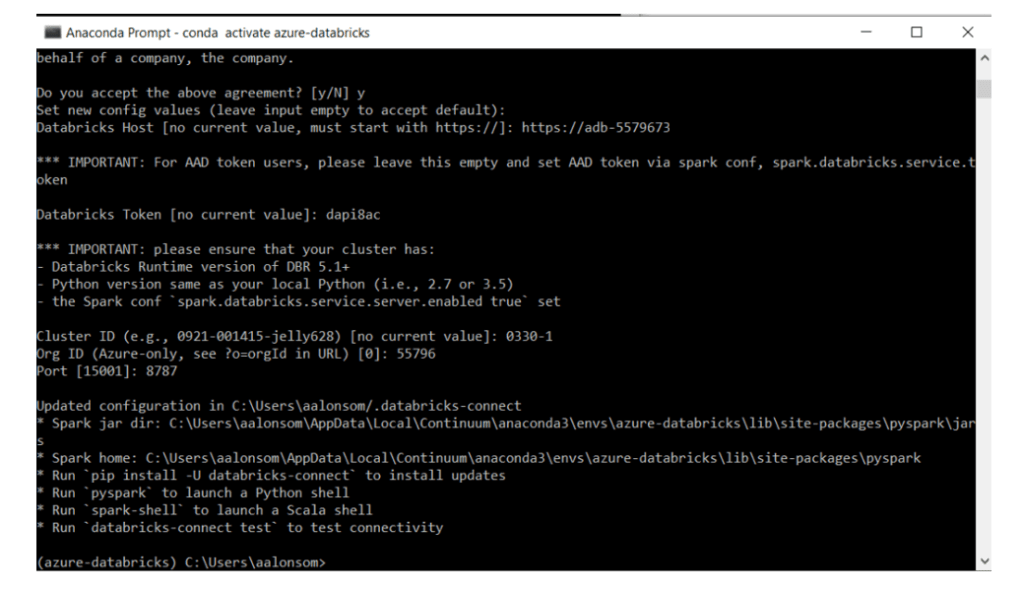
IMPORTANTE
Antes de validar la conexión, para equipos Windows, debemos incluir el fichero winutils.exe que se puede descargar desde aquí en una ruta algo como «C:\hadoop\bin»

Una vez completado, deberemos incluir HADOOP_HOME en nuestras variables de entorno (también en el PATH) y reiniciar el ordenador.
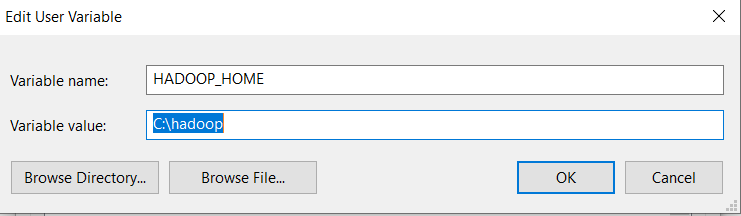
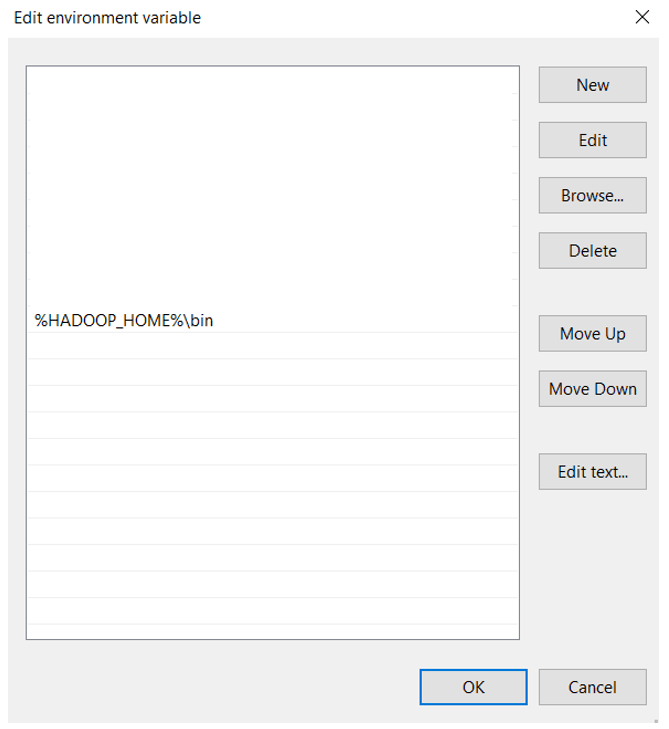
Ya sólo queda validar la conexión mediante la ejecución del siguiente código
databricks-connect testUna vez aquí, saltamos a nuestro Visual Studio Code y lo primero que debemos hacer es verificar que disponemos de una versión de Python instalada. El siguiente paso es lanzar la Command Palette mediante Ctrl+Shift+P y seleccionar el Python interpreter, que será justo el del entorno que hemos configurado.
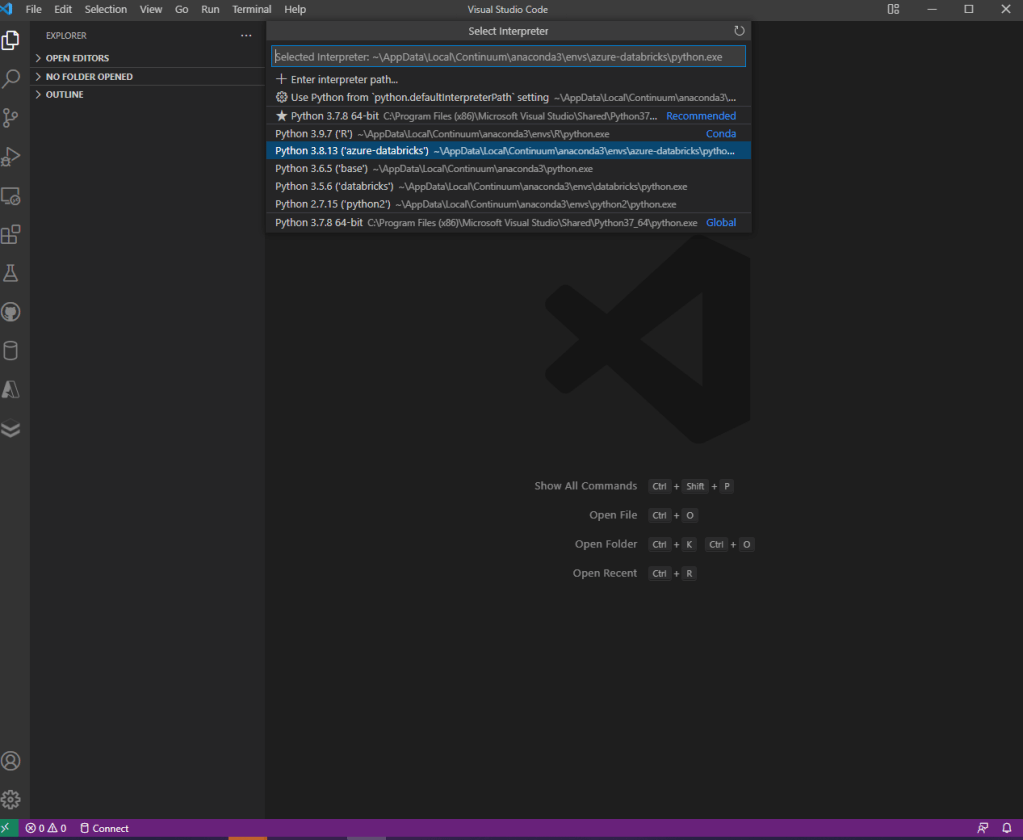
El siguiente paso es ir a nuestro código y ejecutar, con esto verificamos que todo es correcto y que por lo tanto, tenemos nuestro IDE local conectado con el clúster de Azure Databricks desplegado en el Cloud. Ya podemos comenzar a usar la plantilla de nuestro proyecto.
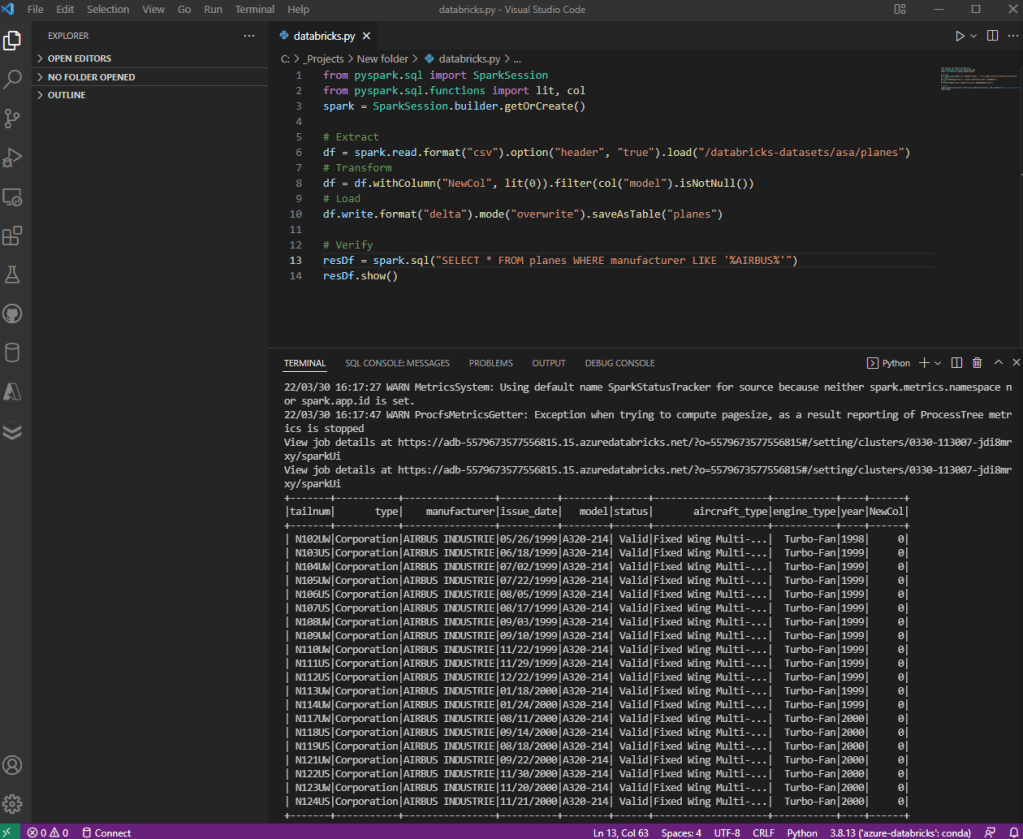
CONCLUSIÓN
¿Qué más hacer ahora? Pues como he comentado al principio de la entrada, la idea principal de utilizar un IDE en el desarrollo de soluciones de datos, es aprovechar al máximo las capacidades que nos ofrecen, estructurando el proyecto, conectando con el repositorio de código, desarrollando test unitarios,…
Los datos son el nuevo petróleo, no paramos de escuchar esta frase, y no es falsa. Realmente sin medir es muy complicado definir estrategias eficientes de mejora, con lo que sin saber ejecutar proyectos de datos, te estás condenando como organización a no completar con éxito la carrera o con suerte a llegar a la meta, pero con un tiempo no demasiado bueno. Pon punto y final a eso dotando a tu equipo de datos de directrices claras y herramientas que les permitan comprender la importancia de su puesta en uso. No es un capricho, es la base para que las cosas empiecen a sustentarse correctamente. Después de ésto, vienen aspectos como la modernización, integración y automatización. ¡Vayamos paso a paso!
Incrementa el nivel de calidad de tus proyectos de datos incorporando un framework de buenas prácticas.
Foto de portada gracias a RUN 4 FFWPU en Pexels

Un comentario en “DataOps con VS Code y Azure Databricks”